 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAhmed H. Tewfik
Deep J-Sense: Accelerated MRI Reconstruction via Unrolled Alternating Optimization
Apr 01, 2021
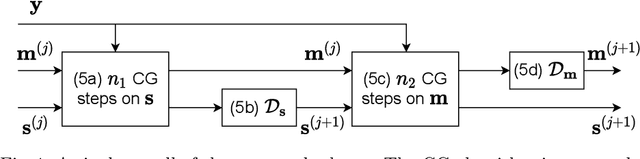

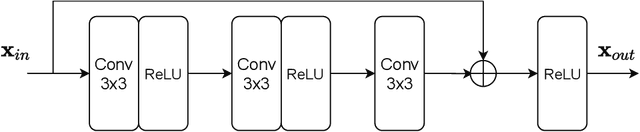
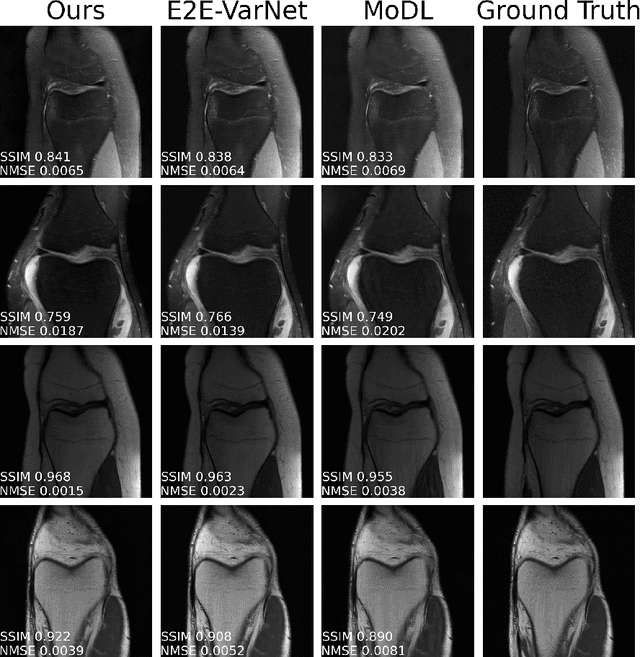
Accelerated multi-coil magnetic resonance imaging reconstruction has seen a substantial recent improvement combining compressed sensing with deep learning. However, most of these methods rely on estimates of the coil sensitivity profiles, or on calibration data for estimating model parameters. Prior work has shown that these methods degrade in performance when the quality of these estimators are poor or when the scan parameters differ from the training conditions. Here we introduce Deep J-Sense as a deep learning approach that builds on unrolled alternating minimization and increases robustness: our algorithm refines both the magnetization (image) kernel and the coil sensitivity maps. Experimental results on a subset of the knee fastMRI dataset show that this increases reconstruction performance and provides a significant degree of robustness to varying acceleration factors and calibration region sizes.
EQ-Net: A Unified Deep Learning Framework for Log-Likelihood Ratio Estimation and Quantization
Dec 23, 2020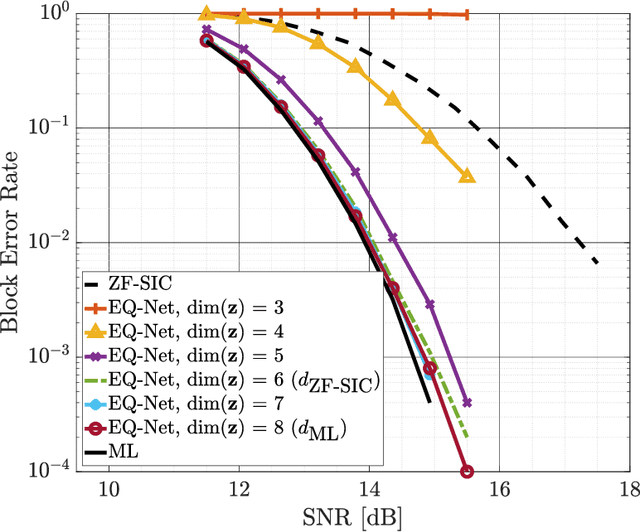
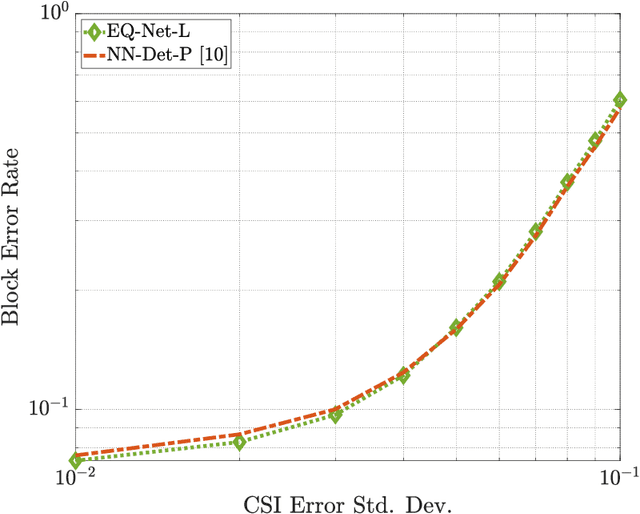
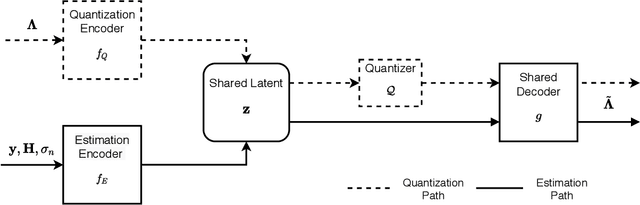
