 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAlexey Ignatiev
Anytime Approximate Formal Feature Attribution
Dec 12, 2023




Widespread use of artificial intelligence (AI) algorithms and machine learning (ML) models on the one hand and a number of crucial issues pertaining to them warrant the need for explainable artificial intelligence (XAI). A key explainability question is: given this decision was made, what are the input features which contributed to the decision? Although a range of XAI approaches exist to tackle this problem, most of them have significant limitations. Heuristic XAI approaches suffer from the lack of quality guarantees, and often try to approximate Shapley values, which is not the same as explaining which features contribute to a decision. A recent alternative is so-called formal feature attribution (FFA), which defines feature importance as the fraction of formal abductive explanations (AXp's) containing the given feature. This measures feature importance from the view of formally reasoning about the model's behavior. It is challenging to compute FFA using its definition because that involves counting AXp's, although one can approximate it. Based on these results, this paper makes several contributions. First, it gives compelling evidence that computing FFA is intractable, even if the set of contrastive formal explanations (CXp's) is provided, by proving that the problem is #P-hard. Second, by using the duality between AXp's and CXp's, it proposes an efficient heuristic to switch from CXp enumeration to AXp enumeration on-the-fly resulting in an adaptive explanation enumeration algorithm effectively approximating FFA in an anytime fashion. Finally, experimental results obtained on a range of widely used datasets demonstrate the effectiveness of the proposed FFA approximation approach in terms of the error of FFA approximation as well as the number of explanations computed and their diversity given a fixed time limit.
On Formal Feature Attribution and Its Approximation
Jul 14, 2023



Recent years have witnessed the widespread use of artificial intelligence (AI) algorithms and machine learning (ML) models. Despite their tremendous success, a number of vital problems like ML model brittleness, their fairness, and the lack of interpretability warrant the need for the active developments in explainable artificial intelligence (XAI) and formal ML model verification. The two major lines of work in XAI include feature selection methods, e.g. Anchors, and feature attribution techniques, e.g. LIME and SHAP. Despite their promise, most of the existing feature selection and attribution approaches are susceptible to a range of critical issues, including explanation unsoundness and out-of-distribution sampling. A recent formal approach to XAI (FXAI) although serving as an alternative to the above and free of these issues suffers from a few other limitations. For instance and besides the scalability limitation, the formal approach is unable to tackle the feature attribution problem. Additionally, a formal explanation despite being formally sound is typically quite large, which hampers its applicability in practical settings. Motivated by the above, this paper proposes a way to apply the apparatus of formal XAI to the case of feature attribution based on formal explanation enumeration. Formal feature attribution (FFA) is argued to be advantageous over the existing methods, both formal and non-formal. Given the practical complexity of the problem, the paper then proposes an efficient technique for approximating exact FFA. Finally, it offers experimental evidence of the effectiveness of the proposed approximate FFA in comparison to the existing feature attribution algorithms not only in terms of feature importance and but also in terms of their relative order.
Delivering Inflated Explanations
Jun 27, 2023
In the quest for Explainable Artificial Intelligence (XAI) one of the questions that frequently arises given a decision made by an AI system is, ``why was the decision made in this way?'' Formal approaches to explainability build a formal model of the AI system and use this to reason about the properties of the system. Given a set of feature values for an instance to be explained, and a resulting decision, a formal abductive explanation is a set of features, such that if they take the given value will always lead to the same decision. This explanation is useful, it shows that only some features were used in making the final decision. But it is narrow, it only shows that if the selected features take their given values the decision is unchanged. It's possible that some features may change values and still lead to the same decision. In this paper we formally define inflated explanations which is a set of features, and for each feature of set of values (always including the value of the instance being explained), such that the decision will remain unchanged. Inflated explanations are more informative than abductive explanations since e.g they allow us to see if the exact value of a feature is important, or it could be any nearby value. Overall they allow us to better understand the role of each feature in the decision. We show that we can compute inflated explanations for not that much greater cost than abductive explanations, and that we can extend duality results for abductive explanations also to inflated explanations.
