 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAmit Sheth
REASONS: A benchmark for REtrieval and Automated citationS Of scieNtific Sentences using Public and Proprietary LLMs
May 03, 2024
Automatic citation generation for sentences in a document or report is paramount for intelligence analysts, cybersecurity, news agencies, and education personnel. In this research, we investigate whether large language models (LLMs) are capable of generating references based on two forms of sentence queries: (a) Direct Queries, LLMs are asked to provide author names of the given research article, and (b) Indirect Queries, LLMs are asked to provide the title of a mentioned article when given a sentence from a different article. To demonstrate where LLM stands in this task, we introduce a large dataset called REASONS comprising abstracts of the 12 most popular domains of scientific research on arXiv. From around 20K research articles, we make the following deductions on public and proprietary LLMs: (a) State-of-the-art, often called anthropomorphic GPT-4 and GPT-3.5, suffers from high pass percentage (PP) to minimize the hallucination rate (HR). When tested with Perplexity.ai (7B), they unexpectedly made more errors; (b) Augmenting relevant metadata lowered the PP and gave the lowest HR; (c) Advance retrieval-augmented generation (RAG) using Mistral demonstrates consistent and robust citation support on indirect queries and matched performance to GPT-3.5 and GPT-4. The HR across all domains and models decreased by an average of 41.93% and the PP was reduced to 0% in most cases. In terms of generation quality, the average F1 Score and BLEU were 68.09% and 57.51%, respectively; (d) Testing with adversarial samples showed that LLMs, including the Advance RAG Mistral, struggle to understand context, but the extent of this issue was small in Mistral and GPT-4-Preview. Our study con tributes valuable insights into the reliability of RAG for automated citation generation tasks.
Visual Hallucination: Definition, Quantification, and Prescriptive Remediations
Mar 31, 2024
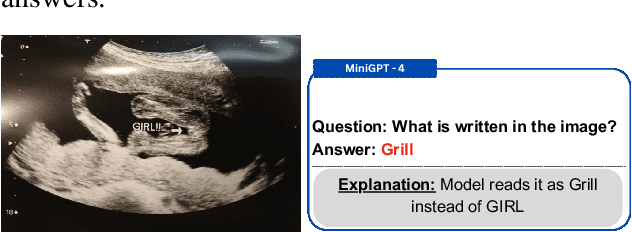


The troubling rise of hallucination presents perhaps the most significant impediment to the advancement of responsible AI. In recent times, considerable research has focused on detecting and mitigating hallucination in Large Language Models (LLMs). However, it's worth noting that hallucination is also quite prevalent in Vision-Language models (VLMs). In this paper, we offer a fine-grained discourse on profiling VLM hallucination based on two tasks: i) image captioning, and ii) Visual Question Answering (VQA). We delineate eight fine-grained orientations of visual hallucination: i) Contextual Guessing, ii) Identity Incongruity, iii) Geographical Erratum, iv) Visual Illusion, v) Gender Anomaly, vi) VLM as Classifier, vii) Wrong Reading, and viii) Numeric Discrepancy. We curate Visual HallucInation eLiciTation (VHILT), a publicly available dataset comprising 2,000 samples generated using eight VLMs across two tasks of captioning and VQA along with human annotations for the categories as mentioned earlier.
Grounding from an AI and Cognitive Science Lens
Feb 19, 2024Grounding is a challenging problem, requiring a formal definition and different levels of abstraction. This article explores grounding from both cognitive science and machine learning perspectives. It identifies the subtleties of grounding, its significance for collaborative agents, and similarities and differences in grounding approaches in both communities. The article examines the potential of neuro-symbolic approaches tailored for grounding tasks, showcasing how they can more comprehensively address grounding. Finally, we discuss areas for further exploration and development in grounding.
On the Prospects of Incorporating Large Language Models (LLMs) in Automated Planning and Scheduling (APS)
Jan 04, 2024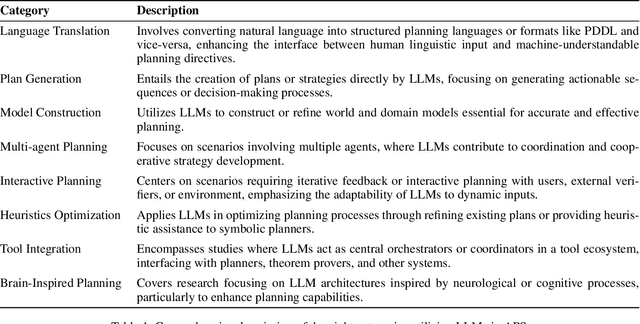

Automated Planning and Scheduling is among the growing areas in Artificial Intelligence (AI) where mention of LLMs has gained popularity. Based on a comprehensive review of 126 papers, this paper investigates eight categories based on the unique applications of LLMs in addressing various aspects of planning problems: language translation, plan generation, model construction, multi-agent planning, interactive planning, heuristics optimization, tool integration, and brain-inspired planning. For each category, we articulate the issues considered and existing gaps. A critical insight resulting from our review is that the true potential of LLMs unfolds when they are integrated with traditional symbolic planners, pointing towards a promising neuro-symbolic approach. This approach effectively combines the generative aspects of LLMs with the precision of classical planning methods. By synthesizing insights from existing literature, we underline the potential of this integration to address complex planning challenges. Our goal is to encourage the ICAPS community to recognize the complementary strengths of LLMs and symbolic planners, advocating for a direction in automated planning that leverages these synergistic capabilities to develop more advanced and intelligent planning systems.
