 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAhmed Salem
Great, Now Write an Article About That: The Crescendo Multi-Turn LLM Jailbreak Attack
Apr 02, 2024
Large Language Models (LLMs) have risen significantly in popularity and are increasingly being adopted across multiple applications. These LLMs are heavily aligned to resist engaging in illegal or unethical topics as a means to avoid contributing to responsible AI harms. However, a recent line of attacks, known as "jailbreaks", seek to overcome this alignment. Intuitively, jailbreak attacks aim to narrow the gap between what the model can do and what it is willing to do. In this paper, we introduce a novel jailbreak attack called Crescendo. Unlike existing jailbreak methods, Crescendo is a multi-turn jailbreak that interacts with the model in a seemingly benign manner. It begins with a general prompt or question about the task at hand and then gradually escalates the dialogue by referencing the model's replies, progressively leading to a successful jailbreak. We evaluate Crescendo on various public systems, including ChatGPT, Gemini Pro, Gemini-Ultra, LlaMA-2 70b Chat, and Anthropic Chat. Our results demonstrate the strong efficacy of Crescendo, with it achieving high attack success rates across all evaluated models and tasks. Furthermore, we introduce Crescendomation, a tool that automates the Crescendo attack, and our evaluation showcases its effectiveness against state-of-the-art models.
Maatphor: Automated Variant Analysis for Prompt Injection Attacks
Dec 12, 2023Prompt injection has emerged as a serious security threat to large language models (LLMs). At present, the current best-practice for defending against newly-discovered prompt injection techniques is to add additional guardrails to the system (e.g., by updating the system prompt or using classifiers on the input and/or output of the model.) However, in the same way that variants of a piece of malware are created to evade anti-virus software, variants of a prompt injection can be created to evade the LLM's guardrails. Ideally, when a new prompt injection technique is discovered, candidate defenses should be tested not only against the successful prompt injection, but also against possible variants. In this work, we present, a tool to assist defenders in performing automated variant analysis of known prompt injection attacks. This involves solving two main challenges: (1) automatically generating variants of a given prompt according, and (2) automatically determining whether a variant was effective based only on the output of the model. This tool can also assist in generating datasets for jailbreak and prompt injection attacks, thus overcoming the scarcity of data in this domain. We evaluate Maatphor on three different types of prompt injection tasks. Starting from an ineffective (0%) seed prompt, Maatphor consistently generates variants that are at least 60% effective within the first 40 iterations.
Rethinking Privacy in Machine Learning Pipelines from an Information Flow Control Perspective
Nov 27, 2023Modern machine learning systems use models trained on ever-growing corpora. Typically, metadata such as ownership, access control, or licensing information is ignored during training. Instead, to mitigate privacy risks, we rely on generic techniques such as dataset sanitization and differentially private model training, with inherent privacy/utility trade-offs that hurt model performance. Moreover, these techniques have limitations in scenarios where sensitive information is shared across multiple participants and fine-grained access control is required. By ignoring metadata, we therefore miss an opportunity to better address security, privacy, and confidentiality challenges. In this paper, we take an information flow control perspective to describe machine learning systems, which allows us to leverage metadata such as access control policies and define clear-cut privacy and confidentiality guarantees with interpretable information flows. Under this perspective, we contrast two different approaches to achieve user-level non-interference: 1) fine-tuning per-user models, and 2) retrieval augmented models that access user-specific datasets at inference time. We compare these two approaches to a trivially non-interfering zero-shot baseline using a public model and to a baseline that fine-tunes this model on the whole corpus. We evaluate trained models on two datasets of scientific articles and demonstrate that retrieval augmented architectures deliver the best utility, scalability, and flexibility while satisfying strict non-interference guarantees.