On Computing Probabilistic Abductive Explanations
Dec 12, 2022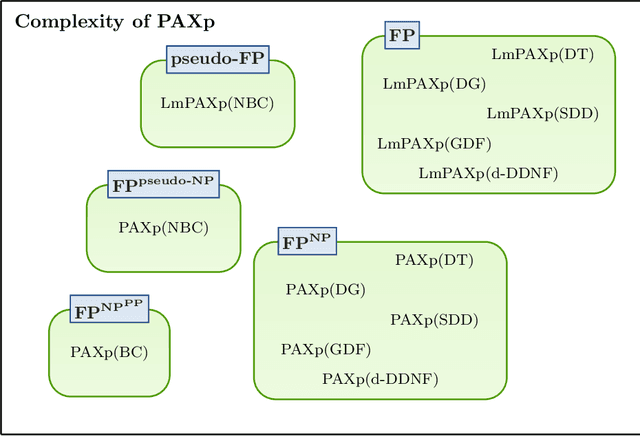

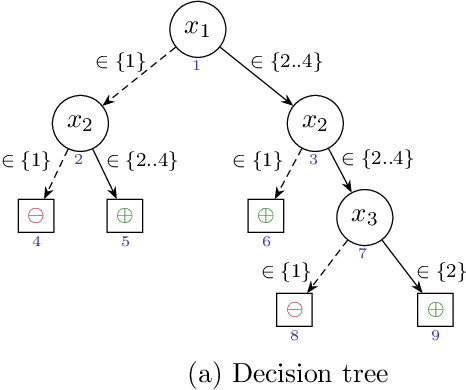
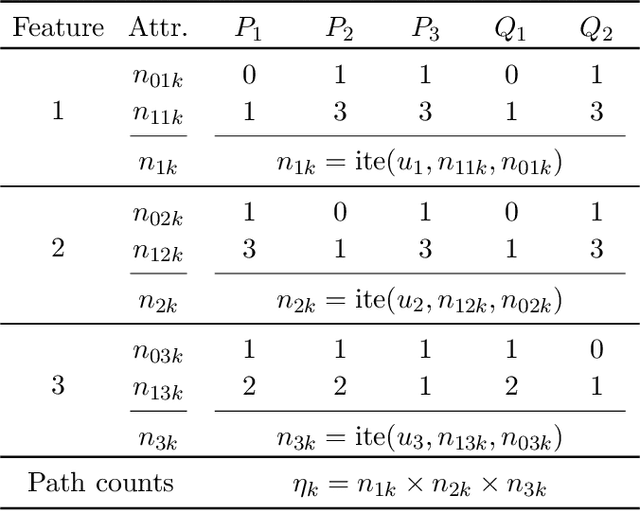
The most widely studied explainable AI (XAI) approaches are unsound. This is the case with well-known model-agnostic explanation approaches, and it is also the case with approaches based on saliency maps. One solution is to consider intrinsic interpretability, which does not exhibit the drawback of unsoundness. Unfortunately, intrinsic interpretability can display unwieldy explanation redundancy. Formal explainability represents the alternative to these non-rigorous approaches, with one example being PI-explanations. Unfortunately, PI-explanations also exhibit important drawbacks, the most visible of which is arguably their size. Recently, it has been observed that the (absolute) rigor of PI-explanations can be traded off for a smaller explanation size, by computing the so-called relevant sets. Given some positive {\delta}, a set S of features is {\delta}-relevant if, when the features in S are fixed, the probability of getting the target class exceeds {\delta}. However, even for very simple classifiers, the complexity of computing relevant sets of features is prohibitive, with the decision problem being NPPP-complete for circuit-based classifiers. In contrast with earlier negative results, this paper investigates practical approaches for computing relevant sets for a number of widely used classifiers that include Decision Trees (DTs), Naive Bayes Classifiers (NBCs), and several families of classifiers obtained from propositional languages. Moreover, the paper shows that, in practice, and for these families of classifiers, relevant sets are easy to compute. Furthermore, the experiments confirm that succinct sets of relevant features can be obtained for the families of classifiers considered.
