 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAleksandar Armacki
A Unified Framework for Gradient-based Clustering of Distributed Data
Feb 02, 2024
We develop a family of distributed clustering algorithms that work over networks of users. In the proposed scenario, users contain a local dataset and communicate only with their immediate neighbours, with the aim of finding a clustering of the full, joint data. The proposed family, termed Distributed Gradient Clustering (DGC-$\mathcal{F}_\rho$), is parametrized by $\rho \geq 1$, controling the proximity of users' center estimates, with $\mathcal{F}$ determining the clustering loss. Specialized to popular clustering losses like $K$-means and Huber loss, DGC-$\mathcal{F}_\rho$ gives rise to novel distributed clustering algorithms DGC-KM$_\rho$ and DGC-HL$_\rho$, while a novel clustering loss based on the logistic function leads to DGC-LL$_\rho$. We provide a unified analysis and establish several strong results, under mild assumptions. First, the sequence of centers generated by the methods converges to a well-defined notion of fixed point, under any center initialization and value of $\rho$. Second, as $\rho$ increases, the family of fixed points produced by DGC-$\mathcal{F}_\rho$ converges to a notion of consensus fixed points. We show that consensus fixed points of DGC-$\mathcal{F}_{\rho}$ are equivalent to fixed points of gradient clustering over the full data, guaranteeing a clustering of the full data is produced. For the special case of Bregman losses, we show that our fixed points converge to the set of Lloyd points. Numerical experiments on real data confirm our theoretical findings and demonstrate strong performance of the methods.
High-probability Convergence Bounds for Nonlinear Stochastic Gradient Descent Under Heavy-tailed Noise
Oct 28, 2023Several recent works have studied the convergence \textit{in high probability} of stochastic gradient descent (SGD) and its clipped variant. Compared to vanilla SGD, clipped SGD is practically more stable and has the additional theoretical benefit of logarithmic dependence on the failure probability. However, the convergence of other practical nonlinear variants of SGD, e.g., sign SGD, quantized SGD and normalized SGD, that achieve improved communication efficiency or accelerated convergence is much less understood. In this work, we study the convergence bounds \textit{in high probability} of a broad class of nonlinear SGD methods. For strongly convex loss functions with Lipschitz continuous gradients, we prove a logarithmic dependence on the failure probability, even when the noise is heavy-tailed. Strictly more general than the results for clipped SGD, our results hold for any nonlinearity with bounded (component-wise or joint) outputs, such as clipping, normalization, and quantization. Further, existing results with heavy-tailed noise assume bounded $\eta$-th central moments, with $\eta \in (1,2]$. In contrast, our refined analysis works even for $\eta=1$, strictly relaxing the noise moment assumptions in the literature.
One-Shot Federated Learning for Model Clustering and Learning in Heterogeneous Environments
Sep 22, 2022
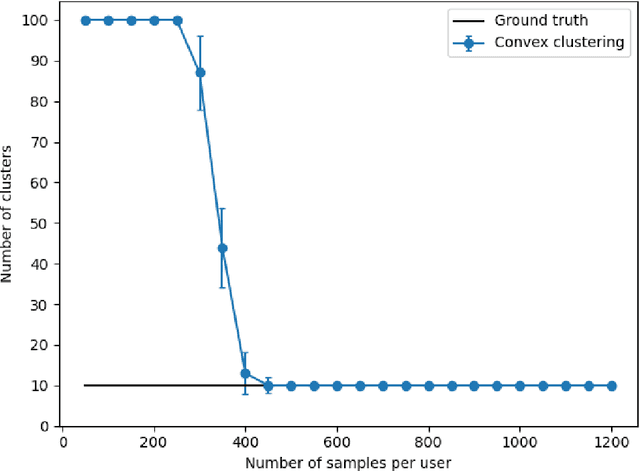
We propose a communication efficient approach for federated learning in heterogeneous environments. The system heterogeneity is reflected in the presence of $K$ different data distributions, with each user sampling data from only one of $K$ distributions. The proposed approach requires only one communication round between the users and server, thus significantly reducing the communication cost. Moreover, the proposed method provides strong learning guarantees in heterogeneous environments, by achieving the optimal mean-squared error (MSE) rates in terms of the sample size, i.e., matching the MSE guarantees achieved by learning on all data points belonging to users with the same data distribution, provided that the number of data points per user is above a threshold that we explicitly characterize in terms of system parameters. Remarkably, this is achieved without requiring any knowledge of the underlying distributions, or even the true number of distributions $K$. Numerical experiments illustrate our findings and underline the performance of the proposed method.
Gradient Based Clustering
Feb 01, 2022


We propose a general approach for distance based clustering, using the gradient of the cost function that measures clustering quality with respect to cluster assignments and cluster center positions. The approach is an iterative two step procedure (alternating between cluster assignment and cluster center updates) and is applicable to a wide range of functions, satisfying some mild assumptions. The main advantage of the proposed approach is a simple and computationally cheap update rule. Unlike previous methods that specialize to a specific formulation of the clustering problem, our approach is applicable to a wide range of costs, including non-Bregman clustering methods based on the Huber loss. We analyze the convergence of the proposed algorithm, and show that it converges to the set of appropriately defined fixed points, under arbitrary center initialization. In the special case of Bregman cost functions, the algorithm converges to the set of centroidal Voronoi partitions, which is consistent with prior works. Numerical experiments on real data demonstrate the effectiveness of the proposed method.
Personalized Federated Learning via Convex Clustering
Feb 01, 2022



We propose a parametric family of algorithms for personalized federated learning with locally convex user costs. The proposed framework is based on a generalization of convex clustering in which the differences between different users' models are penalized via a sum-of-norms penalty, weighted by a penalty parameter $\lambda$. The proposed approach enables "automatic" model clustering, without prior knowledge of the hidden cluster structure, nor the number of clusters. Analytical bounds on the weight parameter, that lead to simultaneous personalization, generalization and automatic model clustering are provided. The solution to the formulated problem enables personalization, by providing different models across different clusters, and generalization, by providing models different than the per-user models computed in isolation. We then provide an efficient algorithm based on the Parallel Direction Method of Multipliers (PDMM) to solve the proposed formulation in a federated server-users setting. Numerical experiments corroborate our findings. As an interesting byproduct, our results provide several generalizations to convex clustering.