 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAlireza Rezazadeh
SlotGNN: Unsupervised Discovery of Multi-Object Representations and Visual Dynamics
Oct 06, 2023




Learning multi-object dynamics from visual data using unsupervised techniques is challenging due to the need for robust, object representations that can be learned through robot interactions. This paper presents a novel framework with two new architectures: SlotTransport for discovering object representations from RGB images and SlotGNN for predicting their collective dynamics from RGB images and robot interactions. Our SlotTransport architecture is based on slot attention for unsupervised object discovery and uses a feature transport mechanism to maintain temporal alignment in object-centric representations. This enables the discovery of slots that consistently reflect the composition of multi-object scenes. These slots robustly bind to distinct objects, even under heavy occlusion or absence. Our SlotGNN, a novel unsupervised graph-based dynamics model, predicts the future state of multi-object scenes. SlotGNN learns a graph representation of the scene using the discovered slots from SlotTransport and performs relational and spatial reasoning to predict the future appearance of each slot conditioned on robot actions. We demonstrate the effectiveness of SlotTransport in learning object-centric features that accurately encode both visual and positional information. Further, we highlight the accuracy of SlotGNN in downstream robotic tasks, including challenging multi-object rearrangement and long-horizon prediction. Finally, our unsupervised approach proves effective in the real world. With only minimal additional data, our framework robustly predicts slots and their corresponding dynamics in real-world control tasks.
Hierarchical Graph Neural Networks for Proprioceptive 6D Pose Estimation of In-hand Objects
Jun 28, 2023



Robotic manipulation, in particular in-hand object manipulation, often requires an accurate estimate of the object's 6D pose. To improve the accuracy of the estimated pose, state-of-the-art approaches in 6D object pose estimation use observational data from one or more modalities, e.g., RGB images, depth, and tactile readings. However, existing approaches make limited use of the underlying geometric structure of the object captured by these modalities, thereby, increasing their reliance on visual features. This results in poor performance when presented with objects that lack such visual features or when visual features are simply occluded. Furthermore, current approaches do not take advantage of the proprioceptive information embedded in the position of the fingers. To address these limitations, in this paper: (1) we introduce a hierarchical graph neural network architecture for combining multimodal (vision and touch) data that allows for a geometrically informed 6D object pose estimation, (2) we introduce a hierarchical message passing operation that flows the information within and across modalities to learn a graph-based object representation, and (3) we introduce a method that accounts for the proprioceptive information for in-hand object representation. We evaluate our model on a diverse subset of objects from the YCB Object and Model Set, and show that our method substantially outperforms existing state-of-the-art work in accuracy and robustness to occlusion. We also deploy our proposed framework on a real robot and qualitatively demonstrate successful transfer to real settings.
KINet: Keypoint Interaction Networks for Unsupervised Forward Modeling
Feb 18, 2022



