 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAlan C. Bovik
Joint Quality Assessment and Example-Guided Image Processing by Disentangling Picture Appearance from Content
Apr 20, 2024
The deep learning revolution has strongly impacted low-level image processing tasks such as style/domain transfer, enhancement/restoration, and visual quality assessments. Despite often being treated separately, the aforementioned tasks share a common theme of understanding, editing, or enhancing the appearance of input images without modifying the underlying content. We leverage this observation to develop a novel disentangled representation learning method that decomposes inputs into content and appearance features. The model is trained in a self-supervised manner and we use the learned features to develop a new quality prediction model named DisQUE. We demonstrate through extensive evaluations that DisQUE achieves state-of-the-art accuracy across quality prediction tasks and distortion types. Moreover, we demonstrate that the same features may also be used for image processing tasks such as HDR tone mapping, where the desired output characteristics may be tuned using example input-output pairs.
Cut-FUNQUE: An Objective Quality Model for Compressed Tone-Mapped High Dynamic Range Videos
Apr 20, 2024High Dynamic Range (HDR) videos have enjoyed a surge in popularity in recent years due to their ability to represent a wider range of contrast and color than Standard Dynamic Range (SDR) videos. Although HDR video capture has seen increasing popularity because of recent flagship mobile phones such as Apple iPhones, Google Pixels, and Samsung Galaxy phones, a broad swath of consumers still utilize legacy SDR displays that are unable to display HDR videos. As result, HDR videos must be processed, i.e., tone-mapped, before streaming to a large section of SDR-capable video consumers. However, server-side tone-mapping involves automating decisions regarding the choices of tone-mapping operators (TMOs) and their parameters to yield high-fidelity outputs. Moreover, these choices must be balanced against the effects of lossy compression, which is ubiquitous in streaming scenarios. In this work, we develop a novel, efficient model of objective video quality named Cut-FUNQUE that is able to accurately predict the visual quality of tone-mapped and compressed HDR videos. Finally, we evaluate Cut-FUNQUE on a large-scale crowdsourced database of such videos and show that it achieves state-of-the-art accuracy.
Subjective Quality Assessment of Compressed Tone-Mapped High Dynamic Range Videos
Mar 22, 2024High Dynamic Range (HDR) videos are able to represent wider ranges of contrasts and colors than Standard Dynamic Range (SDR) videos, giving more vivid experiences. Due to this, HDR videos are expected to grow into the dominant video modality of the future. However, HDR videos are incompatible with existing SDR displays, which form the majority of affordable consumer displays on the market. Because of this, HDR videos must be processed by tone-mapping them to reduced bit-depths to service a broad swath of SDR-limited video consumers. Here, we analyze the impact of tone-mapping operators on the visual quality of streaming HDR videos. To this end, we built the first large-scale subjectively annotated open-source database of compressed tone-mapped HDR videos, containing 15,000 tone-mapped sequences derived from 40 unique HDR source contents. The videos in the database were labeled with more than 750,000 subjective quality annotations, collected from more than 1,600 unique human observers. We demonstrate the usefulness of the new subjective database by benchmarking objective models of visual quality on it. We envision that the new LIVE Tone-Mapped HDR (LIVE-TMHDR) database will enable significant progress on HDR video tone mapping and quality assessment in the future. To this end, we make the database freely available to the community at https://live.ece.utexas.edu/research/LIVE_TMHDR/index.html
Subjective and Objective Analysis of Indian Social Media Video Quality
Jan 05, 2024We conducted a large-scale subjective study of the perceptual quality of User-Generated Mobile Video Content on a set of mobile-originated videos obtained from the Indian social media platform ShareChat. The content viewed by volunteer human subjects under controlled laboratory conditions has the benefit of culturally diversifying the existing corpus of User-Generated Content (UGC) video quality datasets. There is a great need for large and diverse UGC-VQA datasets, given the explosive global growth of the visual internet and social media platforms. This is particularly true in regard to videos obtained by smartphones, especially in rapidly emerging economies like India. ShareChat provides a safe and cultural community oriented space for users to generate and share content in their preferred Indian languages and dialects. Our subjective quality study, which is based on this data, offers a boost of cultural, visual, and language diversification to the video quality research community. We expect that this new data resource will also allow for the development of systems that can predict the perceived visual quality of Indian social media videos, to control scaling and compression protocols for streaming, provide better user recommendations, and guide content analysis and processing. We demonstrate the value of the new data resource by conducting a study of leading blind video quality models on it, including a new model, called MoEVA, which deploys a mixture of experts to predict video quality. Both the new LIVE-ShareChat dataset and sample source code for MoEVA are being made freely available to the research community at https://github.com/sandeep-sm/LIVE-SC
A FUNQUE Approach to the Quality Assessment of Compressed HDR Videos
Dec 13, 2023Recent years have seen steady growth in the popularity and availability of High Dynamic Range (HDR) content, particularly videos, streamed over the internet. As a result, assessing the subjective quality of HDR videos, which are generally subjected to compression, is of increasing importance. In particular, we target the task of full-reference quality assessment of compressed HDR videos. The state-of-the-art (SOTA) approach HDRMAX involves augmenting off-the-shelf video quality models, such as VMAF, with features computed on non-linearly transformed video frames. However, HDRMAX increases the computational complexity of models like VMAF. Here, we show that an efficient class of video quality prediction models named FUNQUE+ achieves SOTA accuracy. This shows that the FUNQUE+ models are flexible alternatives to VMAF that achieve higher HDR video quality prediction accuracy at lower computational cost.
