 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdityanarayanan Radhakrishnan
Linear Recursive Feature Machines provably recover low-rank matrices
Jan 09, 2024
A fundamental problem in machine learning is to understand how neural networks make accurate predictions, while seemingly bypassing the curse of dimensionality. A possible explanation is that common training algorithms for neural networks implicitly perform dimensionality reduction - a process called feature learning. Recent work posited that the effects of feature learning can be elicited from a classical statistical estimator called the average gradient outer product (AGOP). The authors proposed Recursive Feature Machines (RFMs) as an algorithm that explicitly performs feature learning by alternating between (1) reweighting the feature vectors by the AGOP and (2) learning the prediction function in the transformed space. In this work, we develop the first theoretical guarantees for how RFM performs dimensionality reduction by focusing on the class of overparametrized problems arising in sparse linear regression and low-rank matrix recovery. Specifically, we show that RFM restricted to linear models (lin-RFM) generalizes the well-studied Iteratively Reweighted Least Squares (IRLS) algorithm. Our results shed light on the connection between feature learning in neural networks and classical sparse recovery algorithms. In addition, we provide an implementation of lin-RFM that scales to matrices with millions of missing entries. Our implementation is faster than the standard IRLS algorithm as it is SVD-free. It also outperforms deep linear networks for sparse linear regression and low-rank matrix completion.
Mechanism of feature learning in convolutional neural networks
Sep 01, 2023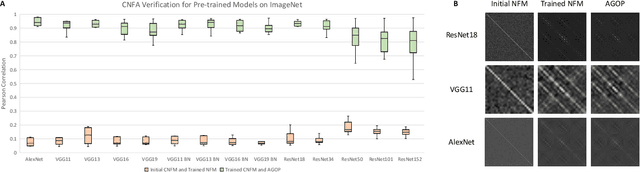



Understanding the mechanism of how convolutional neural networks learn features from image data is a fundamental problem in machine learning and computer vision. In this work, we identify such a mechanism. We posit the Convolutional Neural Feature Ansatz, which states that covariances of filters in any convolutional layer are proportional to the average gradient outer product (AGOP) taken with respect to patches of the input to that layer. We present extensive empirical evidence for our ansatz, including identifying high correlation between covariances of filters and patch-based AGOPs for convolutional layers in standard neural architectures, such as AlexNet, VGG, and ResNets pre-trained on ImageNet. We also provide supporting theoretical evidence. We then demonstrate the generality of our result by using the patch-based AGOP to enable deep feature learning in convolutional kernel machines. We refer to the resulting algorithm as (Deep) ConvRFM and show that our algorithm recovers similar features to deep convolutional networks including the notable emergence of edge detectors. Moreover, we find that Deep ConvRFM overcomes previously identified limitations of convolutional kernels, such as their inability to adapt to local signals in images and, as a result, leads to sizable performance improvement over fixed convolutional kernels.
