 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAlp Yurtsever
A Variational Perspective on High-Resolution ODEs
Nov 03, 2023
We consider unconstrained minimization of smooth convex functions. We propose a novel variational perspective using forced Euler-Lagrange equation that allows for studying high-resolution ODEs. Through this, we obtain a faster convergence rate for gradient norm minimization using Nesterov's accelerated gradient method. Additionally, we show that Nesterov's method can be interpreted as a rate-matching discretization of an appropriately chosen high-resolution ODE. Finally, using the results from the new variational perspective, we propose a stochastic method for noisy gradients. Several numerical experiments compare and illustrate our stochastic algorithm with state of the art methods.
Q-FW: A Hybrid Classical-Quantum Frank-Wolfe for Quadratic Binary Optimization
Mar 23, 2022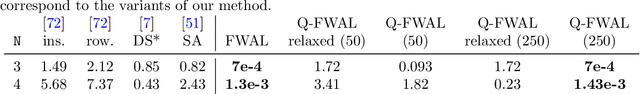

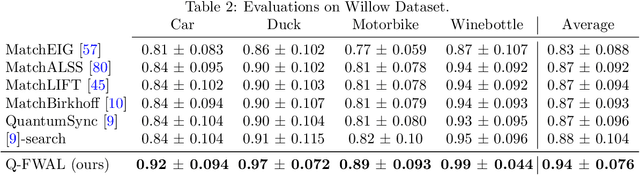
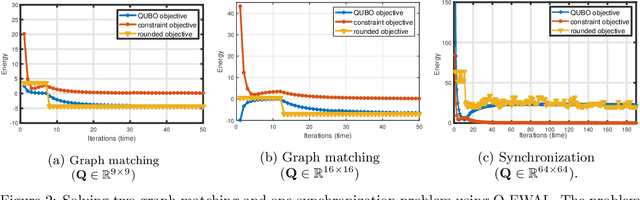
We present a hybrid classical-quantum framework based on the Frank-Wolfe algorithm, Q-FW, for solving quadratic, linearly-constrained, binary optimization problems on quantum annealers (QA). The computational premise of quantum computers has cultivated the re-design of various existing vision problems into quantum-friendly forms. Experimental QA realizations can solve a particular non-convex problem known as the quadratic unconstrained binary optimization (QUBO). Yet a naive-QUBO cannot take into account the restrictions on the parameters. To introduce additional structure in the parameter space, researchers have crafted ad-hoc solutions incorporating (linear) constraints in the form of regularizers. However, this comes at the expense of a hyper-parameter, balancing the impact of regularization. To date, a true constrained solver of quadratic binary optimization (QBO) problems has lacked. Q-FW first reformulates constrained-QBO as a copositive program (CP), then employs Frank-Wolfe iterations to solve CP while satisfying linear (in)equality constraints. This procedure unrolls the original constrained-QBO into a set of unconstrained QUBOs all of which are solved, in a sequel, on a QA. We use D-Wave Advantage QA to conduct synthetic and real experiments on two important computer vision problems, graph matching and permutation synchronization, which demonstrate that our approach is effective in alleviating the need for an explicit regularization coefficient.
