 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAbigail Langbridge
Optimal Transport for Fairness: Archival Data Repair using Small Research Data Sets
Mar 20, 2024
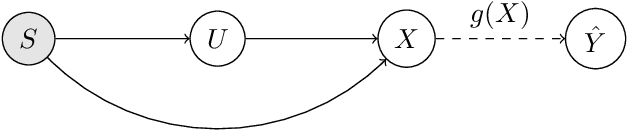

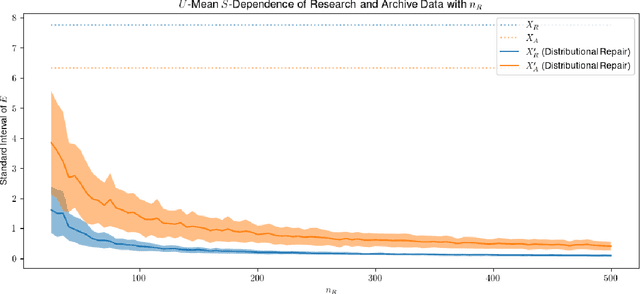
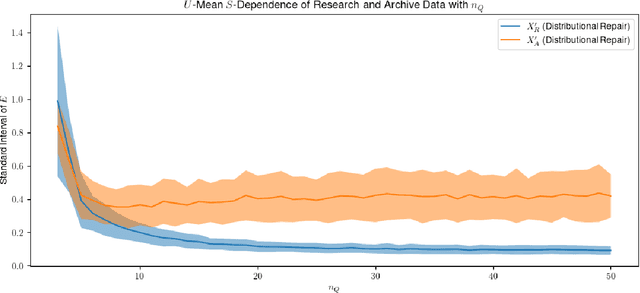
With the advent of the AI Act and other regulations, there is now an urgent need for algorithms that repair unfairness in training data. In this paper, we define fairness in terms of conditional independence between protected attributes ($S$) and features ($X$), given unprotected attributes ($U$). We address the important setting in which torrents of archival data need to be repaired, using only a small proportion of these data, which are $S|U$-labelled (the research data). We use the latter to design optimal transport (OT)-based repair plans on interpolated supports. This allows {\em off-sample}, labelled, archival data to be repaired, subject to stationarity assumptions. It also significantly reduces the size of the supports of the OT plans, with correspondingly large savings in the cost of their design and of their {\em sequential\/} application to the off-sample data. We provide detailed experimental results with simulated and benchmark real data (the Adult data set). Our performance figures demonstrate effective repair -- in the sense of quenching conditional dependence -- of large quantities of off-sample, labelled (archival) data.
Causal Temporal Graph Convolutional Neural Networks (CTGCN)
Mar 16, 2023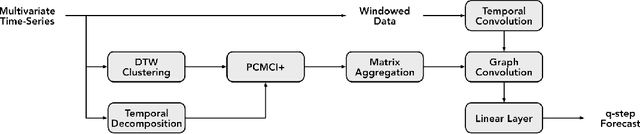
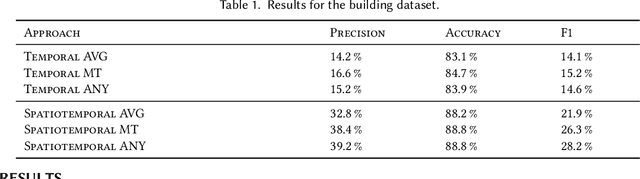
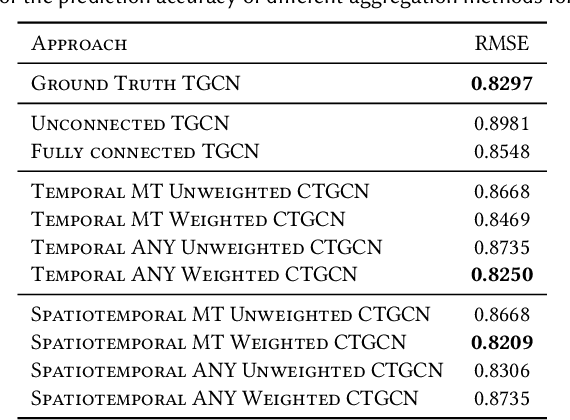
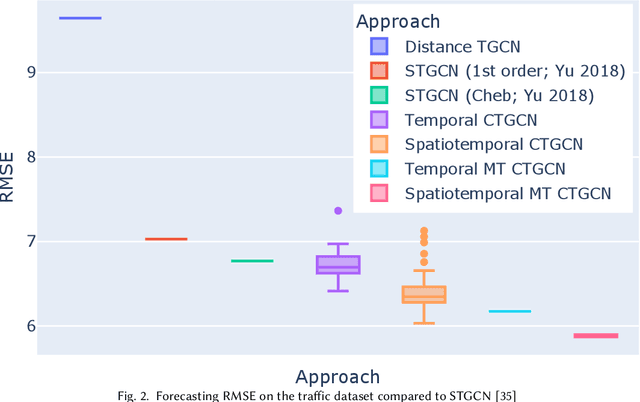
Many large-scale applications can be elegantly represented using graph structures. Their scalability, however, is often limited by the domain knowledge required to apply them. To address this problem, we propose a novel Causal Temporal Graph Convolutional Neural Network (CTGCN). Our CTGCN architecture is based on a causal discovery mechanism, and is capable of discovering the underlying causal processes. The major advantages of our approach stem from its ability to overcome computational scalability problems with a divide and conquer technique, and from the greater explainability of predictions made using a causal model. We evaluate the scalability of our CTGCN on two datasets to demonstrate that our method is applicable to large scale problems, and show that the integration of causality into the TGCN architecture improves prediction performance up to 40% over typical TGCN approach. Our results are obtained without requiring additional domain knowledge, making our approach adaptable to various domains, specifically when little contextual knowledge is available.