Eliminating The Impossible, Whatever Remains Must Be True
Jun 20, 2022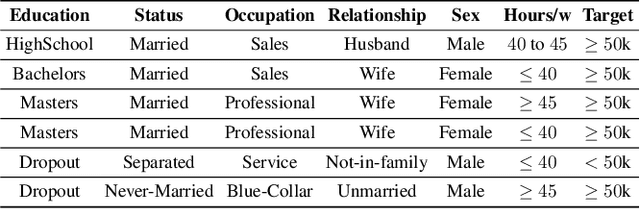
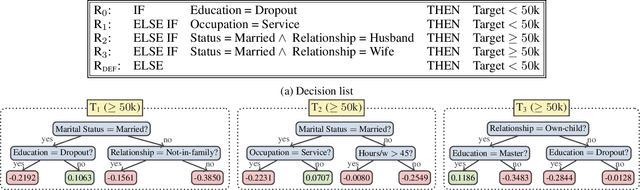

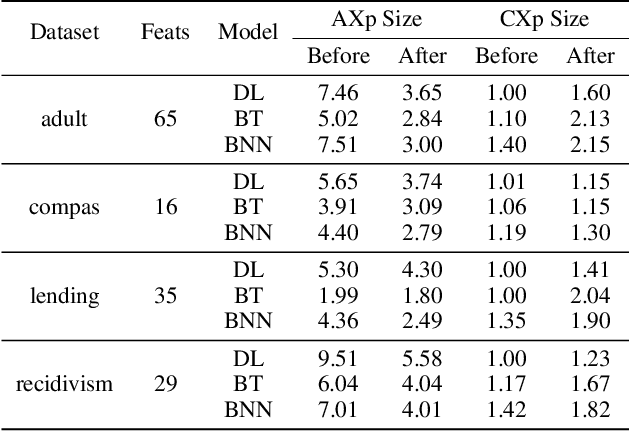
The rise of AI methods to make predictions and decisions has led to a pressing need for more explainable artificial intelligence (XAI) methods. One common approach for XAI is to produce a post-hoc explanation, explaining why a black box ML model made a certain prediction. Formal approaches to post-hoc explanations provide succinct reasons for why a prediction was made, as well as why not another prediction was made. But these approaches assume that features are independent and uniformly distributed. While this means that "why" explanations are correct, they may be longer than required. It also means the "why not" explanations may be suspect as the counterexamples they rely on may not be meaningful. In this paper, we show how one can apply background knowledge to give more succinct "why" formal explanations, that are presumably easier to interpret by humans, and give more accurate "why not" explanations. Furthermore, we also show how to use existing rule induction techniques to efficiently extract background information from a dataset, and also how to report which background information was used to make an explanation, allowing a human to examine it if they doubt the correctness of the explanation.
On Tackling Explanation Redundancy in Decision Trees
May 20, 2022



Decision trees (DTs) epitomize the ideal of interpretability of machine learning (ML) models. The interpretability of decision trees motivates explainability approaches by so-called intrinsic interpretability, and it is at the core of recent proposals for applying interpretable ML models in high-risk applications. The belief in DT interpretability is justified by the fact that explanations for DT predictions are generally expected to be succinct. Indeed, in the case of DTs, explanations correspond to DT paths. Since decision trees are ideally shallow, and so paths contain far fewer features than the total number of features, explanations in DTs are expected to be succinct, and hence interpretable. This paper offers both theoretical and experimental arguments demonstrating that, as long as interpretability of decision trees equates with succinctness of explanations, then decision trees ought not be deemed interpretable. The paper introduces logically rigorous path explanations and path explanation redundancy, and proves that there exist functions for which decision trees must exhibit paths with arbitrarily large explanation redundancy. The paper also proves that only a very restricted class of functions can be represented with DTs that exhibit no explanation redundancy. In addition, the paper includes experimental results substantiating that path explanation redundancy is observed ubiquitously in decision trees, including those obtained using different tree learning algorithms, but also in a wide range of publicly available decision trees. The paper also proposes polynomial-time algorithms for eliminating path explanation redundancy, which in practice require negligible time to compute. Thus, these algorithms serve to indirectly attain irreducible, and so succinct, explanations for decision trees.
