 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAmlan Chakrabarti
SoccerKDNet: A Knowledge Distillation Framework for Action Recognition in Soccer Videos
Jul 22, 2023

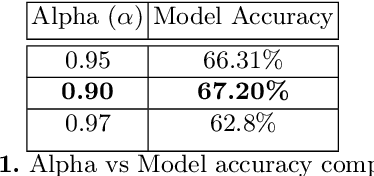
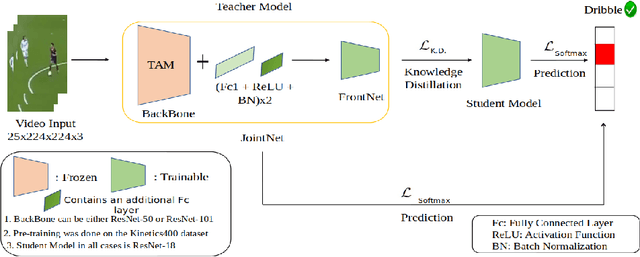
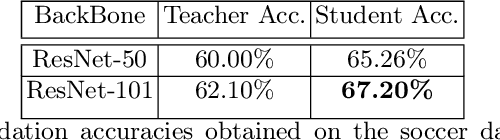
Classifying player actions from soccer videos is a challenging problem, which has become increasingly important in sports analytics over the years. Most state-of-the-art methods employ highly complex offline networks, which makes it difficult to deploy such models in resource constrained scenarios. Here, in this paper we propose a novel end-to-end knowledge distillation based transfer learning network pre-trained on the Kinetics400 dataset and then perform extensive analysis on the learned framework by introducing a unique loss parameterization. We also introduce a new dataset named SoccerDB1 containing 448 videos and consisting of 4 diverse classes each of players playing soccer. Furthermore, we introduce an unique loss parameter that help us linearly weigh the extent to which the predictions of each network are utilized. Finally, we also perform a thorough performance study using various changed hyperparameters. We also benchmark the first classification results on the new SoccerDB1 dataset obtaining 67.20% validation accuracy. Apart from outperforming prior arts significantly, our model also generalizes to new datasets easily. The dataset has been made publicly available at: https://bit.ly/soccerdb1
Fast 3D Volumetric Image Reconstruction from 2D MRI Slices by Parallel Processing
Mar 16, 2023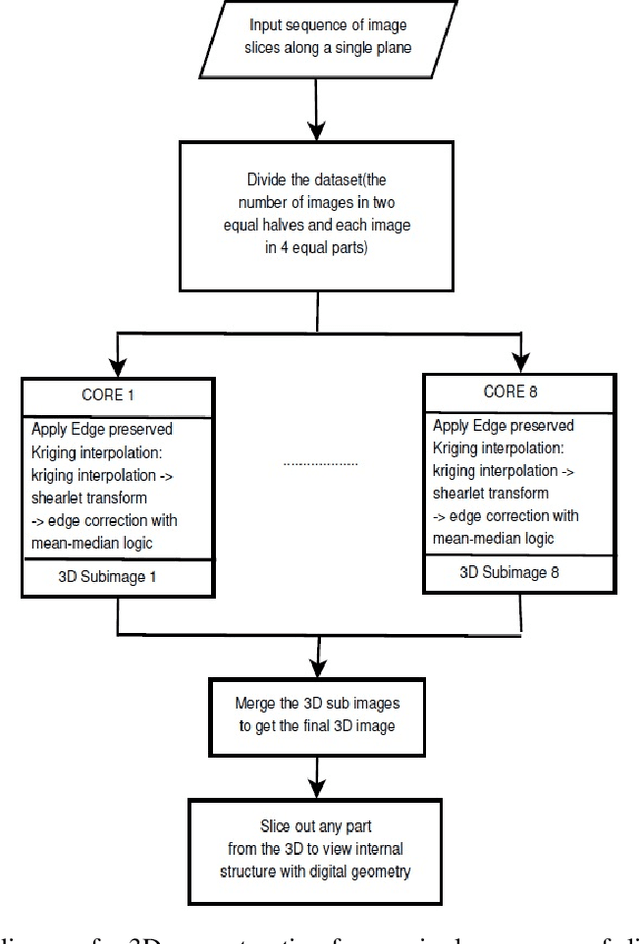
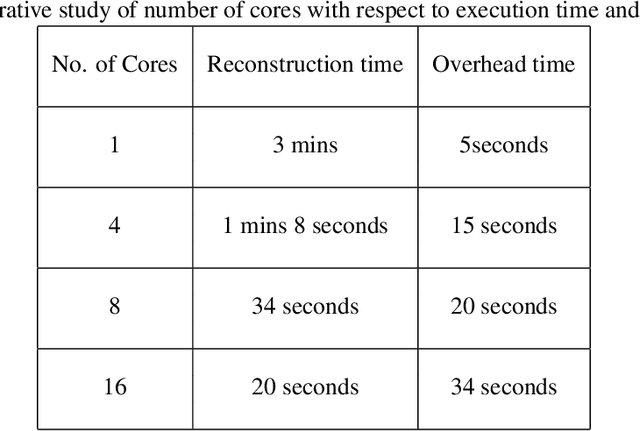
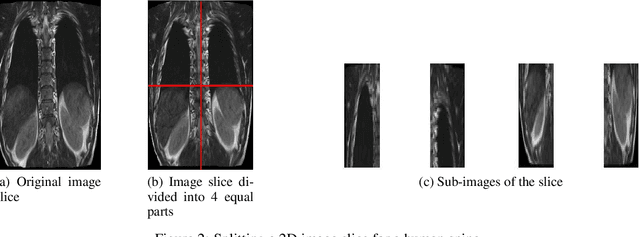

