 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAlexander Rakhlin
Online Estimation via Offline Estimation: An Information-Theoretic Framework
Apr 15, 2024
$ $The classical theory of statistical estimation aims to estimate a parameter of interest under data generated from a fixed design ("offline estimation"), while the contemporary theory of online learning provides algorithms for estimation under adaptively chosen covariates ("online estimation"). Motivated by connections between estimation and interactive decision making, we ask: is it possible to convert offline estimation algorithms into online estimation algorithms in a black-box fashion? We investigate this question from an information-theoretic perspective by introducing a new framework, Oracle-Efficient Online Estimation (OEOE), where the learner can only interact with the data stream indirectly through a sequence of offline estimators produced by a black-box algorithm operating on the stream. Our main results settle the statistical and computational complexity of online estimation in this framework. $\bullet$ Statistical complexity. We show that information-theoretically, there exist algorithms that achieve near-optimal online estimation error via black-box offline estimation oracles, and give a nearly-tight characterization for minimax rates in the OEOE framework. $\bullet$ Computational complexity. We show that the guarantees above cannot be achieved in a computationally efficient fashion in general, but give a refined characterization for the special case of conditional density estimation: computationally efficient online estimation via black-box offline estimation is possible whenever it is possible via unrestricted algorithms. Finally, we apply our results to give offline oracle-efficient algorithms for interactive decision making.
Offline Reinforcement Learning: Role of State Aggregation and Trajectory Data
Mar 25, 2024We revisit the problem of offline reinforcement learning with value function realizability but without Bellman completeness. Previous work by Xie and Jiang (2021) and Foster et al. (2022) left open the question whether a bounded concentrability coefficient along with trajectory-based offline data admits a polynomial sample complexity. In this work, we provide a negative answer to this question for the task of offline policy evaluation. In addition to addressing this question, we provide a rather complete picture for offline policy evaluation with only value function realizability. Our primary findings are threefold: 1) The sample complexity of offline policy evaluation is governed by the concentrability coefficient in an aggregated Markov Transition Model jointly determined by the function class and the offline data distribution, rather than that in the original MDP. This unifies and generalizes the ideas of Xie and Jiang (2021) and Foster et al. (2022), 2) The concentrability coefficient in the aggregated Markov Transition Model may grow exponentially with the horizon length, even when the concentrability coefficient in the original MDP is small and the offline data is admissible (i.e., the data distribution equals the occupancy measure of some policy), 3) Under value function realizability, there is a generic reduction that can convert any hard instance with admissible data to a hard instance with trajectory data, implying that trajectory data offers no extra benefits over admissible data. These three pieces jointly resolve the open problem, though each of them could be of independent interest.
On the Performance of Empirical Risk Minimization with Smoothed Data
Feb 22, 2024In order to circumvent statistical and computational hardness results in sequential decision-making, recent work has considered smoothed online learning, where the distribution of data at each time is assumed to have bounded likeliehood ratio with respect to a base measure when conditioned on the history. While previous works have demonstrated the benefits of smoothness, they have either assumed that the base measure is known to the learner or have presented computationally inefficient algorithms applying only in special cases. This work investigates the more general setting where the base measure is \emph{unknown} to the learner, focusing in particular on the performance of Empirical Risk Minimization (ERM) with square loss when the data are well-specified and smooth. We show that in this setting, ERM is able to achieve sublinear error whenever a class is learnable with iid data; in particular, ERM achieves error scaling as $\tilde O( \sqrt{\mathrm{comp}(\mathcal F)\cdot T} )$, where $\mathrm{comp}(\mathcal F)$ is the statistical complexity of learning $\mathcal F$ with iid data. In so doing, we prove a novel norm comparison bound for smoothed data that comprises the first sharp norm comparison for dependent data applying to arbitrary, nonlinear function classes. We complement these results with a lower bound indicating that our analysis of ERM is essentially tight, establishing a separation in the performance of ERM between smoothed and iid data.
Foundations of Reinforcement Learning and Interactive Decision Making
Dec 27, 2023These lecture notes give a statistical perspective on the foundations of reinforcement learning and interactive decision making. We present a unifying framework for addressing the exploration-exploitation dilemma using frequentist and Bayesian approaches, with connections and parallels between supervised learning/estimation and decision making as an overarching theme. Special attention is paid to function approximation and flexible model classes such as neural networks. Topics covered include multi-armed and contextual bandits, structured bandits, and reinforcement learning with high-dimensional feedback.