Provably Precise, Succinct and Efficient Explanations for Decision Trees
May 19, 2022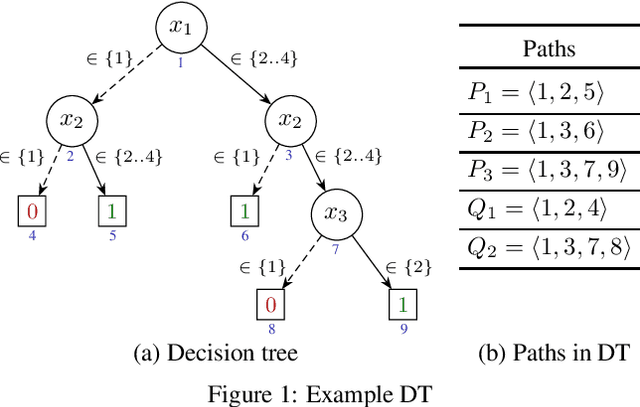

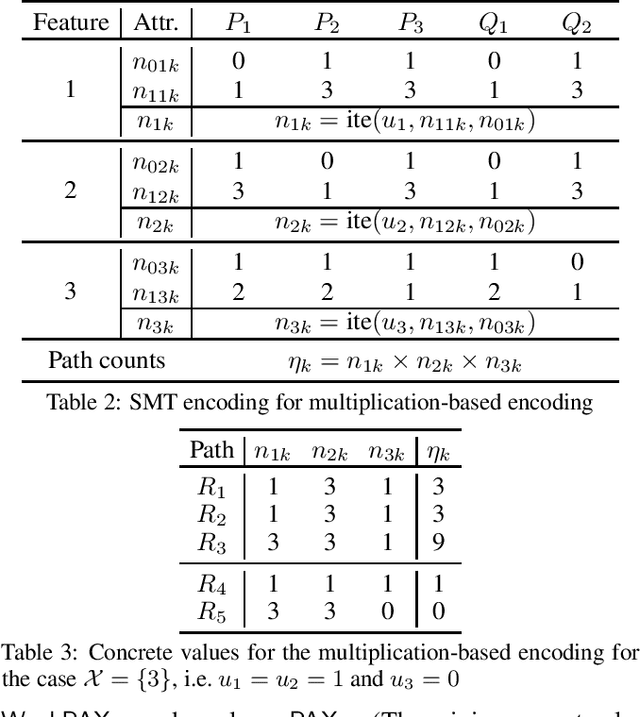
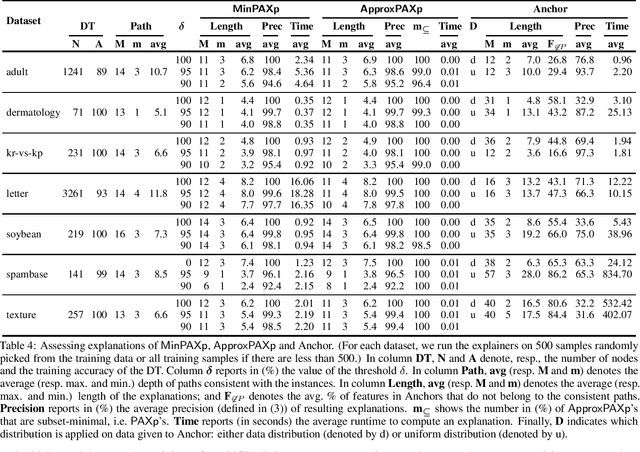
Decision trees (DTs) embody interpretable classifiers. DTs have been advocated for deployment in high-risk applications, but also for explaining other complex classifiers. Nevertheless, recent work has demonstrated that predictions in DTs ought to be explained with rigorous approaches. Although rigorous explanations can be computed in polynomial time for DTs, their size may be beyond the cognitive limits of human decision makers. This paper investigates the computation of {\delta}-relevant sets for DTs. {\delta}-relevant sets denote explanations that are succinct and provably precise. These sets represent generalizations of rigorous explanations, which are precise with probability one, and so they enable trading off explanation size for precision. The paper proposes two logic encodings for computing smallest {\delta}-relevant sets for DTs. The paper further devises a polynomial-time algorithm for computing {\delta}-relevant sets which are not guaranteed to be subset-minimal, but for which the experiments show to be most often subset-minimal in practice. The experimental results also demonstrate the practical efficiency of computing smallest {\delta}-relevant sets.
Efficient Explanations for Knowledge Compilation Languages
Jul 08, 2021


Knowledge compilation (KC) languages find a growing number of practical uses, including in Constraint Programming (CP) and in Machine Learning (ML). In most applications, one natural question is how to explain the decisions made by models represented by a KC language. This paper shows that for many of the best known KC languages, well-known classes of explanations can be computed in polynomial time. These classes include deterministic decomposable negation normal form (d-DNNF), and so any KC language that is strictly less succinct than d-DNNF. Furthermore, the paper also investigates the conditions under which polynomial time computation of explanations can be extended to KC languages more succinct than d-DNNF.