Bitrate Ladder Construction using Visual Information Fidelity
Dec 12, 2023Recently proposed perceptually optimized per-title video encoding methods provide better BD-rate savings than fixed bitrate-ladder approaches that have been employed in the past. However, a disadvantage of per-title encoding is that it requires significant time and energy to compute bitrate ladders. Over the past few years, a variety of methods have been proposed to construct optimal bitrate ladders including using low-level features to predict cross-over bitrates, optimal resolutions for each bitrate, predicting visual quality, etc. Here, we deploy features drawn from Visual Information Fidelity (VIF) (VIF features) extracted from uncompressed videos to predict the visual quality (VMAF) of compressed videos. We present multiple VIF feature sets extracted from different scales and subbands of a video to tackle the problem of bitrate ladder construction. Comparisons are made against a fixed bitrate ladder and a bitrate ladder obtained from exhaustive encoding using Bjontegaard delta metrics.
Joint Deep Image Restoration and Unsupervised Quality Assessment
Nov 27, 2023Deep learning techniques have revolutionized the fields of image restoration and image quality assessment in recent years. While image restoration methods typically utilize synthetically distorted training data for training, deep quality assessment models often require expensive labeled subjective data. However, recent studies have shown that activations of deep neural networks trained for visual modeling tasks can also be used for perceptual quality assessment of images. Following this intuition, we propose a novel attention-based convolutional neural network capable of simultaneously performing both image restoration and quality assessment. We achieve this by training a JPEG deblocking network augmented with "quality attention" maps and demonstrating state-of-the-art deblocking accuracy, achieving a high correlation of predicted quality with human opinion scores.
Quality Modeling Under A Relaxed Natural Scene Statistics Model
Nov 26, 2023Information-theoretic image quality assessment (IQA) models such as Visual Information Fidelity (VIF) and Spatio-temporal Reduced Reference Entropic Differences (ST-RRED) have enjoyed great success by seamlessly integrating natural scene statistics (NSS) with information theory. The Gaussian Scale Mixture (GSM) model that governs the wavelet subband coefficients of natural images forms the foundation for these algorithms. However, the explosion of user-generated content on social media, which is typically distorted by one or more of many possible unknown impairments, has revealed the limitations of NSS-based IQA models that rely on the simple GSM model. Here, we seek to elaborate the VIF index by deriving useful properties of the Multivariate Generalized Gaussian Distribution (MGGD), and using them to study the behavior of VIF under a Generalized GSM (GGSM) model.
HIDRO-VQA: High Dynamic Range Oracle for Video Quality Assessment
Nov 18, 2023We introduce HIDRO-VQA, a no-reference (NR) video quality assessment model designed to provide precise quality evaluations of High Dynamic Range (HDR) videos. HDR videos exhibit a broader spectrum of luminance, detail, and color than Standard Dynamic Range (SDR) videos. As HDR content becomes increasingly popular, there is a growing demand for video quality assessment (VQA) algorithms that effectively address distortions unique to HDR content. To address this challenge, we propose a self-supervised contrastive fine-tuning approach to transfer quality-aware features from the SDR to the HDR domain, utilizing unlabeled HDR videos. Our findings demonstrate that self-supervised pre-trained neural networks on SDR content can be further fine-tuned in a self-supervised setting using limited unlabeled HDR videos to achieve state-of-the-art performance on the only publicly available VQA database for HDR content, the LIVE-HDR VQA database. Moreover, our algorithm can be extended to the Full Reference VQA setting, also achieving state-of-the-art performance. Our code is available publicly at https://github.com/avinabsaha/HIDRO-VQA.