Neurosymbolic Value-Inspired AI (Why, What, and How)
Dec 15, 2023The rapid progression of Artificial Intelligence (AI) systems, facilitated by the advent of Large Language Models (LLMs), has resulted in their widespread application to provide human assistance across diverse industries. This trend has sparked significant discourse centered around the ever-increasing need for LLM-based AI systems to function among humans as part of human society, sharing human values, especially as these systems are deployed in high-stakes settings (e.g., healthcare, autonomous driving, etc.). Towards this end, neurosymbolic AI systems are attractive due to their potential to enable easy-to-understand and interpretable interfaces for facilitating value-based decision-making, by leveraging explicit representations of shared values. In this paper, we introduce substantial extensions to Khaneman's System one/two framework and propose a neurosymbolic computational framework called Value-Inspired AI (VAI). It outlines the crucial components essential for the robust and practical implementation of VAI systems, aiming to represent and integrate various dimensions of human values. Finally, we further offer insights into the current progress made in this direction and outline potential future directions for the field.
RDR: the Recap, Deliberate, and Respond Method for Enhanced Language Understanding
Dec 15, 2023Natural language understanding (NLU) using neural network pipelines often requires additional context that is not solely present in the input data. Through Prior research, it has been evident that NLU benchmarks are susceptible to manipulation by neural models, wherein these models exploit statistical artifacts within the encoded external knowledge to artificially inflate performance metrics for downstream tasks. Our proposed approach, known as the Recap, Deliberate, and Respond (RDR) paradigm, addresses this issue by incorporating three distinct objectives within the neural network pipeline. Firstly, the Recap objective involves paraphrasing the input text using a paraphrasing model in order to summarize and encapsulate its essence. Secondly, the Deliberation objective entails encoding external graph information related to entities mentioned in the input text, utilizing a graph embedding model. Finally, the Respond objective employs a classification head model that utilizes representations from the Recap and Deliberation modules to generate the final prediction. By cascading these three models and minimizing a combined loss, we mitigate the potential for gaming the benchmark and establish a robust method for capturing the underlying semantic patterns, thus enabling accurate predictions. To evaluate the effectiveness of the RDR method, we conduct tests on multiple GLUE benchmark tasks. Our results demonstrate improved performance compared to competitive baselines, with an enhancement of up to 2\% on standard metrics. Furthermore, we analyze the observed evidence for semantic understanding exhibited by RDR models, emphasizing their ability to avoid gaming the benchmark and instead accurately capture the true underlying semantic patterns.
GEAR-Up: Generative AI and External Knowledge-based Retrieval Upgrading Scholarly Article Searches for Systematic Reviews
Dec 15, 2023Systematic reviews (SRs) - the librarian-assisted literature survey of scholarly articles takes time and requires significant human resources. Given the ever-increasing volume of published studies, applying existing computing and informatics technology can decrease this time and resource burden. Due to the revolutionary advances in (1) Generative AI such as ChatGPT, and (2) External knowledge-augmented information extraction efforts such as Retrieval-Augmented Generation, In this work, we explore the use of techniques from (1) and (2) for SR. We demonstrate a system that takes user queries, performs query expansion to obtain enriched context (includes additional terms and definitions by querying language models and knowledge graphs), and uses this context to search for articles on scholarly databases to retrieve articles. We perform qualitative evaluations of our system through comparison against sentinel (ground truth) articles provided by an in-house librarian. The demo can be found at: https://youtu.be/zMdP56GJ9mU.