Catapults in SGD: spikes in the training loss and their impact on generalization through feature learning
Jun 07, 2023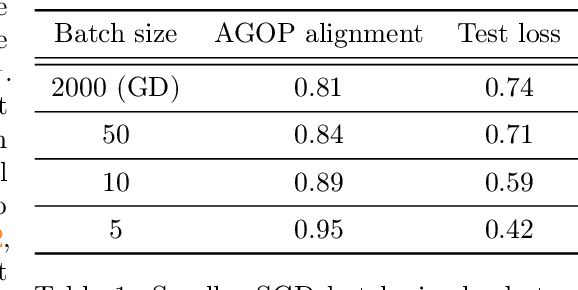
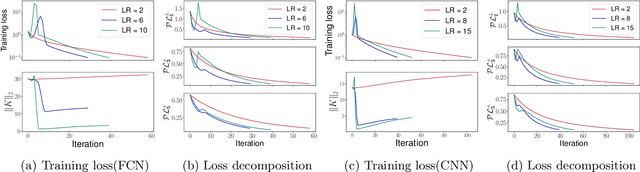
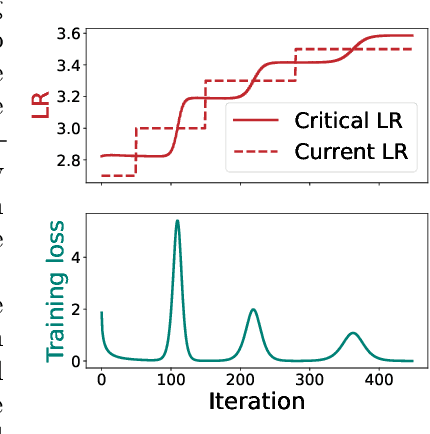
In this paper, we first present an explanation regarding the common occurrence of spikes in the training loss when neural networks are trained with stochastic gradient descent (SGD). We provide evidence that the spikes in the training loss of SGD are "catapults", an optimization phenomenon originally observed in GD with large learning rates in [Lewkowycz et al. 2020]. We empirically show that these catapults occur in a low-dimensional subspace spanned by the top eigenvectors of the tangent kernel, for both GD and SGD. Second, we posit an explanation for how catapults lead to better generalization by demonstrating that catapults promote feature learning by increasing alignment with the Average Gradient Outer Product (AGOP) of the true predictor. Furthermore, we demonstrate that a smaller batch size in SGD induces a larger number of catapults, thereby improving AGOP alignment and test performance.
Feature learning in neural networks and kernel machines that recursively learn features
Dec 28, 2022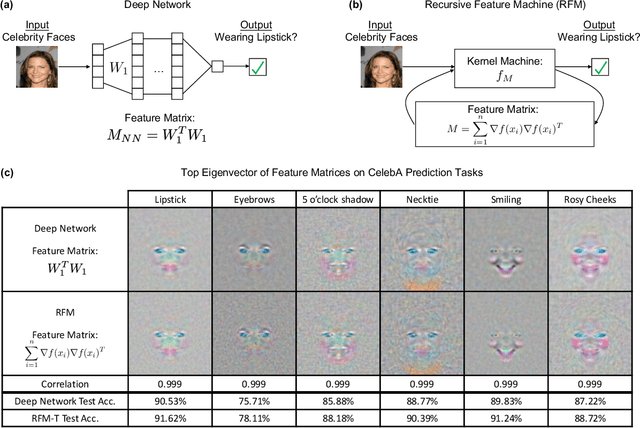
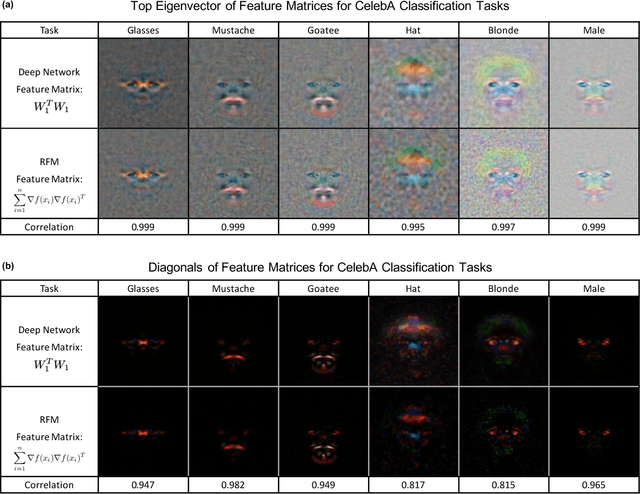
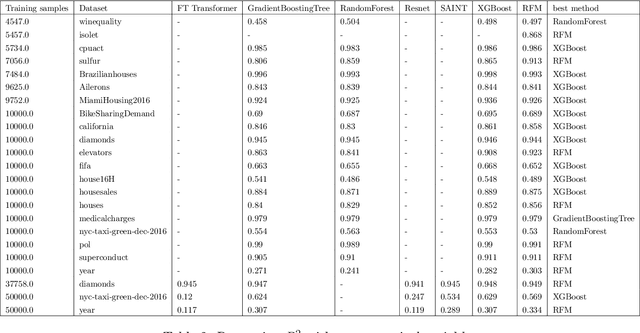
Neural networks have achieved impressive results on many technological and scientific tasks. Yet, their empirical successes have outpaced our fundamental understanding of their structure and function. By identifying mechanisms driving the successes of neural networks, we can provide principled approaches for improving neural network performance and develop simple and effective alternatives. In this work, we isolate the key mechanism driving feature learning in fully connected neural networks by connecting neural feature learning to the average gradient outer product. We subsequently leverage this mechanism to design \textit{Recursive Feature Machines} (RFMs), which are kernel machines that learn features. We show that RFMs (1) accurately capture features learned by deep fully connected neural networks, (2) close the gap between kernel machines and fully connected networks, and (3) surpass a broad spectrum of models including neural networks on tabular data. Furthermore, we demonstrate that RFMs shed light on recently observed deep learning phenomena such as grokking, lottery tickets, simplicity biases, and spurious features. We provide a Python implementation to make our method broadly accessible [\href{https://github.com/aradha/recursive_feature_machines}{GitHub}].