Faster One-Sample Stochastic Conditional Gradient Method for Composite Convex Minimization
Feb 26, 2022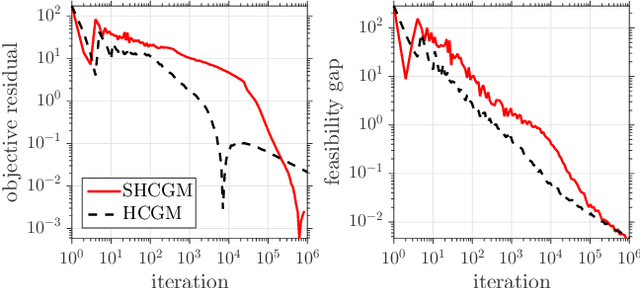

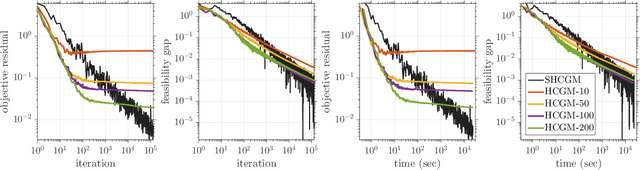
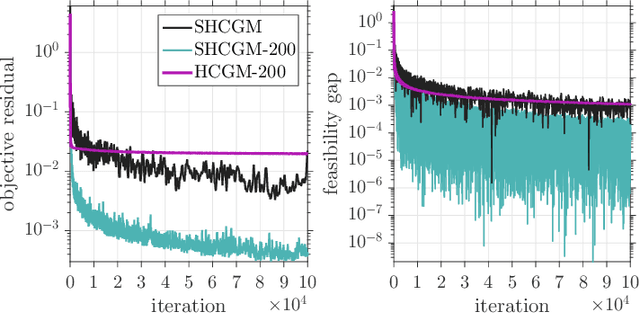
We propose a stochastic conditional gradient method (CGM) for minimizing convex finite-sum objectives formed as a sum of smooth and non-smooth terms. Existing CGM variants for this template either suffer from slow convergence rates, or require carefully increasing the batch size over the course of the algorithm's execution, which leads to computing full gradients. In contrast, the proposed method, equipped with a stochastic average gradient (SAG) estimator, requires only one sample per iteration. Nevertheless, it guarantees fast convergence rates on par with more sophisticated variance reduction techniques. In applications we put special emphasis on problems with a large number of separable constraints. Such problems are prevalent among semidefinite programming (SDP) formulations arising in machine learning and theoretical computer science. We provide numerical experiments on matrix completion, unsupervised clustering, and sparsest-cut SDPs.
An Optimal-Storage Approach to Semidefinite Programming using Approximate Complementarity
Feb 09, 2019
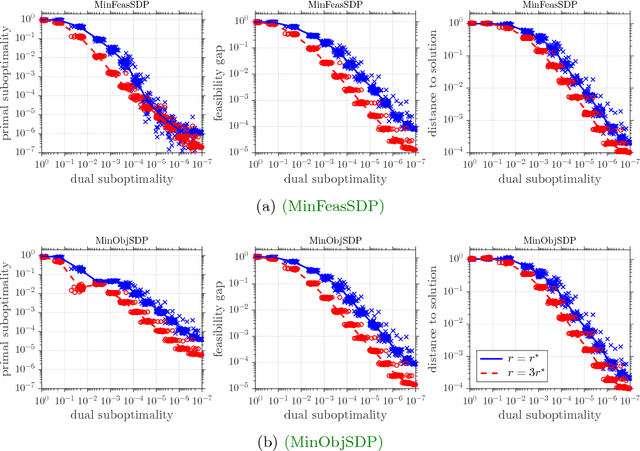
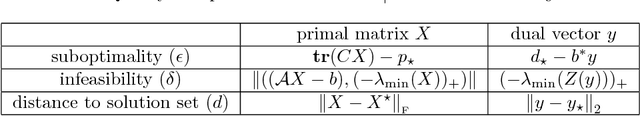
This paper develops a new storage-optimal algorithm that provably solves generic semidefinite programs (SDPs) in standard form. This method is particularly effective for weakly constrained SDPs. The key idea is to formulate an approximate complementarity principle: Given an approximate solution to the dual SDP, the primal SDP has an approximate solution whose range is contained in the eigenspace with small eigenvalues of the dual slack matrix. For weakly constrained SDPs, this eigenspace has very low dimension, so this observation significantly reduces the search space for the primal solution. This result suggests an algorithmic strategy that can be implemented with minimal storage: (1) Solve the dual SDP approximately; (2) compress the primal SDP to the eigenspace with small eigenvalues of the dual slack matrix; (3) solve the compressed primal SDP. The paper also provides numerical experiments showing that this approach is successful for a range of interesting large-scale SDPs.
Stochastic Conditional Gradient Method for Composite Convex Minimization
Jan 29, 2019In this paper, we propose the first practical algorithm to minimize stochastic composite optimization problems over compact convex sets. This template allows for affine constraints and therefore covers stochastic semidefinite programs (SDPs), which are vastly applicable in both machine learning and statistics. In this setup, stochastic algorithms with convergence guarantees are either not known or not tractable. We tackle this general problem and propose a convergent, easy to implement and tractable algorithm. We prove $\mathcal{O}(k^{-1/3})$ convergence rate in expectation on the objective residual and $\mathcal{O}(k^{-5/12})$ in expectation on the feasibility gap. These rates are achieved without increasing the batchsize, which can contain a single sample. We present extensive empirical evidence demonstrating the superiority of our algorithm on a broad range of applications including optimization of stochastic SDPs.