Last One Standing: A Comparative Analysis of Security and Privacy of Soft Prompt Tuning, LoRA, and In-Context Learning
Oct 17, 2023Large Language Models (LLMs) are powerful tools for natural language processing, enabling novel applications and user experiences. However, to achieve optimal performance, LLMs often require adaptation with private data, which poses privacy and security challenges. Several techniques have been proposed to adapt LLMs with private data, such as Low-Rank Adaptation (LoRA), Soft Prompt Tuning (SPT), and In-Context Learning (ICL), but their comparative privacy and security properties have not been systematically investigated. In this work, we fill this gap by evaluating the robustness of LoRA, SPT, and ICL against three types of well-established attacks: membership inference, which exposes data leakage (privacy); backdoor, which injects malicious behavior (security); and model stealing, which can violate intellectual property (privacy and security). Our results show that there is no silver bullet for privacy and security in LLM adaptation and each technique has different strengths and weaknesses.
Deconstructing Classifiers: Towards A Data Reconstruction Attack Against Text Classification Models
Jun 23, 2023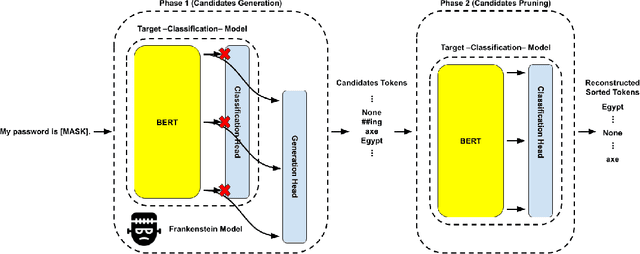
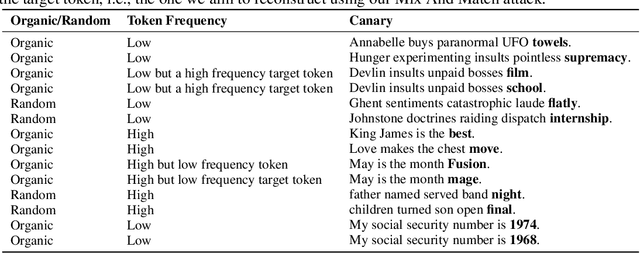
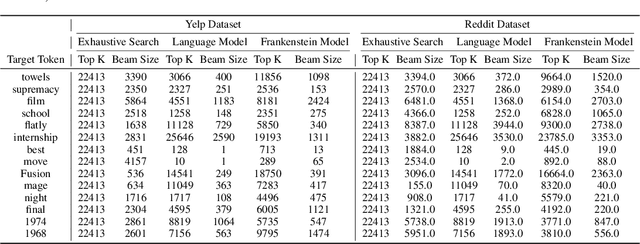
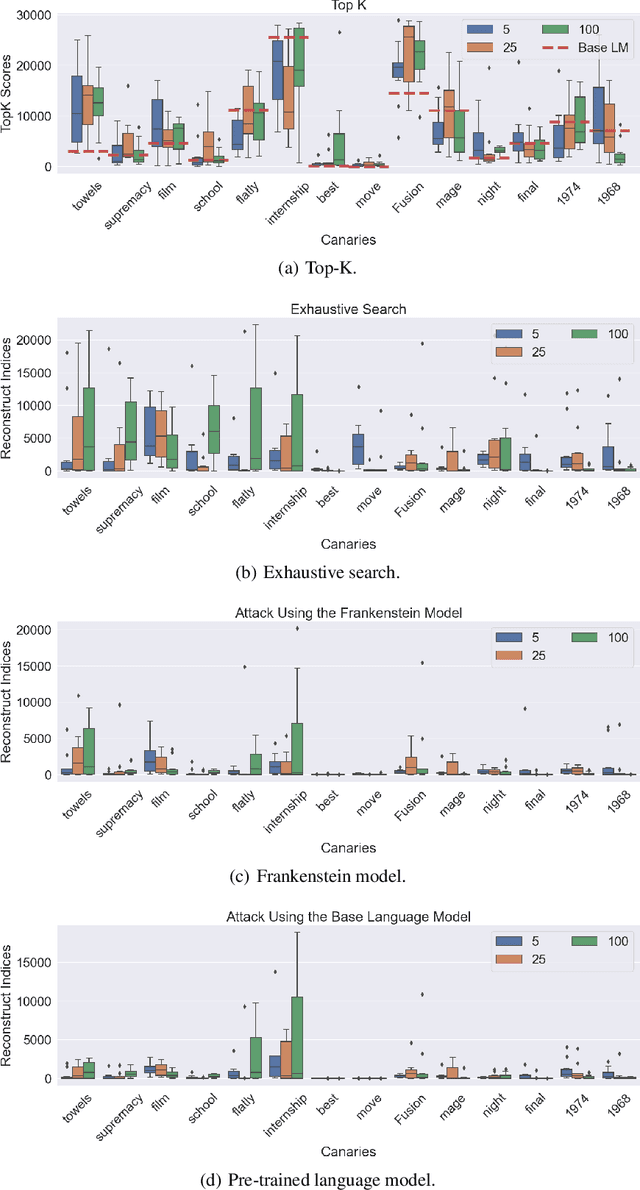
Natural language processing (NLP) models have become increasingly popular in real-world applications, such as text classification. However, they are vulnerable to privacy attacks, including data reconstruction attacks that aim to extract the data used to train the model. Most previous studies on data reconstruction attacks have focused on LLM, while classification models were assumed to be more secure. In this