Magnetic Resonance Imaging (MRI) is a technology for non-invasive imaging of anatomical features in detail. It can help in functional analysis of organs of a specimen but it is very costly. In this work, methods for (i) virtual three-dimensional (3D) reconstruction from a single sequence of two-dimensional (2D) slices of MR images of a human spine and brain along a single axis, and (ii) generation of missing inter-slice data are proposed. Our approach helps in preserving the edges, shape, size, as well as the internal tissue structures of the object being captured. The sequence of original 2D slices along a single axis is divided into smaller equal sub-parts which are then reconstructed using edge preserved kriging interpolation to predict the missing slice information. In order to speed up the process of interpolation, we have used multiprocessing by carrying out the initial interpolation on parallel cores. From the 3D matrix thus formed, shearlet transform is applied to estimate the edges considering the 2D blocks along the $Z$ axis, and to minimize the blurring effect using a proposed mean-median logic. Finally, for visualization, the sub-matrices are merged into a final 3D matrix. Next, the newly formed 3D matrix is split up into voxels and marching cubes method is applied to get the approximate 3D image for viewing. To the best of our knowledge it is a first of its kind approach based on kriging interpolation and multiprocessing for 3D reconstruction from 2D slices, and approximately 98.89\% accuracy is achieved with respect to similarity metrics for image comparison. The time required for reconstruction has also been reduced by approximately 70\% with multiprocessing even for a large input data set compared to that with single core processing.