Transfer Learning with Kernel Methods
Nov 01, 2022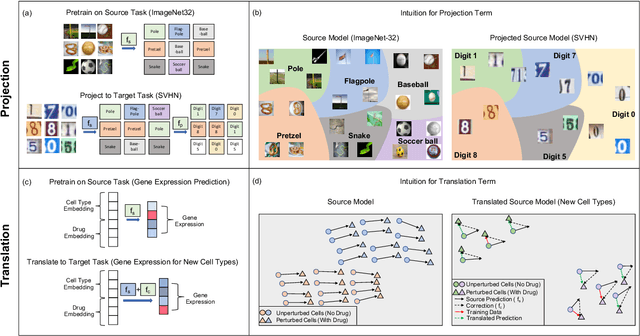

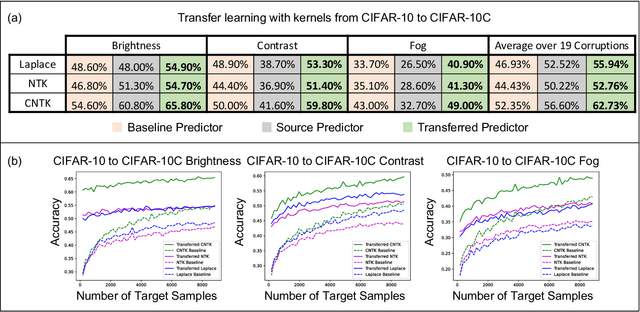
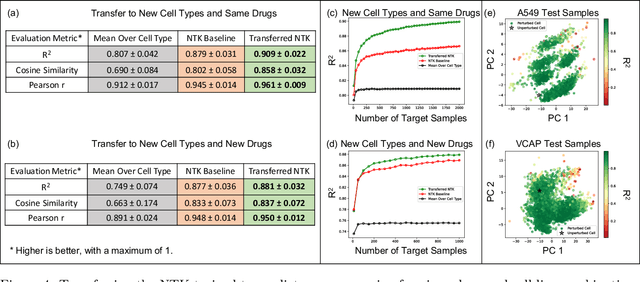
Transfer learning refers to the process of adapting a model trained on a source task to a target task. While kernel methods are conceptually and computationally simple machine learning models that are competitive on a variety of tasks, it has been unclear how to perform transfer learning for kernel methods. In this work, we propose a transfer learning framework for kernel methods by projecting and translating the source model to the target task. We demonstrate the effectiveness of our framework in applications to image classification and virtual drug screening. In particular, we show that transferring modern kernels trained on large-scale image datasets can result in substantial performance increase as compared to using the same kernel trained directly on the target task. In addition, we show that transfer-learned kernels allow a more accurate prediction of the effect of drugs on cancer cell lines. For both applications, we identify simple scaling laws that characterize the performance of transfer-learned kernels as a function of the number of target examples. We explain this phenomenon in a simplified linear setting, where we are able to derive the exact scaling laws. By providing a simple and effective transfer learning framework for kernel methods, our work enables kernel methods trained on large datasets to be easily adapted to a variety of downstream target tasks.