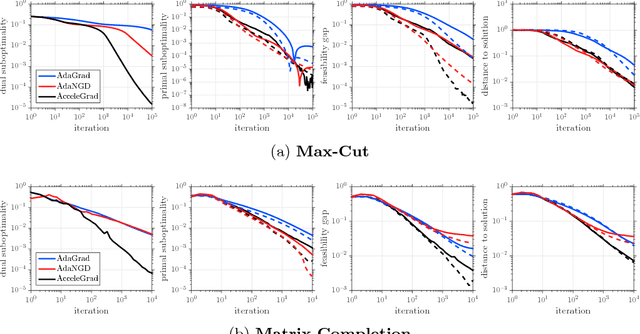
Online Adaptive Methods, Universality and Acceleration
Sep 08, 2018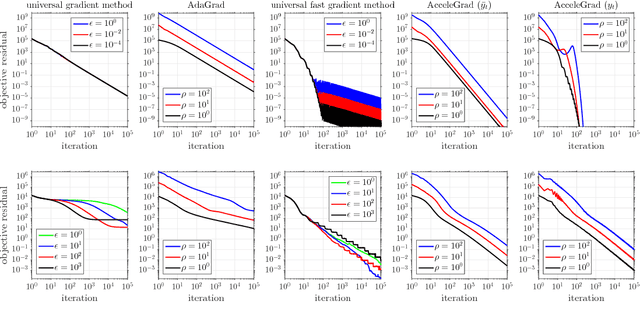
We present a novel method for convex unconstrained optimization that, without any modifications, ensures: (i) accelerated convergence rate for smooth objectives, (ii) standard convergence rate in the general (non-smooth) setting, and (iii) standard convergence rate in the stochastic optimization setting. To the best of our knowledge, this is the first method that simultaneously applies to all of the above settings. At the heart of our method is an adaptive learning rate rule that employs importance weights, in the spirit of adaptive online learning algorithms (Duchi et al., 2011; Levy, 2017), combined with an update that linearly couples two sequences, in the spirit of (Allen-Zhu and Orecchia, 2017). An empirical examination of our method demonstrates its applicability to the above mentioned scenarios and corroborates our theoretical findings.
