 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAlessandro Rudi
Closed-form Filtering for Non-linear Systems
Feb 15, 2024
Sequential Bayesian Filtering aims to estimate the current state distribution of a Hidden Markov Model, given the past observations. The problem is well-known to be intractable for most application domains, except in notable cases such as the tabular setting or for linear dynamical systems with gaussian noise. In this work, we propose a new class of filters based on Gaussian PSD Models, which offer several advantages in terms of density approximation and computational efficiency. We show that filtering can be efficiently performed in closed form when transitions and observations are Gaussian PSD Models. When the transition and observations are approximated by Gaussian PSD Models, we show that our proposed estimator enjoys strong theoretical guarantees, with estimation error that depends on the quality of the approximation and is adaptive to the regularity of the transition probabilities. In particular, we identify regimes in which our proposed filter attains a TV $\epsilon$-error with memory and computational complexity of $O(\epsilon^{-1})$ and $O(\epsilon^{-3/2})$ respectively, including the offline learning step, in contrast to the $O(\epsilon^{-2})$ complexity of sampling methods such as particle filtering.
GloptiNets: Scalable Non-Convex Optimization with Certificates
Jun 26, 2023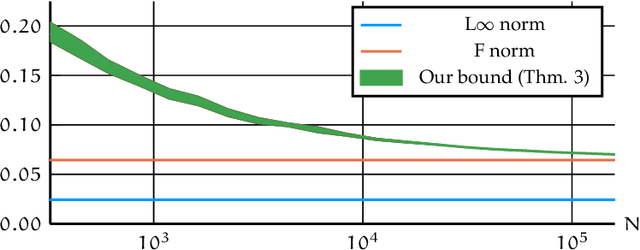
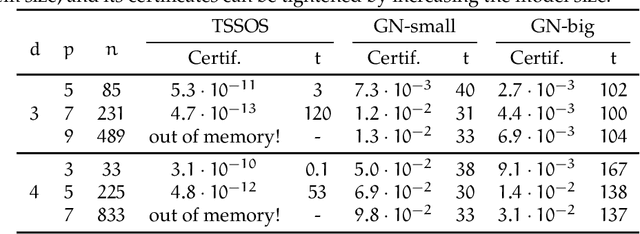
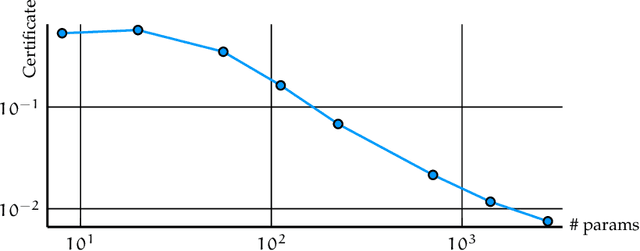
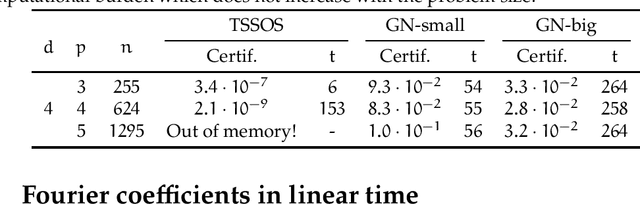
We present a novel approach to non-convex optimization with certificates, which handles smooth functions on the hypercube or on the torus. Unlike traditional methods that rely on algebraic properties, our algorithm exploits the regularity of the target function intrinsic in the decay of its Fourier spectrum. By defining a tractable family of models, we allow at the same time to obtain precise certificates and to leverage the advanced and powerful computational techniques developed to optimize neural networks. In this way the scalability of our approach is naturally enhanced by parallel computing with GPUs. Our approach, when applied to the case of polynomials of moderate dimensions but with thousands of coefficients, outperforms the state-of-the-art optimization methods with certificates, as the ones based on Lasserre's hierarchy, addressing problems intractable for the competitors.
Non-Parametric Learning of Stochastic Differential Equations with Fast Rates of Convergence
May 24, 2023We propose a novel non-parametric learning paradigm for the identification of drift and diffusion coefficients of non-linear stochastic differential equations, which relies upon discrete-time observations of the state. The key idea essentially consists of fitting a RKHS-based approximation of the corresponding Fokker-Planck equation to such observations, yielding theoretical estimates of learning rates which, unlike previous works, become increasingly tighter when the regularity of the unknown drift and diffusion coefficients becomes higher. Our method being kernel-based, offline pre-processing may in principle be profitably leveraged to enable efficient numerical implementation.
Efficient Sampling of Stochastic Differential Equations with Positive Semi-Definite Models
Mar 30, 2023This paper deals with the problem of efficient sampling from a stochastic differential equation, given the drift function and the diffusion matrix. The proposed approach leverages a recent model for probabilities \citep{rudi2021psd} (the positive semi-definite -- PSD model) from which it is possible to obtain independent and identically distributed (i.i.d.) samples at precision $\varepsilon$ with a cost that is $m^2 d \log(1/\varepsilon)$ where $m$ is the dimension of the model, $d$ the dimension of the space. The proposed approach consists in: first, computing the PSD model that satisfies the Fokker-Planck equation (or its fractional variant) associated with the SDE, up to error $\varepsilon$, and then sampling from the resulting PSD model. Assuming some regularity of the Fokker-Planck solution (i.e. $\beta$-times differentiability plus some geometric condition on its zeros) We obtain an algorithm that: (a) in the preparatory phase obtains a PSD model with L2 distance $\varepsilon$ from the solution of the equation, with a model of dimension $m = \varepsilon^{-(d+1)/(\beta-2s)} (\log(1/\varepsilon))^{d+1}$ where $0<s\leq1$ is the fractional power to the Laplacian, and total computational complexity of $O(m^{3.5} \log(1/\varepsilon))$ and then (b) for Fokker-Planck equation, it is able to produce i.i.d.\ samples with error $\varepsilon$ in Wasserstein-1 distance, with a cost that is $O(d \varepsilon^{-2(d+1)/\beta-2} \log(1/\varepsilon)^{2d+3})$ per sample. This means that, if the probability associated with the SDE is somewhat regular, i.e. $\beta \geq 4d+2$, then the algorithm requires $O(\varepsilon^{-0.88} \log(1/\varepsilon)^{4.5d})$ in the preparatory phase, and $O(\varepsilon^{-1/2}\log(1/\varepsilon)^{2d+2})$ for each sample. Our results suggest that as the true solution gets smoother, we can circumvent the curse of dimensionality without requiring any sort of convexity.
Approximation of optimization problems with constraints through kernel Sum-Of-Squares
Jan 16, 2023

