 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdvait Sarkar
Solving Data-centric Tasks using Large Language Models
Feb 18, 2024
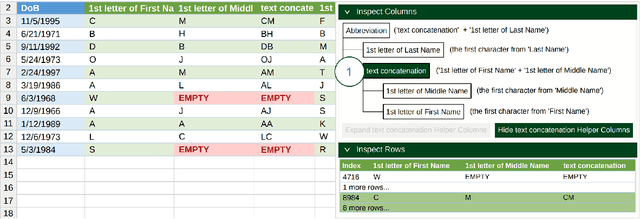
Large language models (LLMs) are rapidly replacing help forums like StackOverflow, and are especially helpful for non-professional programmers and end users. These users are often interested in data-centric tasks, such as spreadsheet manipulation and data wrangling, which are hard to solve if the intent is only communicated using a natural-language description, without including the data. But how do we decide how much data and which data to include in the prompt? This paper makes two contributions towards answering this question. First, we create a dataset of real-world NL-to-code tasks manipulating tabular data, mined from StackOverflow posts. Second, we introduce a cluster-then-select prompting technique, which adds the most representative rows from the input data to the LLM prompt. Our experiments show that LLM performance is indeed sensitive to the amount of data passed in the prompt, and that for tasks with a lot of syntactic variation in the input table, our cluster-then-select technique outperforms a random selection baseline.
Will Code Remain a Relevant User Interface for End-User Programming with Generative AI Models?
Nov 01, 2023The research field of end-user programming has largely been concerned with helping non-experts learn to code sufficiently well in order to achieve their tasks. Generative AI stands to obviate this entirely by allowing users to generate code from naturalistic language prompts. In this essay, we explore the extent to which "traditional" programming languages remain relevant for non-expert end-user programmers in a world with generative AI. We posit the "generative shift hypothesis": that generative AI will create qualitative and quantitative expansions in the traditional scope of end-user programming. We outline some reasons that traditional programming languages may still be relevant and useful for end-user programmers. We speculate whether each of these reasons might be fundamental and enduring, or whether they may disappear with further improvements and innovations in generative AI. Finally, we articulate a set of implications for end-user programming research, including the possibility of needing to revisit many well-established core concepts, such as Ko's learning barriers and Blackwell's attention investment model.
* Advait Sarkar. 2023. "Will Code Remain a Relevant User Interface for End-User Programming with Generative AI Models?" In Proceedings of the 2023 ACM SIGPLAN International Symposium on New Ideas, New Paradigms, and Reflections on Programming and Software (Onward! '23)
Co-audit: tools to help humans double-check AI-generated content
Oct 02, 2023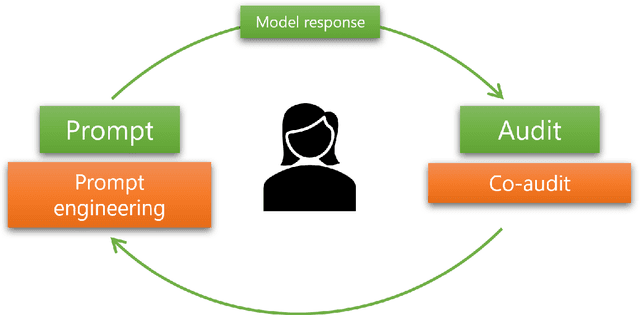

Users are increasingly being warned to check AI-generated content for correctness. Still, as LLMs (and other generative models) generate more complex output, such as summaries, tables, or code, it becomes harder for the user to audit or evaluate the output for quality or correctness. Hence, we are seeing the emergence of tool-assisted experiences to help the user double-check a piece of AI-generated content. We refer to these as co-audit tools. Co-audit tools complement prompt engineering techniques: one helps the user construct the input prompt, while the other helps them check the output response. As a specific example, this paper describes recent research on co-audit tools for spreadsheet computations powered by generative models. We explain why co-audit experiences are essential for any application of generative AI where quality is important and errors are consequential (as is common in spreadsheet computations). We propose a preliminary list of principles for co-audit, and outline research challenges.
Exploring Perspectives on the Impact of Artificial Intelligence on the Creativity of Knowledge Work: Beyond Mechanised Plagiarism and Stochastic Parrots
Jul 20, 2023Artificial Intelligence (AI), and in particular generative models, are transformative tools for knowledge work. They problematise notions of creativity, originality, plagiarism, the attribution of credit, and copyright ownership. Critics of generative models emphasise the reliance on large amounts of training data, and view the output of these models as no more than randomised plagiarism, remix, or collage of the source data. On these grounds, many have argued for stronger regulations on the deployment, use, and attribution of the output of these models. However, these issues are not new or unique to artificial intelligence. In this position paper, using examples from literary criticism, the history of art, and copyright law, I show how creativity and originality resist definition as a notatable or information-theoretic property of an object, and instead can be seen as the property of a process, an author, or a viewer. Further alternative views hold that all creative work is essentially reuse (mostly without attribution), or that randomness itself can be creative. I suggest that creativity is ultimately defined by communities of creators and receivers, and the deemed sources of creativity in a workflow often depend on which parts of the workflow can be automated. Using examples from recent studies of AI in creative knowledge work, I suggest that AI shifts knowledge work from material production to critical integration. This position paper aims to begin a conversation around a more nuanced approach to the problems of creativity and credit assignment for generative models, one which more fully recognises the importance of the creative and curatorial voice of the users of these models and moves away from simpler notational or information-theoretic views.