Practical sketching algorithms for low-rank matrix approximation
Jan 02, 2018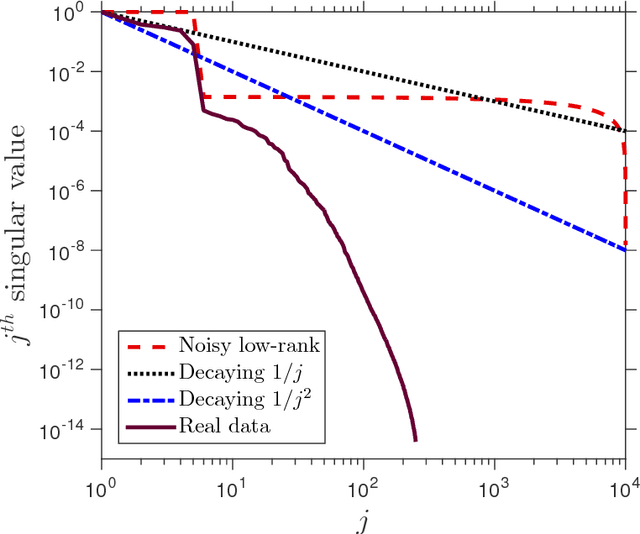
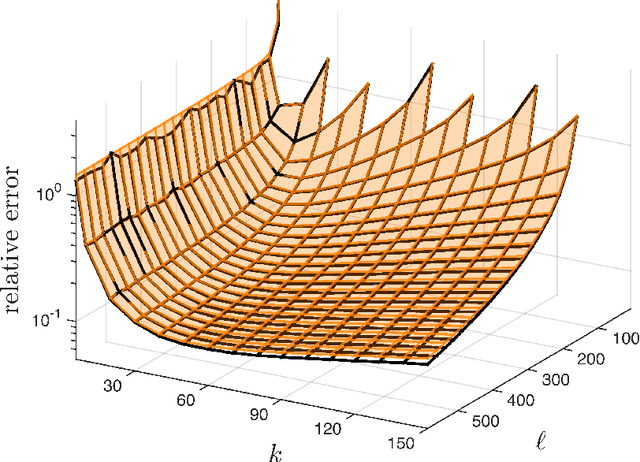
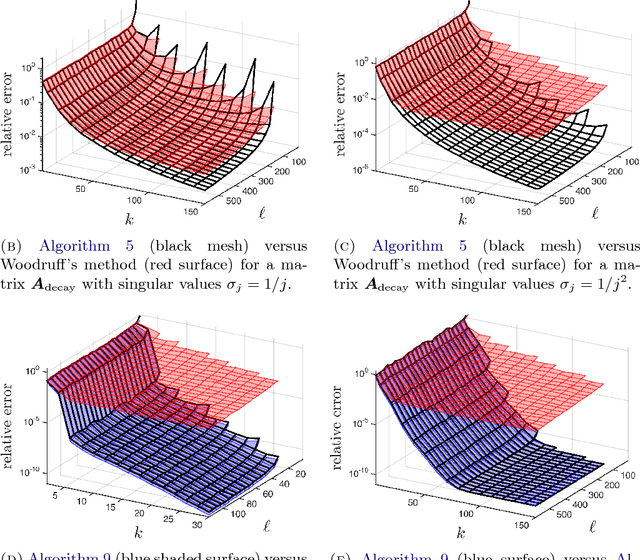
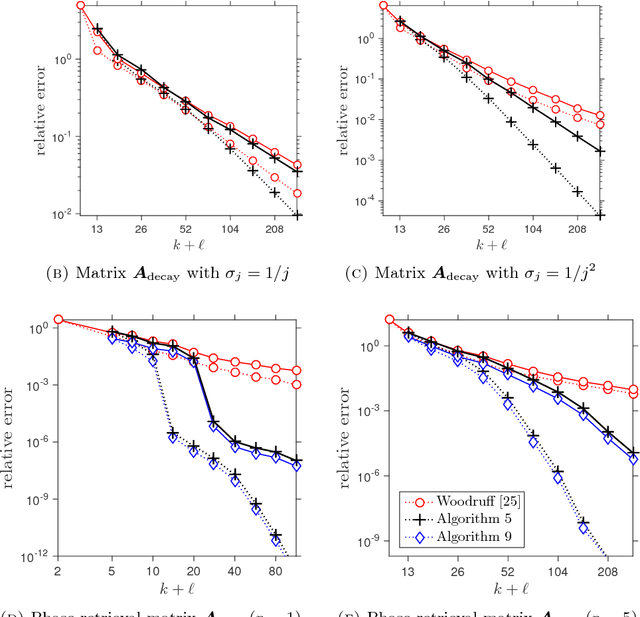
This paper describes a suite of algorithms for constructing low-rank approximations of an input matrix from a random linear image of the matrix, called a sketch. These methods can preserve structural properties of the input matrix, such as positive-semidefiniteness, and they can produce approximations with a user-specified rank. The algorithms are simple, accurate, numerically stable, and provably correct. Moreover, each method is accompanied by an informative error bound that allows users to select parameters a priori to achieve a given approximation quality. These claims are supported by numerical experiments with real and synthetic data.