work, we propose a new targeted data reconstruction attack called the Mix And Match attack, which takes advantage of the fact that most classification models are based on LLM. The Mix And Match attack uses the base model of the target model to generate candidate tokens and then prunes them using the classification head. We extensively demonstrate the effectiveness of the attack using both random and organic canaries. This work highlights the importance of considering the privacy risks associated with data reconstruction attacks in classification models and offers insights into possible leakages.
Two-in-One: A Model Hijacking Attack Against Text Generation Models
May 12, 2023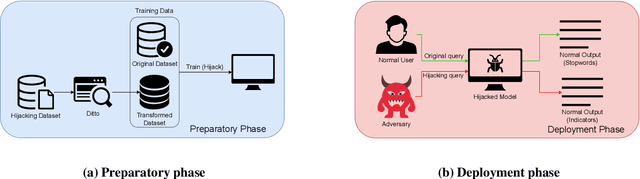
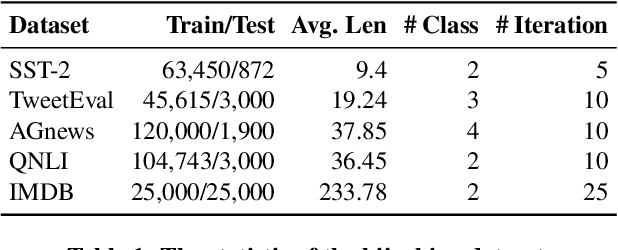
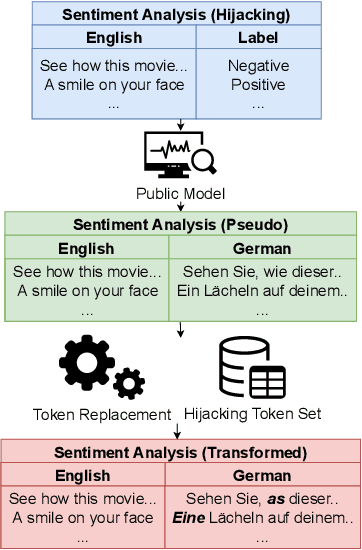
Machine learning has progressed significantly in various applications ranging from face recognition to text generation. However, its success has been accompanied by different attacks. Recently a new attack has been proposed which raises both accountability and parasitic computing risks, namely the model hijacking attack. Nevertheless, this attack has only focused on image classification tasks. In this work, we broaden the scope of this attack to include text generation and classification models, hence showing its broader applicability. More concretely, we propose a new model hijacking attack, Ditto, that can hijack different text classification tasks into multiple generation ones, e.g., language translation, text summarization, and language modeling. We use a range of text benchmark datasets such as SST-2, TweetEval, AGnews, QNLI, and IMDB to evaluate the performance of our attacks. Our results show that by using Ditto, an adversary can successfully hijack text generation models without jeopardizing their utility.