What is it like to program with artificial intelligence?
Aug 12, 2022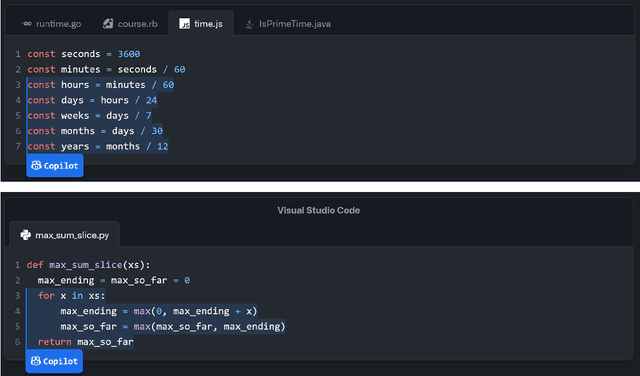
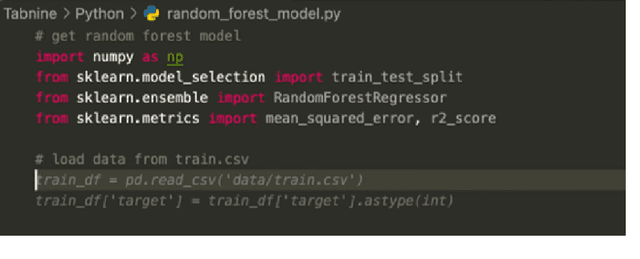
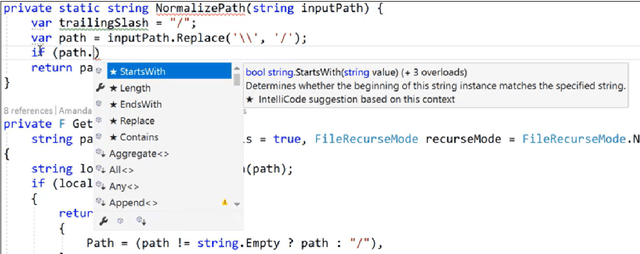
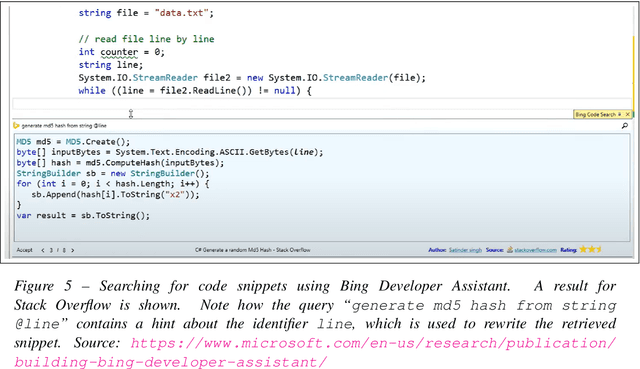
Large language models, such as OpenAI's codex and Deepmind's AlphaCode, can generate code to solve a variety of problems expressed in natural language. This technology has already been commercialised in at least one widely-used programming editor extension: GitHub Copilot. In this paper, we explore how programming with large language models (LLM-assisted programming) is similar to, and differs from, prior conceptualisations of programmer assistance. We draw upon publicly available experience reports of LLM-assisted programming, as well as prior usability and design studies. We find that while LLM-assisted programming shares some properties of compilation, pair programming, and programming via search and reuse, there are fundamental differences both in the technical possibilities as well as the practical experience. Thus, LLM-assisted programming ought to be viewed as a new way of programming with its own distinct properties and challenges. Finally, we draw upon observations from a user study in which non-expert end user programmers use LLM-assisted tools for solving data tasks in spreadsheets. We discuss the issues that might arise, and open research challenges, in applying large language models to end-user programming, particularly with users who have little or no programming expertise.
Is explainable AI a race against model complexity?
May 17, 2022Explaining the behaviour of intelligent systems will get increasingly and perhaps intractably challenging as models grow in size and complexity. We may not be able to expect an explanation for every prediction made by a brain-scale model, nor can we expect explanations to remain objective or apolitical. Our functionalist understanding of these models is of less advantage than we might assume. Models precede explanations, and can be useful even when both model and explanation are incorrect. Explainability may never win the race against complexity, but this is less problematic than it seems.