When is Agnostic Reinforcement Learning Statistically Tractable?
Oct 09, 2023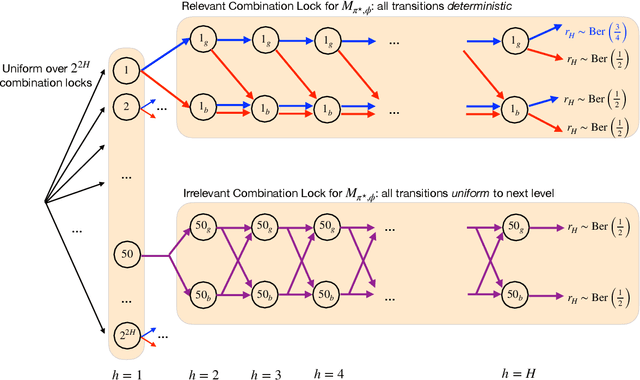
We study the problem of agnostic PAC reinforcement learning (RL): given a policy class $\Pi$, how many rounds of interaction with an unknown MDP (with a potentially large state and action space) are required to learn an $\epsilon$-suboptimal policy with respect to $\Pi$? Towards that end, we introduce a new complexity measure, called the \emph{spanning capacity}, that depends solely on the set $\Pi$ and is independent of the MDP dynamics. With a generative model, we show that for any policy class $\Pi$, bounded spanning capacity characterizes PAC learnability. However, for online RL, the situation is more subtle. We show there exists a policy class $\Pi$ with a bounded spanning capacity that requires a superpolynomial number of samples to learn. This reveals a surprising separation for agnostic learnability between generative access and online access models (as well as between deterministic/stochastic MDPs under online access). On the positive side, we identify an additional \emph{sunflower} structure, which in conjunction with bounded spanning capacity enables statistically efficient online RL via a new algorithm called POPLER, which takes inspiration from classical importance sampling methods as well as techniques for reachable-state identification and policy evaluation in reward-free exploration.
Efficient Model-Free Exploration in Low-Rank MDPs
Jul 08, 2023A major challenge in reinforcement learning is to develop practical, sample-efficient algorithms for exploration in high-dimensional domains where generalization and function approximation is required. Low-Rank Markov Decision Processes -- where transition probabilities admit a low-rank factorization based on an unknown feature embedding -- offer a simple, yet expressive framework for RL with function approximation, but existing algorithms are either (1) computationally intractable, or (2) reliant upon restrictive statistical assumptions such as latent variable structure, access to model-based function approximation, or reachability. In this work, we propose the first provably sample-efficient algorithm for exploration in Low-Rank MDPs that is both computationally efficient and model-free, allowing for general function approximation and requiring no additional structural assumptions. Our algorithm, VoX, uses the notion of a generalized optimal design for the feature embedding as an efficiently computable basis for exploration, performing efficient optimal design computation by interleaving representation learning and policy optimization. Our analysis -- which is appealingly simple and modular -- carefully combines several techniques, including a new reduction from optimal design computation to policy optimization based on the Frank-Wolfe method, and an improved analysis of a certain minimax representation learning objective found in prior work.
Convex and Non-Convex Optimization under Generalized Smoothness
Jun 02, 2023
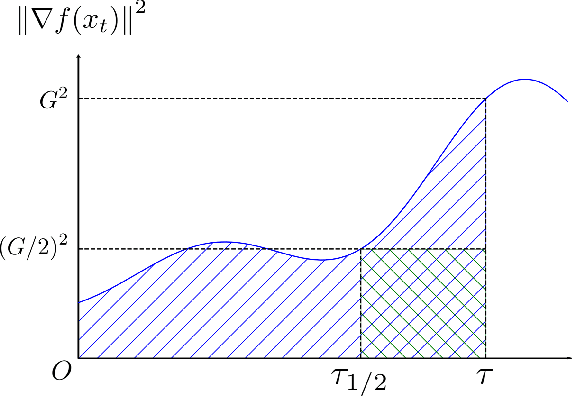

Classical analysis of convex and non-convex optimization methods often requires the Lipshitzness of the gradient, which limits the analysis to functions bounded by quadratics. Recent work relaxed this requirement to a non-uniform smoothness condition with the Hessian norm bounded by an affine function of the gradient norm, and proved convergence in the non-convex setting via gradient clipping, assuming bounded noise. In this paper, we further generalize this non-uniform smoothness condition and develop a simple, yet powerful analysis technique that bounds the gradients along the trajectory, thereby leading to stronger results for both convex and non-convex optimization problems. In particular, we obtain the classical convergence rates for (stochastic) gradient descent and Nesterov's accelerated gradient method in the convex and/or non-convex setting under this general smoothness condition. The new analysis approach does not require gradient clipping and allows heavy-tailed noise with bounded variance in the stochastic setting.
