 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAmr Adel Helmy
A Multilingual Encoding Method for Text Classification and Dialect Identification Using Convolutional Neural Network
Mar 18, 2019
This thesis presents a language-independent text classification model by introduced two new encoding methods "BUNOW" and "BUNOC" used for feeding the raw text data into a new CNN spatial architecture with vertical and horizontal convolutional process instead of commonly used methods like one hot vector or word representation (i.e. word2vec) with temporal CNN architecture. The proposed model can be classified as hybrid word-character model in its work methodology because it consumes less memory space by using a fewer neural network parameters as in character level representation, in addition to providing much faster computations with fewer network layers depth, as in word level representation. A promising result achieved compared to state of art models in two different morphological benchmarked dataset one for Arabic language and one for English language.
An Innovative Word Encoding Method For Text Classification Using Convolutional Neural Network
Mar 11, 2019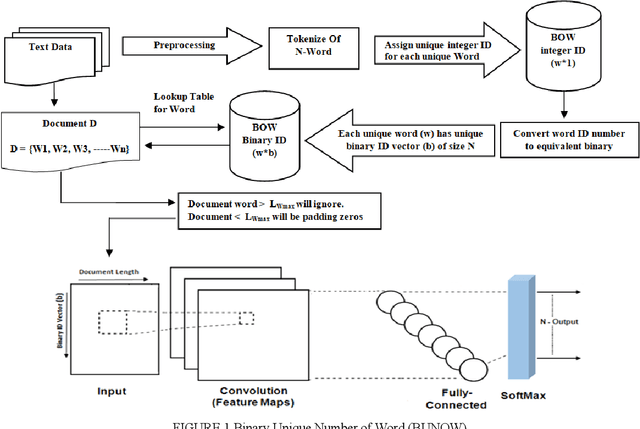
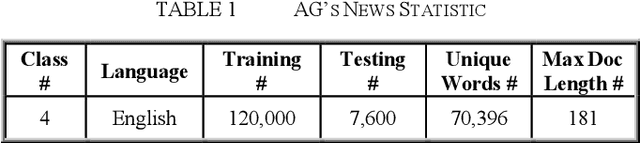
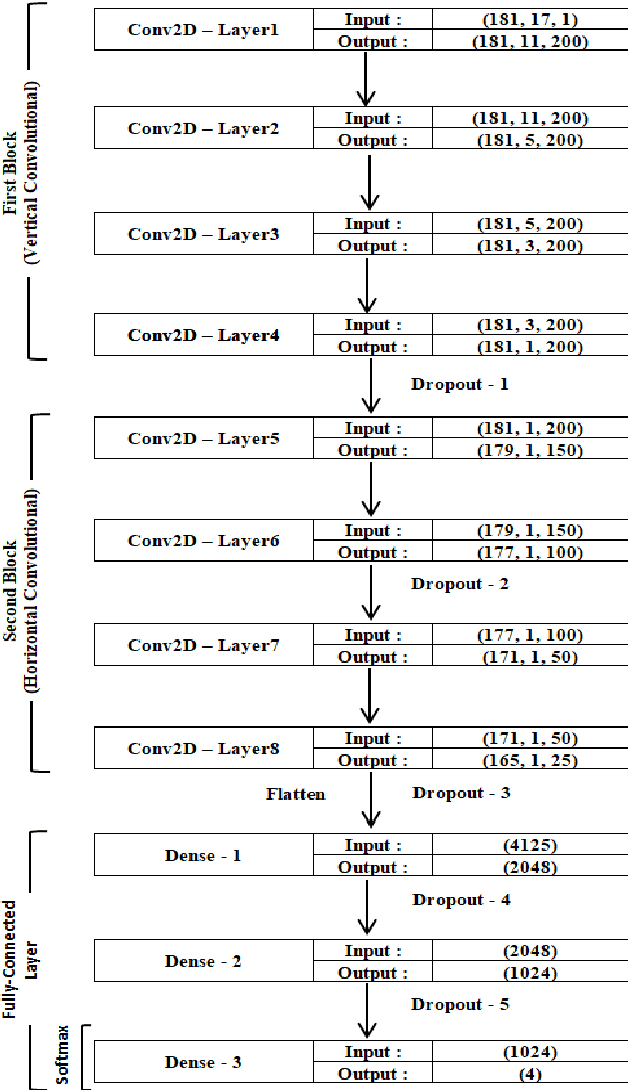
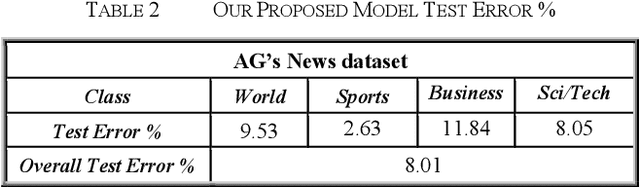
Text classification plays a vital role today especially with the intensive use of social networking media. Recently, different architectures of convolutional neural networks have been used for text classification in which one-hot vector, and word embedding methods are commonly used. This paper presents a new language independent word encoding method for text classification. The proposed model converts raw text data to low-level feature dimension with minimal or no preprocessing steps by using a new approach called binary unique number of word "BUNOW". BUNOW allows each unique word to have an integer ID in a dictionary that is represented as a k-dimensional vector of its binary equivalent. The output vector of this encoding is fed into a convolutional neural network (CNN) model for classification. Moreover, the proposed model reduces the neural network parameters, allows faster computation with few network layers, where a word is atomic representation the document as in word level, and decrease memory consumption for character level representation. The provided CNN model is able to work with other languages or multi-lingual text without the need for any changes in the encoding method. The model outperforms the character level and very deep character level CNNs models in terms of accuracy, network parameters, and memory consumption; the results show total classification accuracy 91.99% and error 8.01% using AG's News dataset compared to the state of art methods that have total classification accuracy 91.45% and error 8.55%, in addition to the reduction in input feature vector and neural network parameters by 62% and 34%, respectively.