IoT based Smart Access Controlled Secure Smart City Architecture Using Blockchain
Sep 09, 2019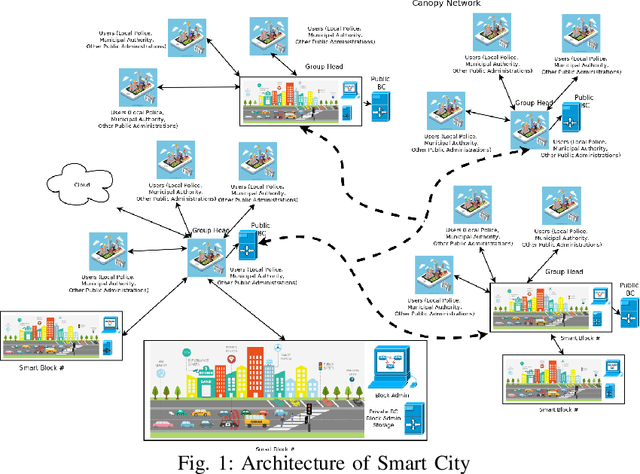
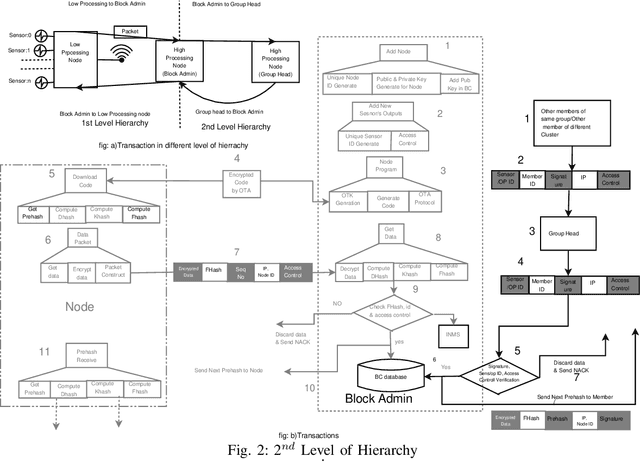
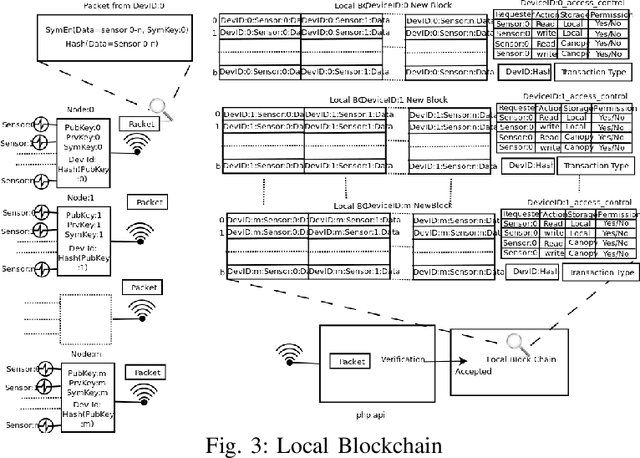
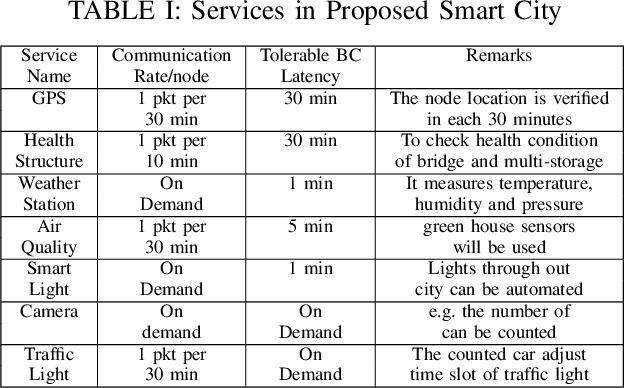
Standard security protocols like SSL, TLS, IPSec etc. have high memory and processor consumption which makes all these security protocols unsuitable for resource constrained platforms such as Internet of Things (IoT). Blockchain (BC) finds its efficient application in IoT platform to preserve the five basic cryptographic primitives, such as confidentiality, authenticity, integrity, availability and non-repudiation. Conventional adoption of BC in IoT platform causes high energy consumption, delay and computational overhead which are not appropriate for various resource constrained IoT devices. This work proposes a machine learning (ML) based smart access control framework in a public and a private BC for a smart city application which makes it more efficient as compared to the existing IoT applications. The proposed IoT based smart city architecture adopts BC technology for preserving all the cryptographic security and privacy issues. Moreover, BC has very minimal overhead on IoT platform as well. This work investigates the existing threat models and critical access control issues which handle multiple permissions of various nodes and detects relevant inconsistencies to notify the corresponding nodes. Comparison in terms of all security issues with existing literature shows that the proposed architecture is competitively efficient in terms of security access control.