Fixed-Rank Approximation of a Positive-Semidefinite Matrix from Streaming Data
Jun 18, 2017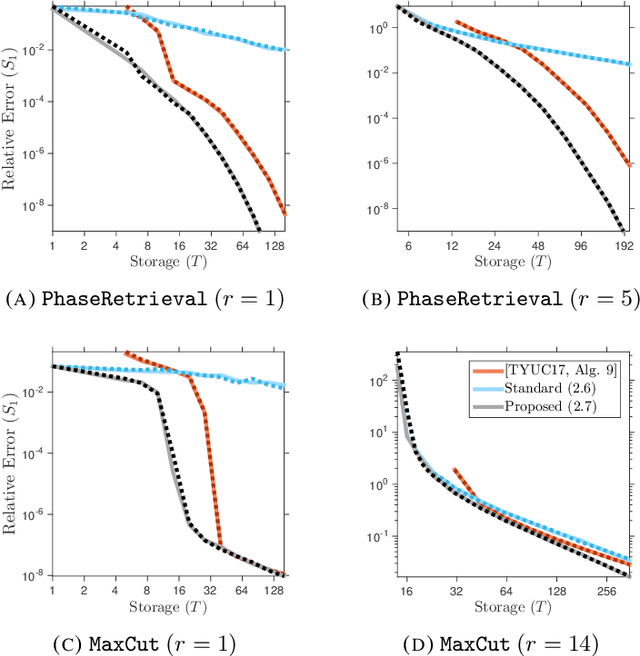
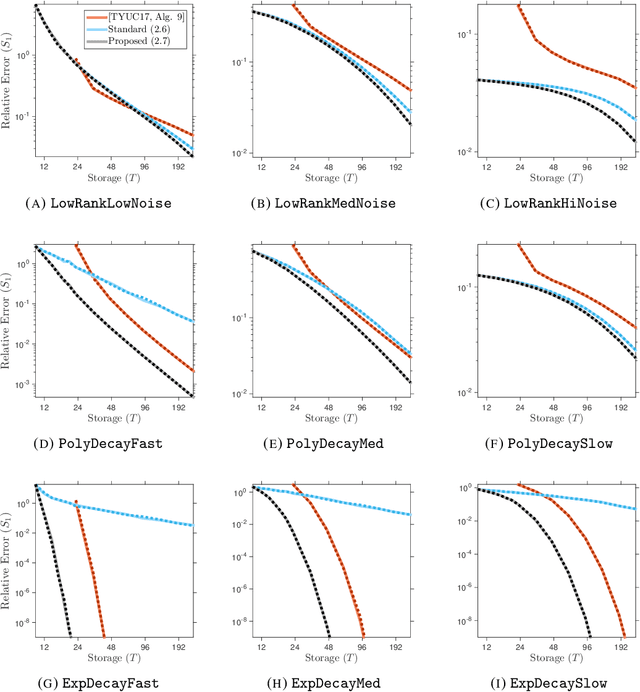
Several important applications, such as streaming PCA and semidefinite programming, involve a large-scale positive-semidefinite (psd) matrix that is presented as a sequence of linear updates. Because of storage limitations, it may only be possible to retain a sketch of the psd matrix. This paper develops a new algorithm for fixed-rank psd approximation from a sketch. The approach combines the Nystrom approximation with a novel mechanism for rank truncation. Theoretical analysis establishes that the proposed method can achieve any prescribed relative error in the Schatten 1-norm and that it exploits the spectral decay of the input matrix. Computer experiments show that the proposed method dominates alternative techniques for fixed-rank psd matrix approximation across a wide range of examples.
Sketchy Decisions: Convex Low-Rank Matrix Optimization with Optimal Storage
Feb 22, 2017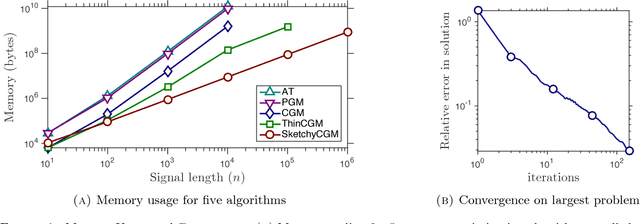


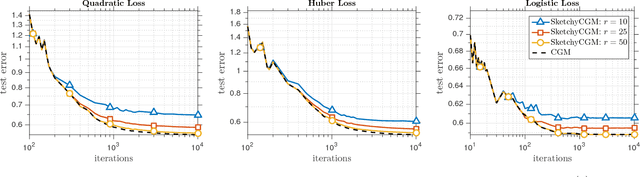
This paper concerns a fundamental class of convex matrix optimization problems. It presents the first algorithm that uses optimal storage and provably computes a low-rank approximation of a solution. In particular, when all solutions have low rank, the algorithm converges to a solution. This algorithm, SketchyCGM, modifies a standard convex optimization scheme, the conditional gradient method, to store only a small randomized sketch of the matrix variable. After the optimization terminates, the algorithm extracts a low-rank approximation of the solution from the sketch. In contrast to nonconvex heuristics, the guarantees for SketchyCGM do not rely on statistical models for the problem data. Numerical work demonstrates the benefits of SketchyCGM over heuristics.