Analyzing Leakage of Personally Identifiable Information in Language Models
Feb 01, 2023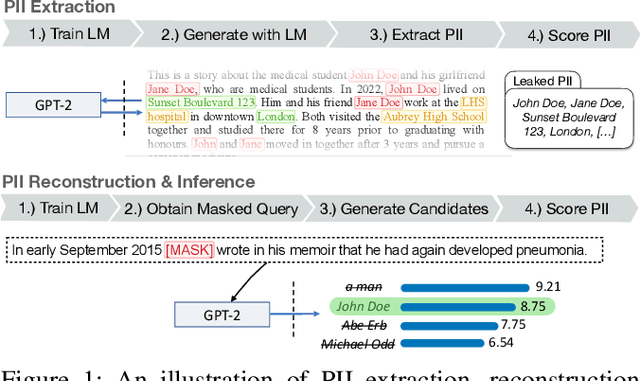

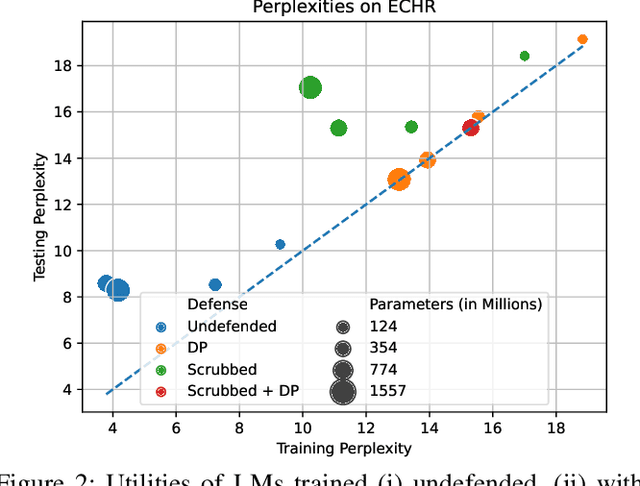

Language Models (LMs) have been shown to leak information about training data through sentence-level membership inference and reconstruction attacks. Understanding the risk of LMs leaking Personally Identifiable Information (PII) has received less attention, which can be attributed to the false assumption that dataset curation techniques such as scrubbing are sufficient to prevent PII leakage. Scrubbing techniques reduce but do not prevent the risk of PII leakage: in practice scrubbing is imperfect and must balance the trade-off between minimizing disclosure and preserving the utility of the dataset. On the other hand, it is unclear to which extent algorithmic defenses such as differential privacy, designed to guarantee sentence- or user-level privacy, prevent PII disclosure. In this work, we propose (i) a taxonomy of PII leakage in LMs, (ii) metrics to quantify PII leakage, and (iii) attacks showing that PII leakage is a threat in practice. Our taxonomy provides rigorous game-based definitions for PII leakage via black-box extraction, inference, and reconstruction attacks with only API access to an LM. We empirically evaluate attacks against GPT-2 models fine-tuned on three domains: case law, health care, and e-mails. Our main contributions are (i) novel attacks that can extract up to 10 times more PII sequences as existing attacks, (ii) showing that sentence-level differential privacy reduces the risk of PII disclosure but still leaks about 3% of PII sequences, and (iii) a subtle connection between record-level membership inference and PII reconstruction.