Quadratic models for understanding neural network dynamics
May 24, 2022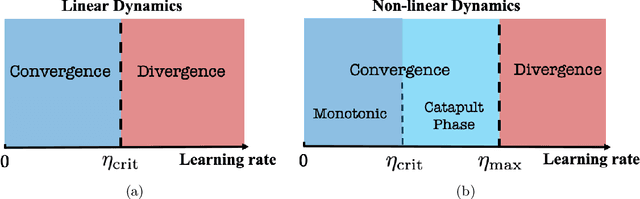
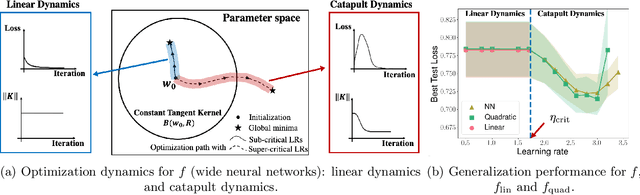
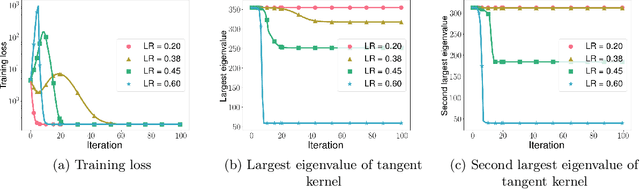
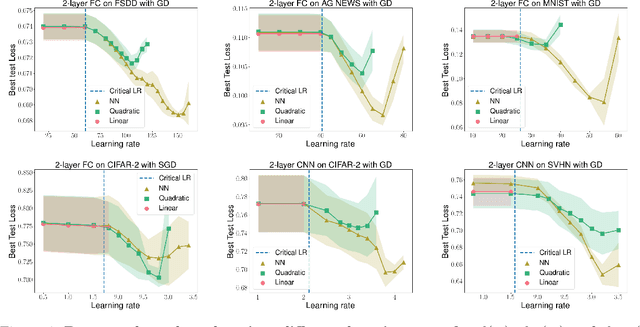
In this work, we propose using a quadratic model as a tool for understanding properties of wide neural networks in both optimization and generalization. We show analytically that certain deep learning phenomena such as the "catapult phase" from [Lewkowycz et al. 2020], which cannot be captured by linear models, are manifested in the quadratic model for shallow ReLU networks. Furthermore, our empirical results indicate that the behaviour of quadratic models parallels that of neural networks in generalization, especially in the large learning rate regime. We expect that quadratic models will serve as a useful tool for analysis of neural networks.
Wide and Deep Neural Networks Achieve Optimality for Classification
Apr 29, 2022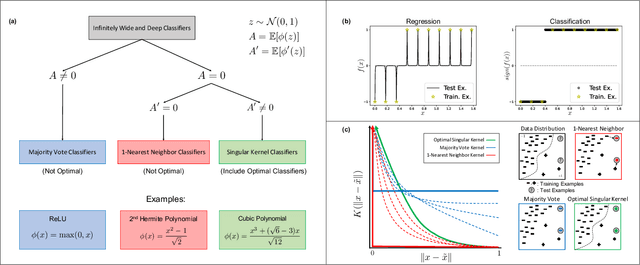
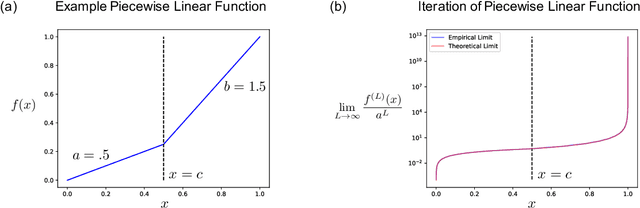
While neural networks are used for classification tasks across domains, a long-standing open problem in machine learning is determining whether neural networks trained using standard procedures are optimal for classification, i.e., whether such models minimize the probability of misclassification for arbitrary data distributions. In this work, we identify and construct an explicit set of neural network classifiers that achieve optimality. Since effective neural networks in practice are typically both wide and deep, we analyze infinitely wide networks that are also infinitely deep. In particular, using the recent connection between infinitely wide neural networks and Neural Tangent Kernels, we provide explicit activation functions that can be used to construct networks that achieve optimality. Interestingly, these activation functions are simple and easy to implement, yet differ from commonly used activations such as ReLU or sigmoid. More generally, we create a taxonomy of infinitely wide and deep networks and show that these models implement one of three well-known classifiers depending on the activation function used: (1) 1-nearest neighbor (model predictions are given by the label of the nearest training example); (2) majority vote (model predictions are given by the label of the class with greatest representation in the training set); or (3) singular kernel classifiers (a set of classifiers containing those that achieve optimality). Our results highlight the benefit of using deep networks for classification tasks, in contrast to regression tasks, where excessive depth is harmful.