A Novel Approach for Human Action Recognition from Silhouette Images
Oct 15, 2015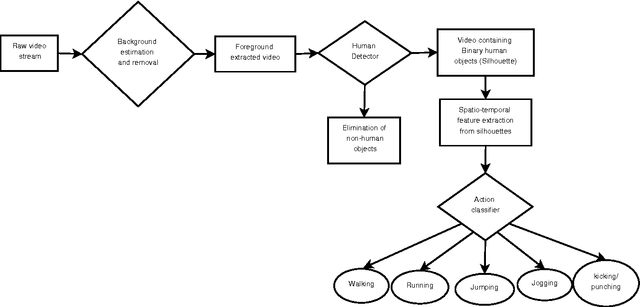
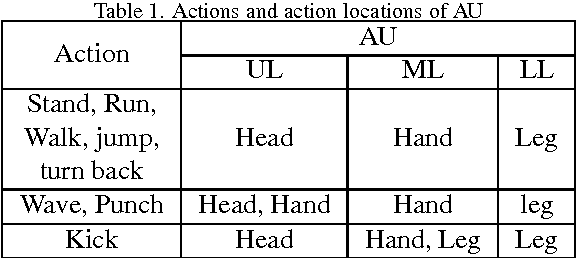
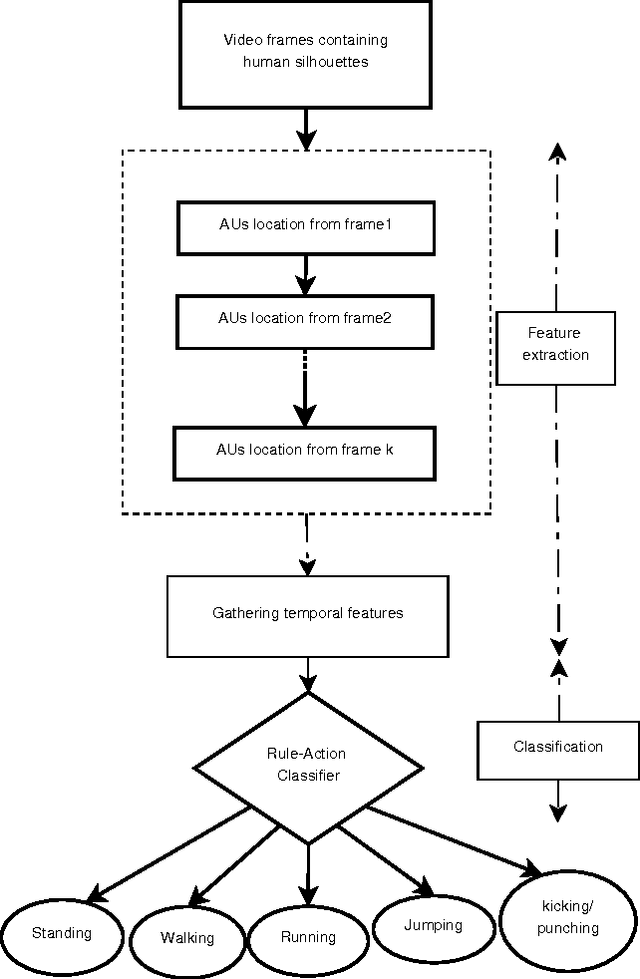
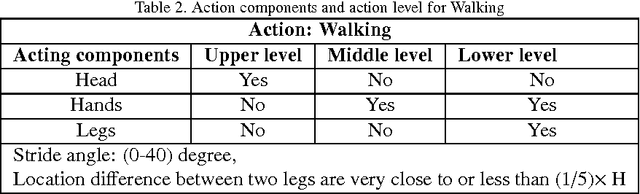
In this paper, a novel human action recognition technique from video is presented. Any action of human is a combination of several micro action sequences performed by one or more body parts of the human. The proposed approach uses spatio-temporal body parts movement (STBPM) features extracted from foreground silhouette of the human objects. The newly proposed STBPM feature estimates the movements of different body parts for any given time segment to classify actions. We also proposed a rule based logic named rule action classifier (RAC), which uses a series of condition action rules based on prior knowledge and hence does not required training to classify any action. Since we don't require training to classify actions, the proposed approach is view independent. The experimental results on publicly available Wizeman and MuHVAi datasets are compared with that of the related research work in terms of accuracy in the human action detection, and proposed technique outperforms the others.
