 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdam Prugel-Bennett
Linear Disentangled Representations and Unsupervised Action Estimation
Aug 18, 2020


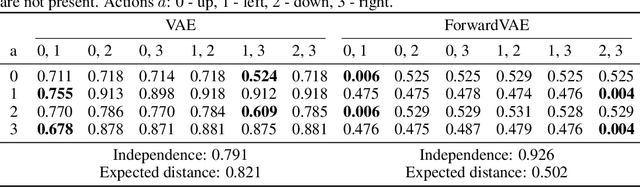

Disentangled representation learning has seen a surge in interest over recent times, generally focusing on new models to optimise one of many disparate disentanglement metrics. It was only with Symmetry Based Disentangled Representation Learning that a robust mathematical framework was introduced to define precisely what is meant by a "linear disentangled representation". This framework determines that such representations would depend on a particular decomposition of the symmetry group acting on the data, showing that actions would manifest through irreducible group representations acting on independent representational subspaces. ForwardVAE subsequently proposed the first model to induce and demonstrate a linear disentangled representation in a VAE model. In this work we empirically show that linear disentangled representations are not present in standard VAE models and that they instead require altering the loss landscape to induce them. We proceed to show that such representations are a desirable property with regard to classical disentanglement metrics. Finally we propose a method to induce irreducible representations which forgoes the need for labelled action sequences, as was required by prior work. We explore a number of properties of this method, including the ability to learn from action sequences without knowledge of intermediate states.
Extended Formulations for Online Linear Bandit Optimization
Sep 30, 2015
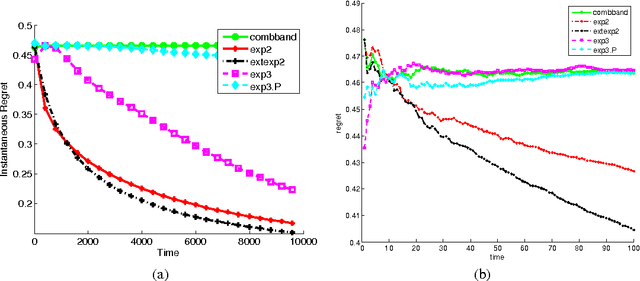
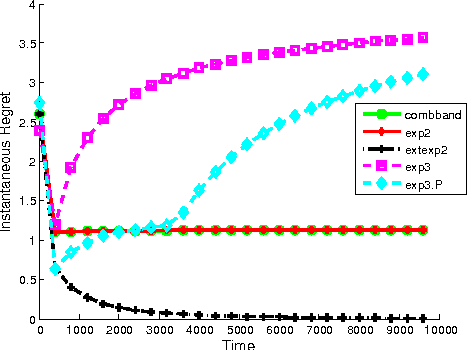
On-line linear optimization on combinatorial action sets (d-dimensional actions) with bandit feedback, is known to have complexity in the order of the dimension of the problem. The exponential weighted strategy achieves the best known regret bound that is of the order of $d^{2}\sqrt{n}$ (where $d$ is the dimension of the problem, $n$ is the time horizon). However, such strategies are provably suboptimal or computationally inefficient. The complexity is attributed to the combinatorial structure of the action set and the dearth of efficient exploration strategies of the set. Mirror descent with entropic regularization function comes close to solving this problem by enforcing a meticulous projection of weights with an inherent boundary condition. Entropic regularization in mirror descent is the only known way of achieving a logarithmic dependence on the dimension. Here, we argue otherwise and recover the original intuition of exponential weighting by borrowing a technique from discrete optimization and approximation algorithms called `extended formulation'. Such formulations appeal to the underlying geometry of the set with a guaranteed logarithmic dependence on the dimension underpinned by an information theoretic entropic analysis.