SEPSIS: I Can Catch Your Lies -- A New Paradigm for Deception Detection
Dec 01, 2023Deception is the intentional practice of twisting information. It is a nuanced societal practice deeply intertwined with human societal evolution, characterized by a multitude of facets. This research explores the problem of deception through the lens of psychology, employing a framework that categorizes deception into three forms: lies of omission, lies of commission, and lies of influence. The primary focus of this study is specifically on investigating only lies of omission. We propose a novel framework for deception detection leveraging NLP techniques. We curated an annotated dataset of 876,784 samples by amalgamating a popular large-scale fake news dataset and scraped news headlines from the Twitter handle of Times of India, a well-known Indian news media house. Each sample has been labeled with four layers, namely: (i) the type of omission (speculation, bias, distortion, sounds factual, and opinion), (ii) colors of lies(black, white, etc), and (iii) the intention of such lies (to influence, etc) (iv) topic of lies (political, educational, religious, etc). We present a novel multi-task learning pipeline that leverages the dataless merging of fine-tuned language models to address the deception detection task mentioned earlier. Our proposed model achieved an F1 score of 0.87, demonstrating strong performance across all layers including the type, color, intent, and topic aspects of deceptive content. Finally, our research explores the relationship between lies of omission and propaganda techniques. To accomplish this, we conducted an in-depth analysis, uncovering compelling findings. For instance, our analysis revealed a significant correlation between loaded language and opinion, shedding light on their interconnectedness. To encourage further research in this field, we will be making the models and dataset available with the MIT License, making it favorable for open-source research.
L3 Ensembles: Lifelong Learning Approach for Ensemble of Foundational Language Models
Nov 11, 2023Fine-tuning pre-trained foundational language models (FLM) for specific tasks is often impractical, especially for resource-constrained devices. This necessitates the development of a Lifelong Learning (L3) framework that continuously adapts to a stream of Natural Language Processing (NLP) tasks efficiently. We propose an approach that focuses on extracting meaningful representations from unseen data, constructing a structured knowledge base, and improving task performance incrementally. We conducted experiments on various NLP tasks to validate its effectiveness, including benchmarks like GLUE and SuperGLUE. We measured good performance across the accuracy, training efficiency, and knowledge transfer metrics. Initial experimental results show that the proposed L3 ensemble method increases the model accuracy by 4% ~ 36% compared to the fine-tuned FLM. Furthermore, L3 model outperforms naive fine-tuning approaches while maintaining competitive or superior performance (up to 15.4% increase in accuracy) compared to the state-of-the-art language model (T5) for the given task, STS benchmark.
Exploring the Relationship between Analogy Identification and Sentence Structure Encoding in Large Language Models
Oct 13, 2023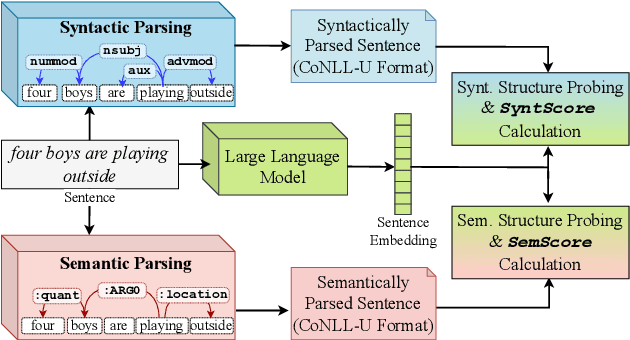

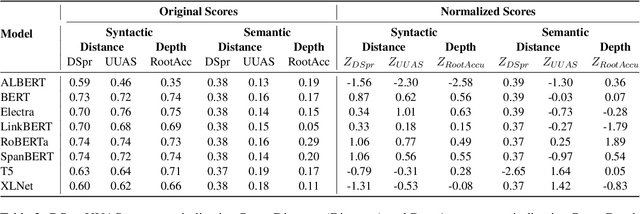
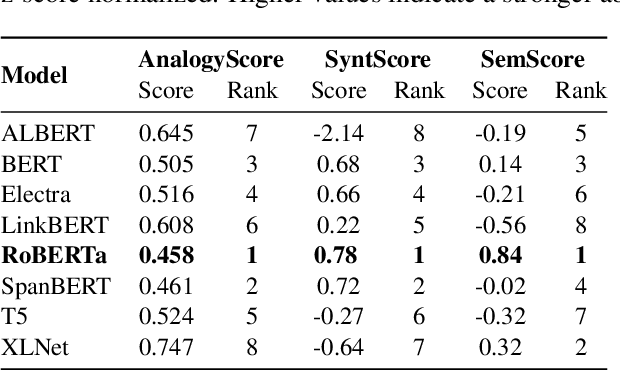
Identifying analogies plays a pivotal role in human cognition and language proficiency. In the last decade, there has been extensive research on word analogies in the form of ``A is to B as C is to D.'' However, there is a growing interest in analogies that involve longer text, such as sentences and collections of sentences, which convey analogous meanings. While the current NLP research community evaluates the ability of Large Language Models (LLMs) to identify such analogies, the underlying reasons behind these abilities warrant deeper investigation. Furthermore, the capability of LLMs to encode both syntactic and semantic structures of language within their embeddings has garnered significant attention with the surge in their utilization. In this work, we examine the relationship between the abilities of multiple LLMs to identify sentence analogies, and their capacity to encode syntactic and semantic structures. Through our analysis, we find that analogy identification ability of LLMs is positively correlated with their ability to encode syntactic and semantic structures of sentences. Specifically, we find that the LLMs which capture syntactic structures better, also have higher abilities in identifying sentence analogies.