Handling an infinite number of inequality constraints in infinite-dimensional spaces occurs in many fields, from global optimization to optimal transport. These problems have been tackled individually in several previous articles through kernel Sum-Of-Squares (kSoS) approximations. We propose here a unified theorem to prove convergence guarantees for these schemes. Inequalities are turned into equalities to a class of nonnegative kSoS functions. This enables the use of scattering inequalities to mitigate the curse of dimensionality in sampling the constraints, leveraging the assumed smoothness of the functions appearing in the problem. This approach is illustrated in learning vector fields with side information, here the invariance of a set.
Vector-Valued Least-Squares Regression under Output Regularity Assumptions
Nov 16, 2022



We propose and analyse a reduced-rank method for solving least-squares regression problems with infinite dimensional output. We derive learning bounds for our method, and study under which setting statistical performance is improved in comparison to full-rank method. Our analysis extends the interest of reduced-rank regression beyond the standard low-rank setting to more general output regularity assumptions. We illustrate our theoretical insights on synthetic least-squares problems. Then, we propose a surrogate structured prediction method derived from this reduced-rank method. We assess its benefits on three different problems: image reconstruction, multi-label classification, and metabolite identification.
Active Labeling: Streaming Stochastic Gradients
May 26, 2022



The workhorse of machine learning is stochastic gradient descent. To access stochastic gradients, it is common to consider iteratively input/output pairs of a training dataset. Interestingly, it appears that one does not need full supervision to access stochastic gradients, which is the main motivation of this paper. After formalizing the "active labeling" problem, which generalizes active learning based on partial supervision, we provide a streaming technique that provably minimizes the ratio of generalization error over number of samples. We illustrate our technique in depth for robust regression.
Non-Convex Optimization with Certificates and Fast Rates Through Kernel Sums of Squares
Apr 11, 2022

We consider potentially non-convex optimization problems, for which optimal rates of approximation depend on the dimension of the parameter space and the smoothness of the function to be optimized. In this paper, we propose an algorithm that achieves close to optimal a priori computational guarantees, while also providing a posteriori certificates of optimality. Our general formulation builds on infinite-dimensional sums-of-squares and Fourier analysis, and is instantiated on the minimization of multivariate periodic functions.
Measuring dissimilarity with diffeomorphism invariance
Mar 07, 2022



Measures of similarity (or dissimilarity) are a key ingredient to many machine learning algorithms. We introduce DID, a pairwise dissimilarity measure applicable to a wide range of data spaces, which leverages the data's internal structure to be invariant to diffeomorphisms. We prove that DID enjoys properties which make it relevant for theoretical study and practical use. By representing each datum as a function, DID is defined as the solution to an optimization problem in a Reproducing Kernel Hilbert Space and can be expressed in closed-form. In practice, it can be efficiently approximated via Nystr\"om sampling. Empirical experiments support the merits of DID.
On the Benefits of Large Learning Rates for Kernel Methods
Feb 28, 2022



This paper studies an intriguing phenomenon related to the good generalization performance of estimators obtained by using large learning rates within gradient descent algorithms. First observed in the deep learning literature, we show that a phenomenon can be precisely characterized in the context of kernel methods, even though the resulting optimization problem is convex. Specifically, we consider the minimization of a quadratic objective in a separable Hilbert space, and show that with early stopping, the choice of learning rate influences the spectral decomposition of the obtained solution on the Hessian's eigenvectors. This extends an intuition described by Nakkiran (2020) on a two-dimensional toy problem to realistic learning scenarios such as kernel ridge regression. While large learning rates may be proven beneficial as soon as there is a mismatch between the train and test objectives, we further explain why it already occurs in classification tasks without assuming any particular mismatch between train and test data distributions.