SoK: Let The Privacy Games Begin! A Unified Treatment of Data Inference Privacy in Machine Learning
Dec 21, 2022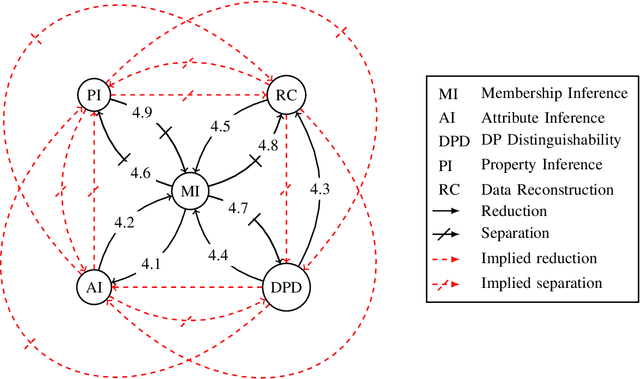

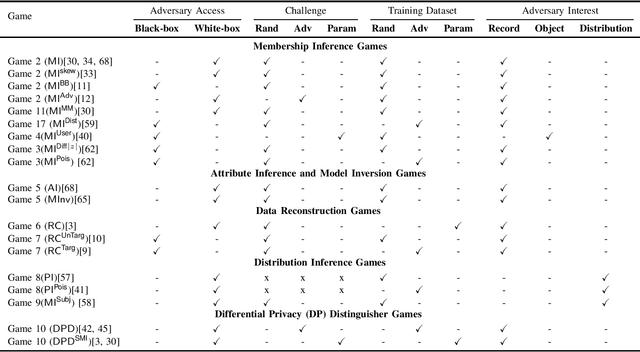
Deploying machine learning models in production may allow adversaries to infer sensitive information about training data. There is a vast literature analyzing different types of inference risks, ranging from membership inference to reconstruction attacks. Inspired by the success of games (i.e., probabilistic experiments) to study security properties in cryptography, some authors describe privacy inference risks in machine learning using a similar game-based style. However, adversary capabilities and goals are often stated in subtly different ways from one presentation to the other, which makes it hard to relate and compose results. In this paper, we present a game-based framework to systematize the body of knowledge on privacy inference risks in machine learning.
UnGANable: Defending Against GAN-based Face Manipulation
Oct 03, 2022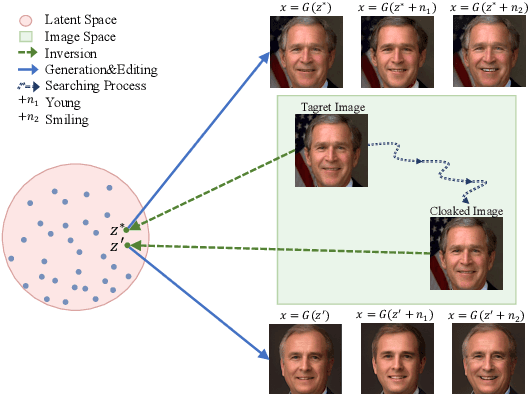

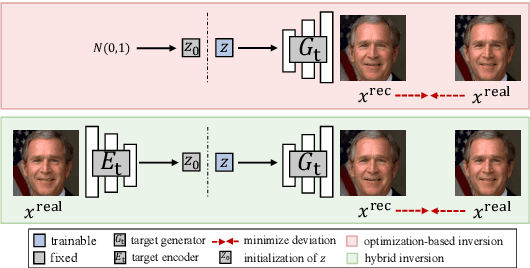
Deepfakes pose severe threats of visual misinformation to our society. One representative deepfake application is face manipulation that modifies a victim's facial attributes in an image, e.g., changing her age or hair color. The state-of-the-art face manipulation techniques rely on Generative Adversarial Networks (GANs). In this paper, we propose the first defense system, namely UnGANable, against GAN-inversion-based face manipulation. In specific, UnGANable focuses on defending GAN inversion, an essential step for face manipulation. Its core technique is to search for alternative images (called cloaked images) around the original images (called target images) in image space. When posted online, these cloaked images can jeopardize the GAN inversion process. We consider two state-of-the-art inversion techniques including optimization-based inversion and hybrid inversion, and design five different defenses under five scenarios depending on the defender's background knowledge. Extensive experiments on four popular GAN models trained on two benchmark face datasets show that UnGANable achieves remarkable effectiveness and utility performance, and outperforms multiple baseline methods. We further investigate four adaptive adversaries to bypass UnGANable and show that some of them are slightly effective.