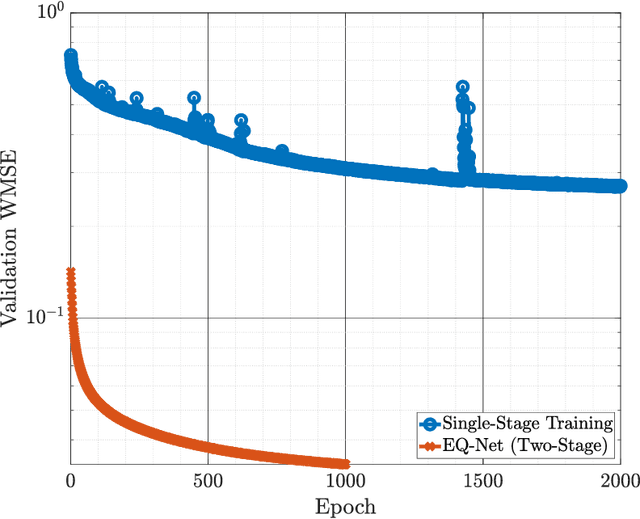
In this work, we introduce EQ-Net: the first holistic framework that solves both the tasks of log-likelihood ratio (LLR) estimation and quantization using a data-driven method. We motivate our approach with theoretical insights on two practical estimation algorithms at the ends of the complexity spectrum and reveal a connection between the complexity of an algorithm and the information bottleneck method: simpler algorithms admit smaller bottlenecks when representing their solution. This motivates us to propose a two-stage algorithm that uses LLR compression as a pretext task for estimation and is focused on low-latency, high-performance implementations via deep neural networks. We carry out extensive experimental evaluation and demonstrate that our single architecture achieves state-of-the-art results on both tasks when compared to previous methods, with gains in quantization efficiency as high as $20\%$ and reduced estimation latency by up to $60\%$ when measured on general purpose and graphical processing units (GPU). In particular, our approach reduces the GPU inference latency by more than two times in several multiple-input multiple-output (MIMO) configurations. Finally, we demonstrate that our scheme is robust to distributional shifts and retains a significant part of its performance when evaluated on 5G channel models, as well as channel estimation errors.