Local Quadratic Convergence of Stochastic Gradient Descent with Adaptive Step Size
Dec 30, 2021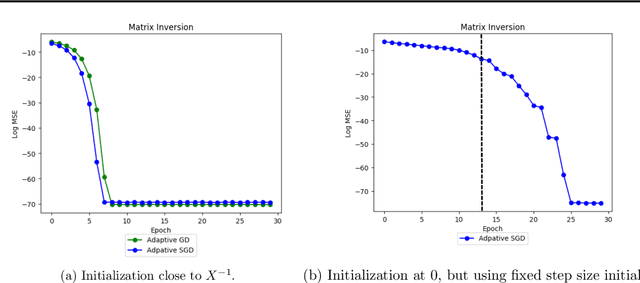
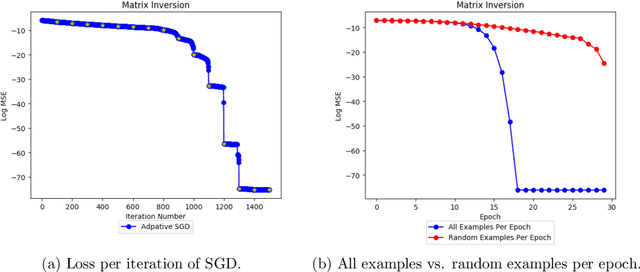
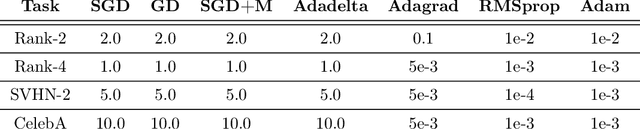
Establishing a fast rate of convergence for optimization methods is crucial to their applicability in practice. With the increasing popularity of deep learning over the past decade, stochastic gradient descent and its adaptive variants (e.g. Adagrad, Adam, etc.) have become prominent methods of choice for machine learning practitioners. While a large number of works have demonstrated that these first order optimization methods can achieve sub-linear or linear convergence, we establish local quadratic convergence for stochastic gradient descent with adaptive step size for problems such as matrix inversion.
