 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAlbert Y. C. Chen
No More Ambiguity in 360° Room Layout via Bi-Layout Estimation
Apr 15, 2024
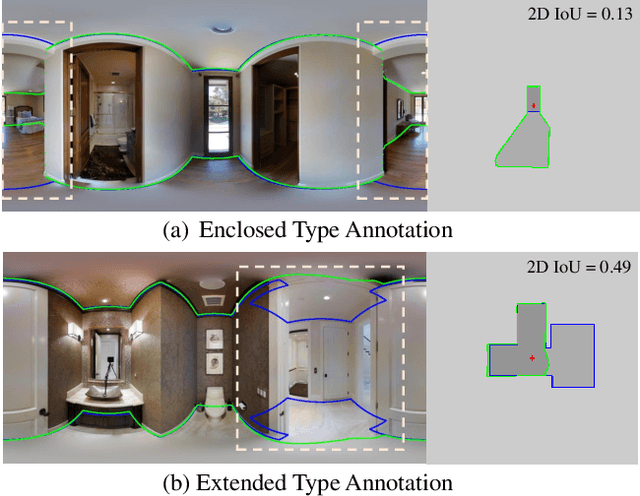
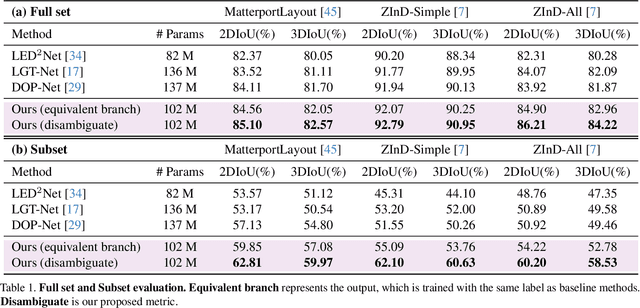
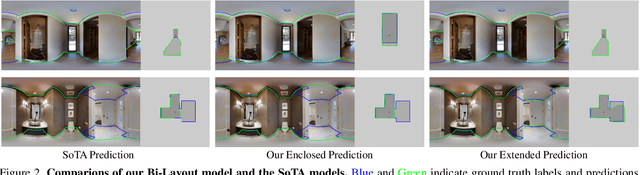

Inherent ambiguity in layout annotations poses significant challenges to developing accurate 360{\deg} room layout estimation models. To address this issue, we propose a novel Bi-Layout model capable of predicting two distinct layout types. One stops at ambiguous regions, while the other extends to encompass all visible areas. Our model employs two global context embeddings, where each embedding is designed to capture specific contextual information for each layout type. With our novel feature guidance module, the image feature retrieves relevant context from these embeddings, generating layout-aware features for precise bi-layout predictions. A unique property of our Bi-Layout model is its ability to inherently detect ambiguous regions by comparing the two predictions. To circumvent the need for manual correction of ambiguous annotations during testing, we also introduce a new metric for disambiguating ground truth layouts. Our method demonstrates superior performance on benchmark datasets, notably outperforming leading approaches. Specifically, on the MatterportLayout dataset, it improves 3DIoU from 81.70% to 82.57% across the full test set and notably from 54.80% to 59.97% in subsets with significant ambiguity. Project page: https://liagm.github.io/Bi_Layout/
GDA: Generalized Diffusion for Robust Test-time Adaptation
Apr 02, 2024Machine learning models struggle with generalization when encountering out-of-distribution (OOD) samples with unexpected distribution shifts. For vision tasks, recent studies have shown that test-time adaptation employing diffusion models can achieve state-of-the-art accuracy improvements on OOD samples by generating new samples that align with the model's domain without the need to modify the model's weights. Unfortunately, those studies have primarily focused on pixel-level corruptions, thereby lacking the generalization to adapt to a broader range of OOD types. We introduce Generalized Diffusion Adaptation (GDA), a novel diffusion-based test-time adaptation method robust against diverse OOD types. Specifically, GDA iteratively guides the diffusion by applying a marginal entropy loss derived from the model, in conjunction with style and content preservation losses during the reverse sampling process. In other words, GDA considers the model's output behavior with the semantic information of the samples as a whole, which can reduce ambiguity in downstream tasks during the generation process. Evaluation across various popular model architectures and OOD benchmarks shows that GDA consistently outperforms prior work on diffusion-driven adaptation. Notably, it achieves the highest classification accuracy improvements, ranging from 4.4\% to 5.02\% on ImageNet-C and 2.5\% to 7.4\% on Rendition, Sketch, and Stylized benchmarks. This performance highlights GDA's generalization to a broader range of OOD benchmarks.