On the Variance, Admissibility, and Stability of Empirical Risk Minimization
May 29, 2023It is well known that Empirical Risk Minimization (ERM) with squared loss may attain minimax suboptimal error rates (Birg\'e and Massart, 1993). The key message of this paper is that, under mild assumptions, the suboptimality of ERM must be due to large bias rather than variance. More precisely, in the bias-variance decomposition of the squared error of the ERM, the variance term necessarily enjoys the minimax rate. In the case of fixed design, we provide an elementary proof of this fact using the probabilistic method. Then, we prove this result for various models in the random design setting. In addition, we provide a simple proof of Chatterjee's admissibility theorem (Chatterjee, 2014, Theorem 1.4), which states that ERM cannot be ruled out as an optimal method, in the fixed design setting, and extend this result to the random design setting. We also show that our estimates imply stability of ERM, complementing the main result of Caponnetto and Rakhlin (2006) for non-Donsker classes. Finally, we show that for non-Donsker classes, there are functions close to the ERM, yet far from being almost-minimizers of the empirical loss, highlighting the somewhat irregular nature of the loss landscape.
On the Complexity of Multi-Agent Decision Making: From Learning in Games to Partial Monitoring
May 01, 2023A central problem in the theory of multi-agent reinforcement learning (MARL) is to understand what structural conditions and algorithmic principles lead to sample-efficient learning guarantees, and how these considerations change as we move from few to many agents. We study this question in a general framework for interactive decision making with multiple agents, encompassing Markov games with function approximation and normal-form games with bandit feedback. We focus on equilibrium computation, in which a centralized learning algorithm aims to compute an equilibrium by controlling multiple agents that interact with an unknown environment. Our main contributions are: - We provide upper and lower bounds on the optimal sample complexity for multi-agent decision making based on a multi-agent generalization of the Decision-Estimation Coefficient, a complexity measure introduced by Foster et al. (2021) in the single-agent counterpart to our setting. Compared to the best results for the single-agent setting, our bounds have additional gaps. We show that no "reasonable" complexity measure can close these gaps, highlighting a striking separation between single and multiple agents. - We show that characterizing the statistical complexity for multi-agent decision making is equivalent to characterizing the statistical complexity of single-agent decision making, but with hidden (unobserved) rewards, a framework that subsumes variants of the partial monitoring problem. As a consequence, we characterize the statistical complexity for hidden-reward interactive decision making to the best extent possible. Building on this development, we provide several new structural results, including 1) conditions under which the statistical complexity of multi-agent decision making can be reduced to that of single-agent, and 2) conditions under which the so-called curse of multiple agents can be avoided.
Convergence of Adam Under Relaxed Assumptions
Apr 27, 2023In this paper, we provide a rigorous proof of convergence of the Adaptive Moment Estimate (Adam) algorithm for a wide class of optimization objectives. Despite the popularity and efficiency of the Adam algorithm in training deep neural networks, its theoretical properties are not yet fully understood, and existing convergence proofs require unrealistically strong assumptions, such as globally bounded gradients, to show the convergence to stationary points. In this paper, we show that Adam provably converges to $\epsilon$-stationary points with $\mathcal{O}(\epsilon^{-4})$ gradient complexity under far more realistic conditions. The key to our analysis is a new proof of boundedness of gradients along the optimization trajectory, under a generalized smoothness assumption according to which the local smoothness (i.e., Hessian norm when it exists) is bounded by a sub-quadratic function of the gradient norm. Moreover, we propose a variance-reduced version of Adam with an accelerated gradient complexity of $\mathcal{O}(\epsilon^{-3})$.