A Brief Survey of Recent Edge-Preserving Smoothing Algorithms on Digital Images
Mar 25, 2015
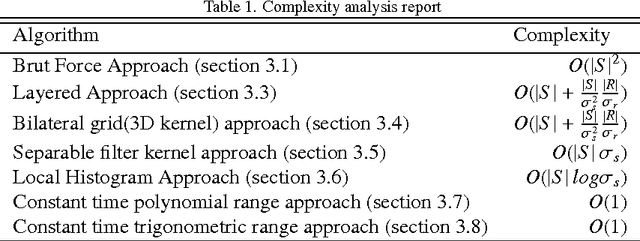

Edge preserving filters preserve the edges and its information while blurring an image. In other words they are used to smooth an image, while reducing the edge blurring effects across the edge like halos, phantom etc. They are nonlinear in nature. Examples are bilateral filter, anisotropic diffusion filter, guided filter, trilateral filter etc. Hence these family of filters are very useful in reducing the noise in an image making it very demanding in computer vision and computational photography applications like denoising, video abstraction, demosaicing, optical-flow estimation, stereo matching, tone mapping, style transfer, relighting etc. This paper provides a concrete introduction to edge preserving filters starting from the heat diffusion equation in olden to recent eras, an overview of its numerous applications, as well as mathematical analysis, various efficient and optimized ways of implementation and their interrelationships, keeping focus on preserving the boundaries, spikes and canyons in presence of noise. Furthermore it provides a realistic notion for efficient implementation with a research scope for hardware realization for further acceleration.
An Approach for Reducing Outliers of Non Local Means Image Denoising Filter
Dec 09, 2014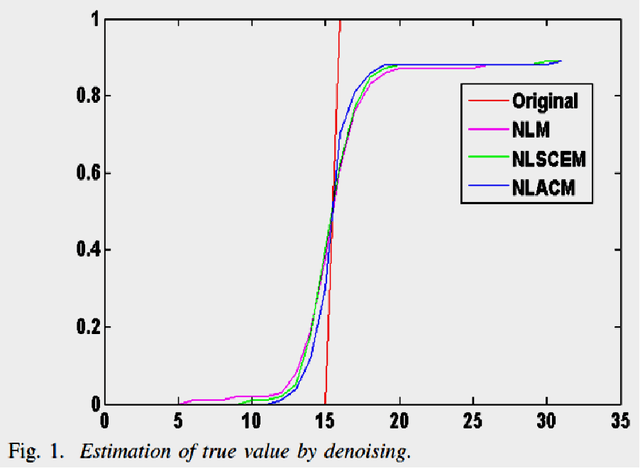
We propose an adaptive approach for non local means (NLM) image filtering termed as non local adaptive clipped means (NLACM), which reduces the effect of outliers and improves the denoising quality as compared to traditional NLM. Common method to neglect outliers from a data population is computation of mean in a range defined by mean and standard deviation. In NLACM we perform the median within the defined range based on statistical estimation of the neighbourhood region of a pixel to be denoised. As parameters of the range are independent of any additional input and is based on local intensity values, hence the approach is adaptive. Experimental results for NLACM show better estimation of true intensity from noisy neighbourhood observation as compared to NLM at high noise levels. We have verified the technique for speckle noise reduction and we have tested it on ultrasound (US) image of lumbar spine. These ultrasound images act as guidance for injection therapy for treatment of lumbar radiculopathy. We believe that the proposed approach for image denoising is first of its kind and its efficiency can be well justified as it shows better performance in image restoration.