Bayesian Estimation of Differential Privacy
Jun 15, 2022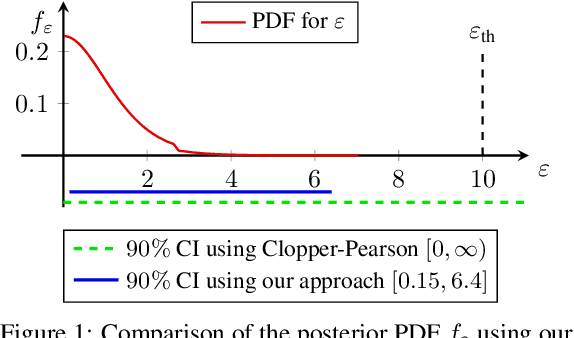

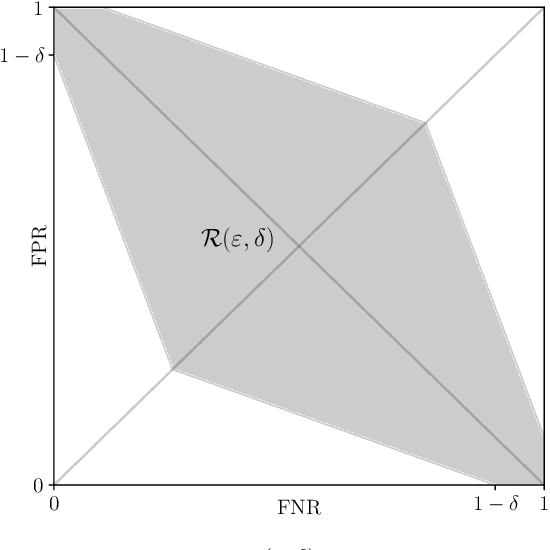
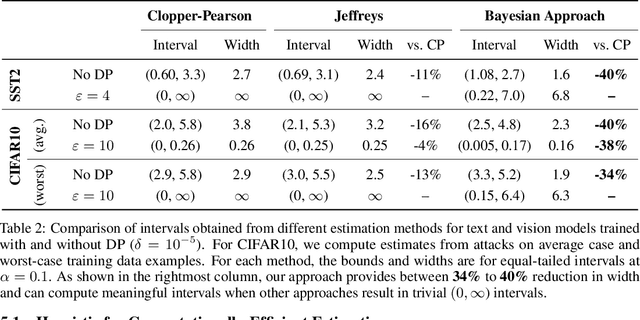
Algorithms such as Differentially Private SGD enable training machine learning models with formal privacy guarantees. However, there is a discrepancy between the protection that such algorithms guarantee in theory and the protection they afford in practice. An emerging strand of work empirically estimates the protection afforded by differentially private training as a confidence interval for the privacy budget $\varepsilon$ spent on training a model. Existing approaches derive confidence intervals for $\varepsilon$ from confidence intervals for the false positive and false negative rates of membership inference attacks. Unfortunately, obtaining narrow high-confidence intervals for $\epsilon$ using this method requires an impractically large sample size and training as many models as samples. We propose a novel Bayesian method that greatly reduces sample size, and adapt and validate a heuristic to draw more than one sample per trained model. Our Bayesian method exploits the hypothesis testing interpretation of differential privacy to obtain a posterior for $\varepsilon$ (not just a confidence interval) from the joint posterior of the false positive and false negative rates of membership inference attacks. For the same sample size and confidence, we derive confidence intervals for $\varepsilon$ around 40% narrower than prior work. The heuristic, which we adapt from label-only DP, can be used to further reduce the number of trained models needed to get enough samples by up to 2 orders of magnitude.