On Efficiently Explaining Graph-Based Classifiers
Jun 03, 2021



Recent work has shown that not only decision trees (DTs) may not be interpretable but also proposed a polynomial-time algorithm for computing one PI-explanation of a DT. This paper shows that for a wide range of classifiers, globally referred to as decision graphs, and which include decision trees and binary decision diagrams, but also their multi-valued variants, there exist polynomial-time algorithms for computing one PI-explanation. In addition, the paper also proposes a polynomial-time algorithm for computing one contrastive explanation. These novel algorithms build on explanation graphs (XpG's). XpG's denote a graph representation that enables both theoretical and practically efficient computation of explanations for decision graphs. Furthermore, the paper pro- poses a practically efficient solution for the enumeration of explanations, and studies the complexity of deciding whether a given feature is included in some explanation. For the concrete case of decision trees, the paper shows that the set of all contrastive explanations can be enumerated in polynomial time. Finally, the experimental results validate the practical applicability of the algorithms proposed in the paper on a wide range of publicly available benchmarks.
Efficient Explanations With Relevant Sets
Jun 01, 2021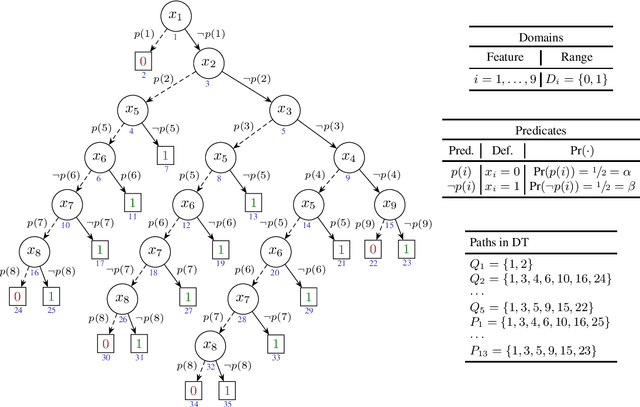
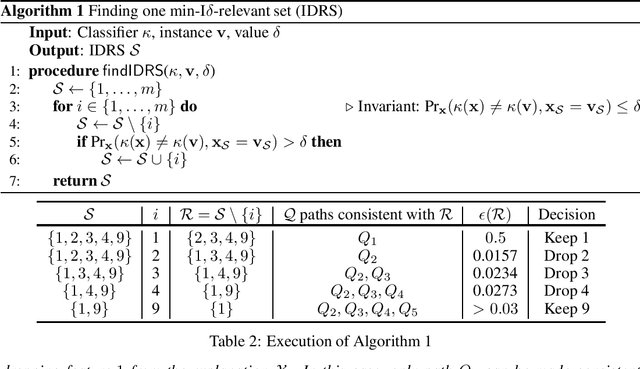
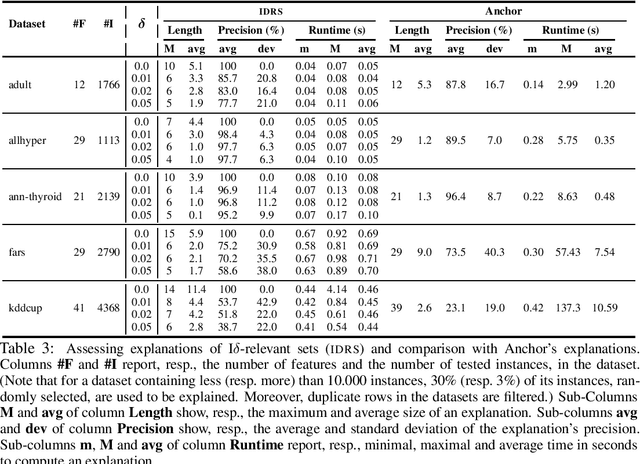
Recent work proposed $\delta$-relevant inputs (or sets) as a probabilistic explanation for the predictions made by a classifier on a given input. $\delta$-relevant sets are significant because they serve to relate (model-agnostic) Anchors with (model-accurate) PI- explanations, among other explanation approaches. Unfortunately, the computation of smallest size $\delta$-relevant sets is complete for ${NP}^{PP}$, rendering their computation largely infeasible in practice. This paper investigates solutions for tackling the practical limitations of $\delta$-relevant sets. First, the paper alternatively considers the computation of subset-minimal sets. Second, the paper studies concrete families of classifiers, including decision trees among others. For these cases, the paper shows that the computation of subset-minimal $\delta$-relevant sets is in NP, and can be solved with a polynomial number of calls to an NP oracle. The experimental evaluation compares the proposed approach with heuristic explainers for the concrete case of the classifiers studied in the paper, and confirms the advantage of the proposed solution over the state of the art.