Simple, Fast, and Flexible Framework for Matrix Completion with Infinite Width Neural Networks
Jul 31, 2021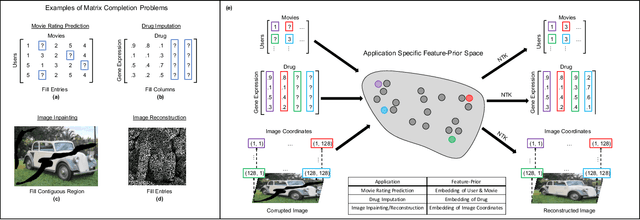
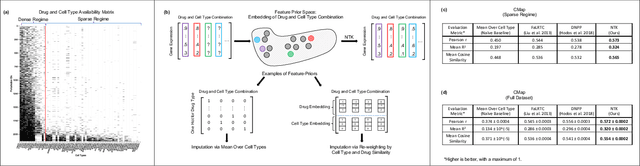

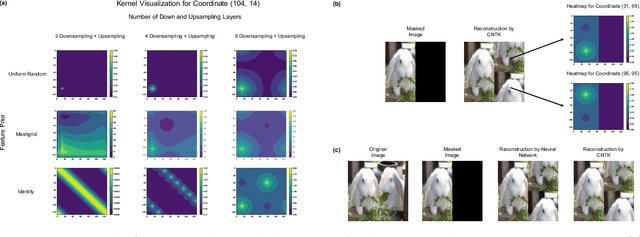
Matrix completion problems arise in many applications including recommendation systems, computer vision, and genomics. Increasingly larger neural networks have been successful in many of these applications, but at considerable computational costs. Remarkably, taking the width of a neural network to infinity allows for improved computational performance. In this work, we develop an infinite width neural network framework for matrix completion that is simple, fast, and flexible. Simplicity and speed come from the connection between the infinite width limit of neural networks and kernels known as neural tangent kernels (NTK). In particular, we derive the NTK for fully connected and convolutional neural networks for matrix completion. The flexibility stems from a feature prior, which allows encoding relationships between coordinates of the target matrix, akin to semi-supervised learning. The effectiveness of our framework is demonstrated through competitive results for virtual drug screening and image inpainting/reconstruction. We also provide an implementation in Python to make our framework accessible on standard hardware to a broad audience.
A Mechanism for Producing Aligned Latent Spaces with Autoencoders
Jun 29, 2021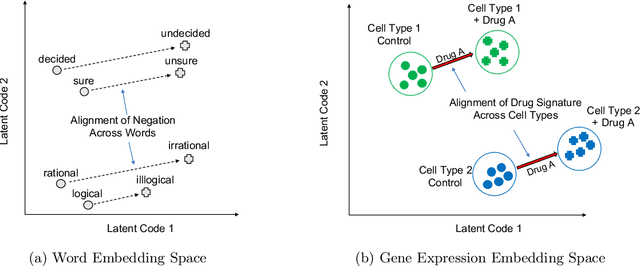
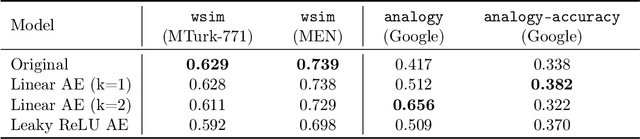
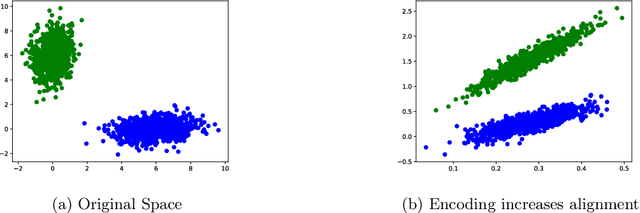
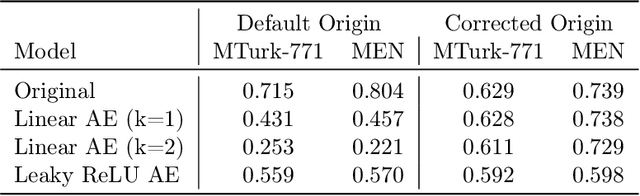
Aligned latent spaces, where meaningful semantic shifts in the input space correspond to a translation in the embedding space, play an important role in the success of downstream tasks such as unsupervised clustering and data imputation. In this work, we prove that linear and nonlinear autoencoders produce aligned latent spaces by stretching along the left singular vectors of the data. We fully characterize the amount of stretching in linear autoencoders and provide an initialization scheme to arbitrarily stretch along the top directions using these networks. We also quantify the amount of stretching in nonlinear autoencoders in a simplified setting. We use our theoretical results to align drug signatures across cell types in gene expression space and semantic shifts in word embedding spaces.