Study of Subjective and Objective Quality Assessment of Mobile Cloud Gaming Videos
May 26, 2023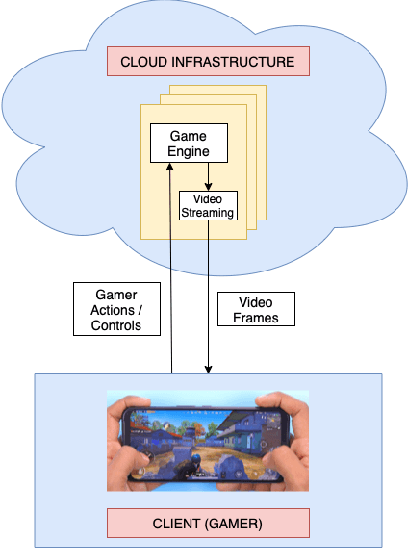
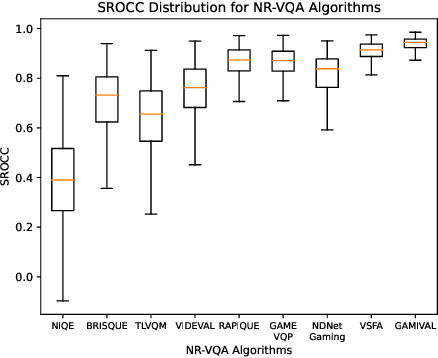

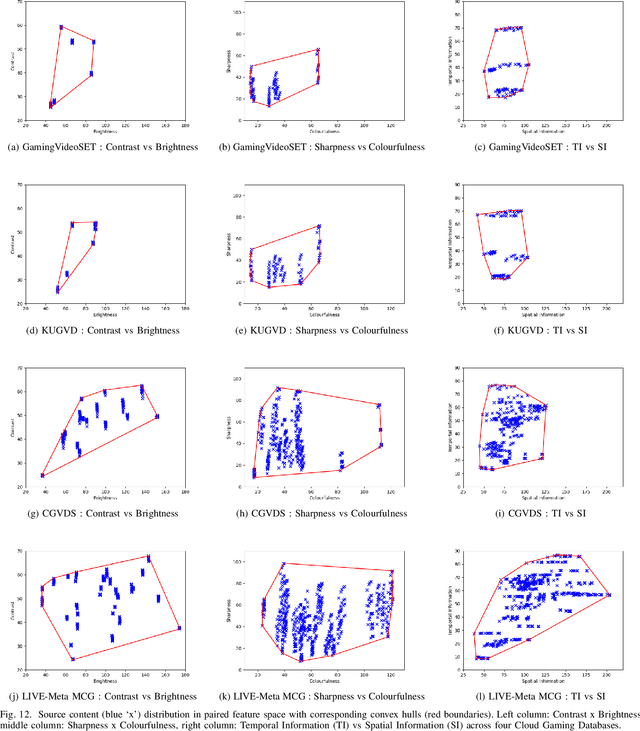
We present the outcomes of a recent large-scale subjective study of Mobile Cloud Gaming Video Quality Assessment (MCG-VQA) on a diverse set of gaming videos. Rapid advancements in cloud services, faster video encoding technologies, and increased access to high-speed, low-latency wireless internet have all contributed to the exponential growth of the Mobile Cloud Gaming industry. Consequently, the development of methods to assess the quality of real-time video feeds to end-users of cloud gaming platforms has become increasingly important. However, due to the lack of a large-scale public Mobile Cloud Gaming Video dataset containing a diverse set of distorted videos with corresponding subjective scores, there has been limited work on the development of MCG-VQA models. Towards accelerating progress towards these goals, we created a new dataset, named the LIVE-Meta Mobile Cloud Gaming (LIVE-Meta-MCG) video quality database, composed of 600 landscape and portrait gaming videos, on which we collected 14,400 subjective quality ratings from an in-lab subjective study. Additionally, to demonstrate the usefulness of the new resource, we benchmarked multiple state-of-the-art VQA algorithms on the database. The new database will be made publicly available on our website: \url{https://live.ece.utexas.edu/research/LIVE-Meta-Mobile-Cloud-Gaming/index.html}