Object-centric representation is an essential abstraction for physical reasoning and forward prediction. Most existing approaches learn this representation through extensive supervision (e.g., object class and bounding box) although such ground-truth information is not readily accessible in reality. To address this, we introduce KINet (Keypoint Interaction Network) -- an end-to-end unsupervised framework to reason about object interactions in complex systems based on a keypoint representation. Using visual observations, our model learns to associate objects with keypoint coordinates and discovers a graph representation of the system as a set of keypoint embeddings and their relations. It then learns an action-conditioned forward model using contrastive estimation to predict future keypoint states. By learning to perform physical reasoning in the keypoint space, our model automatically generalizes to scenarios with a different number of objects, and novel object geometries. Experiments demonstrate the effectiveness of our model to accurately perform forward prediction and learn plannable object-centric representations which can also be used in downstream model-based control tasks.
Explainable Ensemble Machine Learning for Breast Cancer Diagnosis based on Ultrasound Image Texture Features
Jan 17, 2022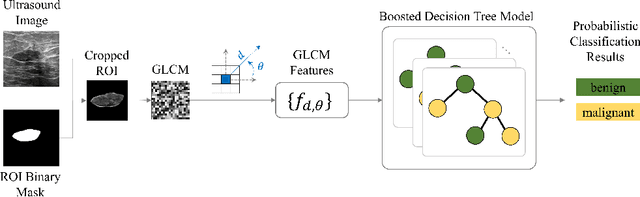
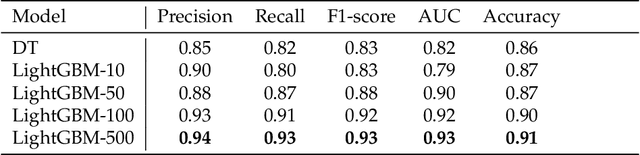
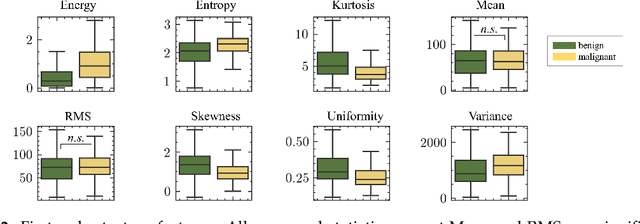
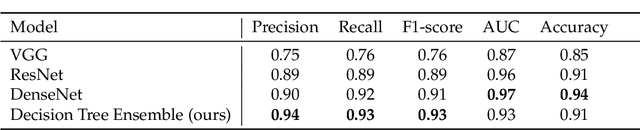
Image classification is widely used to build predictive models for breast cancer diagnosis. Most existing approaches overwhelmingly rely on deep convolutional networks to build such diagnosis pipelines. These model architectures, although remarkable in performance, are black-box systems that provide minimal insight into the inner logic behind their predictions. This is a major drawback as the explainability of prediction is vital for applications such as cancer diagnosis. In this paper, we address this issue by proposing an explainable machine learning pipeline for breast cancer diagnosis based on ultrasound images. We extract first- and second-order texture features of the ultrasound images and use them to build a probabilistic ensemble of decision tree classifiers. Each decision tree learns to classify the input ultrasound image by learning a set of robust decision thresholds for texture features of the image. The decision path of the model predictions can then be interpreted by decomposing the learned decision trees. Our results show that our proposed framework achieves high predictive performance while being explainable.
A Generalized Flow for B2B Sales Predictive Modeling: An Azure Machine Learning Approach
Feb 04, 2020



Predicting sales opportunities outcome is a core to successful business management and revenue forecasting. Conventionally, this prediction has relied mostly on subjective human evaluations in the process of business to business (B2B) sales decision making. Here, we proposed a practical Machine Learning (ML) workflow to empower B2B sales outcome (win/lose) prediction within a cloud-based computing platform: Microsoft Azure Machine Learning Service (Azure ML). This workflow consists of two pipelines: 1) an ML pipeline that trains probabilistic predictive models in parallel on the closed sales opportunities data enhanced with an extensive feature engineering procedure for automated selection and parameterization of an optimal ML model and 2) a Prediction pipeline that uses the optimal ML model to estimate the likelihood of winning new sales opportunities as well as predicting their outcome using optimized decision boundaries. The performance of the proposed workflow was evaluated on a real sales dataset of a B2B consulting firm.
Force Field Generalization and the Internal Representation of Motor Learning
Oct 07, 2019



When learning a new motor behavior, e.g. reaching in a force field, the nervous system builds an internal representation. Examining how subsequent reaches in unpracticed directions generalize reveals this representation. Though it is the subject of frequent studies, it is not known how this representation changes across training directions, or how changes in reach direction and the corresponding changes in limb impedance, influence measurements of it. We ran a force field adaptation experiment using eight groups of subjects each trained on one of eight standard directions and then tested for generalization in the remaining seven directions. Generalization in all directions was local and asymmetric, providing limited and unequal transfer to the left and right side of the trained target. These asymmetries were not consistent in either magnitude or direction even after correcting for changes in limb impedance, at odds with previous explanations. Relying on a standard model for generalization the inferred representations inconsistently shifted to one side or the other of their respective training direction. A second model that accounted for limb impedance and variations in baseline trajectories explained more data and the inferred representations were centered on their respective training directions. Our results highlight the influence of limb mechanics and impedance on psychophysical measurements and their interpretations for motor learning.