Robust Face Verification via Disentangled Representations
Jun 23, 2020
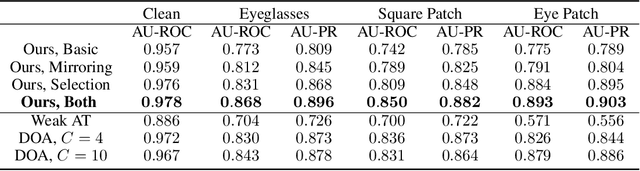
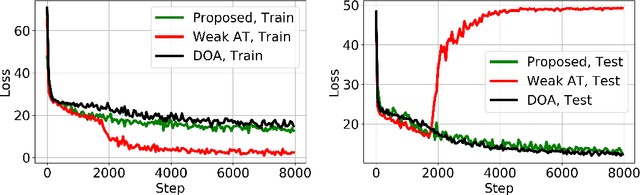
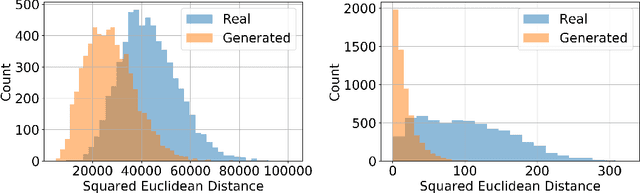
We introduce a robust algorithm for face verification, i.e., deciding whether twoimages are of the same person or not. Our approach is a novel take on the idea ofusing deep generative networks for adversarial robustness. We use the generativemodel during training as an online augmentation method instead of a test-timepurifier that removes adversarial noise. Our architecture uses a contrastive loss termand a disentangled generative model to sample negative pairs. Instead of randomlypairing two real images, we pair an image with its class-modified counterpart whilekeeping its content (pose, head tilt, hair, etc.) intact. This enables us to efficientlysample hard negative pairs for the contrastive loss. We experimentally show that, when coupled with adversarial training, the proposed scheme converges with aweak inner solver and has a higher clean and robust accuracy than state-of-the-art-methods when evaluated against white-box physical attacks.
Deep Learning-Based Quantization of L-Values for Gray-Coded Modulation
Jun 18, 2019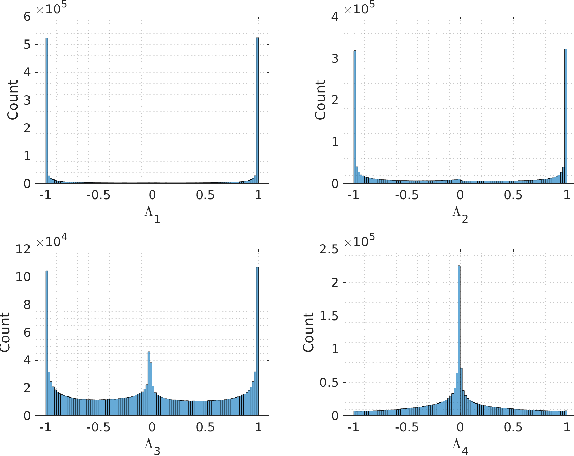
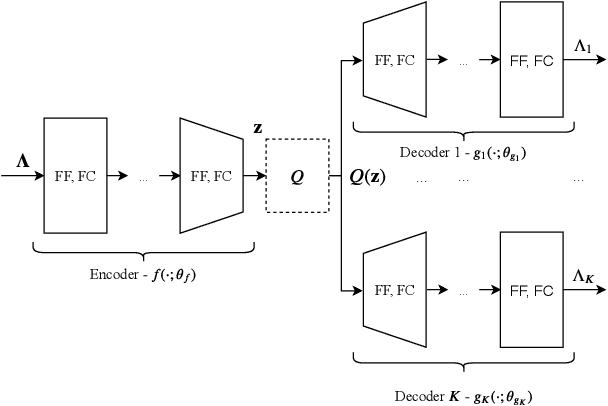
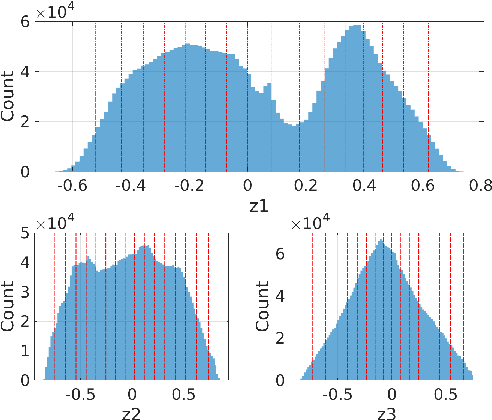
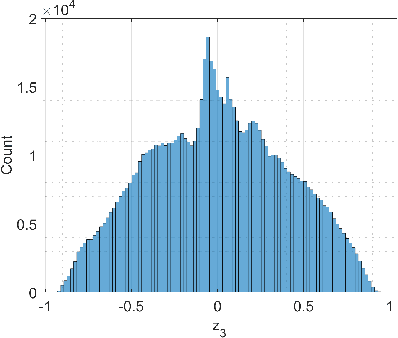
In this work, a deep learning-based quantization scheme for log-likelihood ratio (L-value) storage is introduced. We analyze the dependency between the average magnitude of different L-values from the same quadrature amplitude modulation (QAM) symbol and show they follow a consistent ordering. Based on this we design a deep autoencoder that jointly compresses and separately reconstructs each L-value, allowing the use of a weighted loss function that aims to more accurately reconstructs low magnitude inputs. Our method is shown to be competitive with state-of-the-art maximum mutual information quantization schemes, reducing the required memory footprint by a ratio of up to two and a loss of performance smaller than 0.1 dB with less than two effective bits per L-value or smaller than 0.04 dB with 2.25 effective bits. We experimentally show that our proposed method is a universal compression scheme in the sense that after training on an LDPC-coded Rayleigh fading scenario we can reuse the same network without further training on other channel models and codes while preserving the same performance benefits.