Cobb Angle Measurement of Scoliosis with Reduced Variability
Nov 22, 2012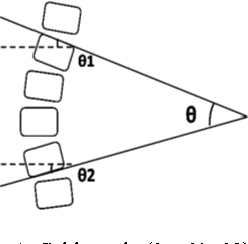
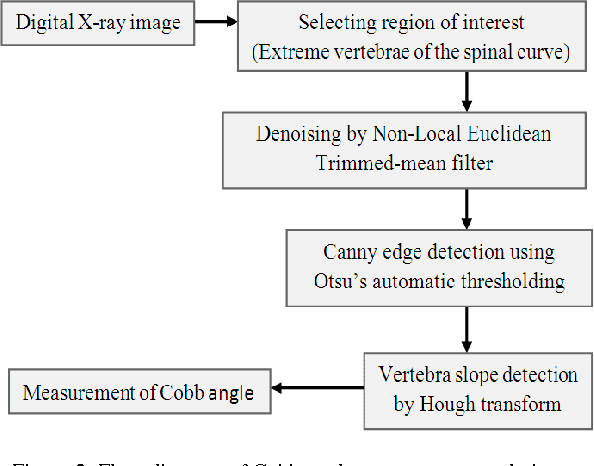
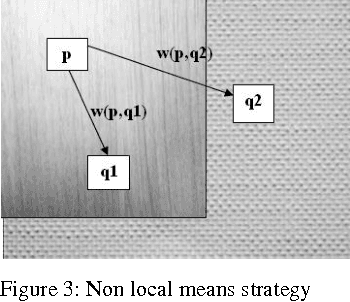
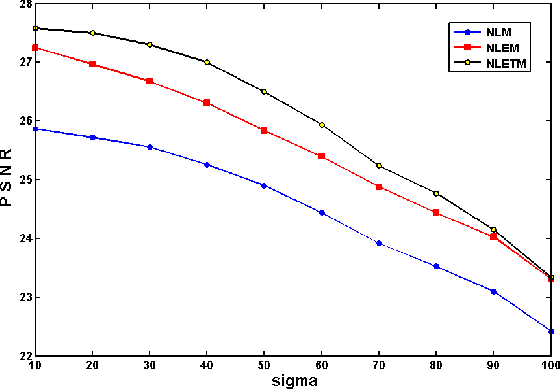
Cobb angle, which is a measure of spinal curvature is the standard method for quantifying the magnitude of Scoliosis related to spinal deformity in orthopedics. Determining the Cobb angle through manual process is subject to human errors. In this work, we propose a methodology to measure the magnitude of Cobb angle, which appreciably reduces the variability related to its measurement compared to the related works. The proposed methodology is facilitated by using a suitable new improved version of Non-Local Means for image denoisation and Otsus automatic threshold selection for Canny edge detection. We have selected NLM for preprocessing of the image as it is one of the fine states of art for image denoisation and helps in retaining the image quality. Trimmedmean, median are more robust to outliners than mean and following this concept we observed that NLM denoising quality performance can be enhanced by using Euclidean trimmed-mean replacing the mean. To prove the better performance of the Non-Local Euclidean Trimmed-mean denoising filter, we have provided some comparative study results of the proposed denoising technique with traditional NLM and NonLocal Euclidean Medians. The experimental results for Cobb angle measurement over intra observer and inter observer experimental data reveals the better performance and superiority of the proposed approach compared to the related works. MATLAB2009b image processing toolbox was used for the purpose of simulation and verification of the proposed methodology.
Multiple View Reconstruction of Calibrated Images using Singular Value Decomposition
Nov 02, 2010
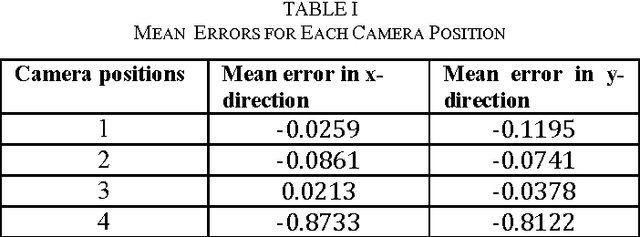
Calibration in a multi camera network has widely been studied for over several years starting from the earlier days of photogrammetry. Many authors have presented several calibration algorithms with their relative advantages and disadvantages. In a stereovision system, multiple view reconstruction is a challenging task. However, the total computational procedure in detail has not been presented before. Here in this work, we are dealing with the problem that, when a world coordinate point is fixed in space, image coordinates of that 3D point vary for different camera positions and orientations. In computer vision aspect, this situation is undesirable. That is, the system has to be designed in such a way that image coordinate of the world coordinate point will be fixed irrespective of the position & orientation of the cameras. We have done it in an elegant fashion. Firstly, camera parameters are calculated in its local coordinate system. Then, we use global coordinate data to transfer all local coordinate data of stereo cameras into same global coordinate system, so that we can register everything into this global coordinate system. After all the transformations, when the image coordinate of the world coordinate point is calculated, it gives same coordinate value for all camera positions & orientations. That is, the whole system is calibrated.