Deep Log-Likelihood Ratio Quantization
Mar 11, 2019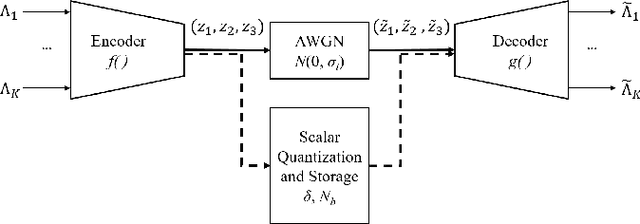
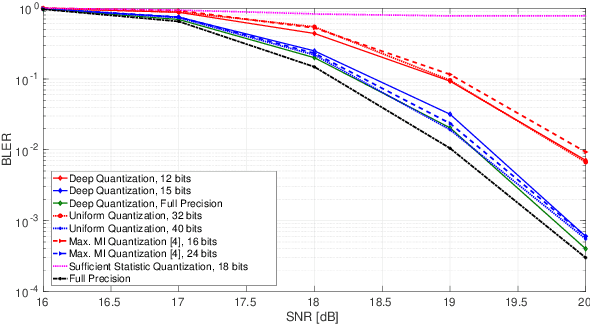
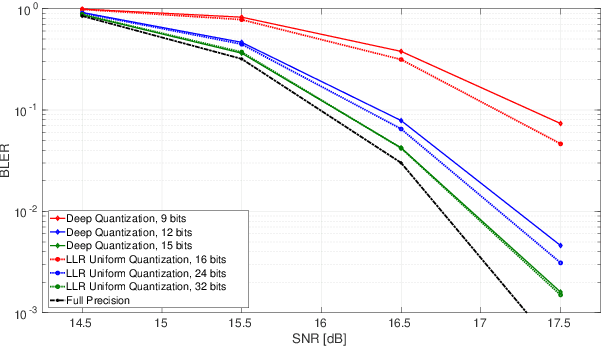
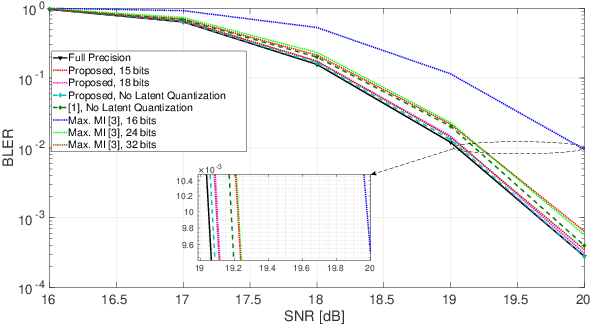
In this work, a deep learning-based method for log-likelihood ratio (LLR) lossy compression and quantization is proposed, with emphasis on a single-input single-output uncorrelated fading communication setting. A deep autoencoder network is trained to compress, quantize and reconstruct the bit log-likelihood ratios corresponding to a single transmitted symbol. Specifically, the encoder maps to a latent space with dimension equal to the number of sufficient statistics required to recover the inputs - equal to three in this case - while the decoder aims to reconstruct a noisy version of the latent representation with the purpose of modeling quantization effects in a differentiable way. Simulation results show that, when applied to a standard rate-1/2 low-density parity-check (LDPC) code, a finite precision compression factor of nearly three times is achieved when storing an entire codeword, with an incurred loss of performance lower than 0.1 dB compared to straightforward scalar quantization of the log-likelihood ratios.