 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnastasiya Belyaeva
Multimodal LLMs for health grounded in individual-specific data
Jul 20, 2023
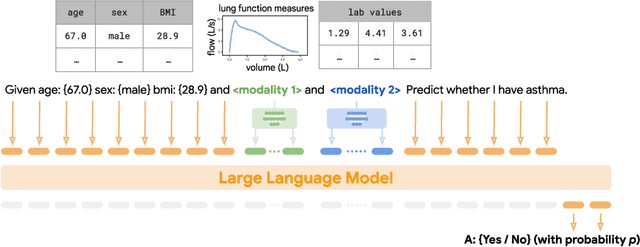
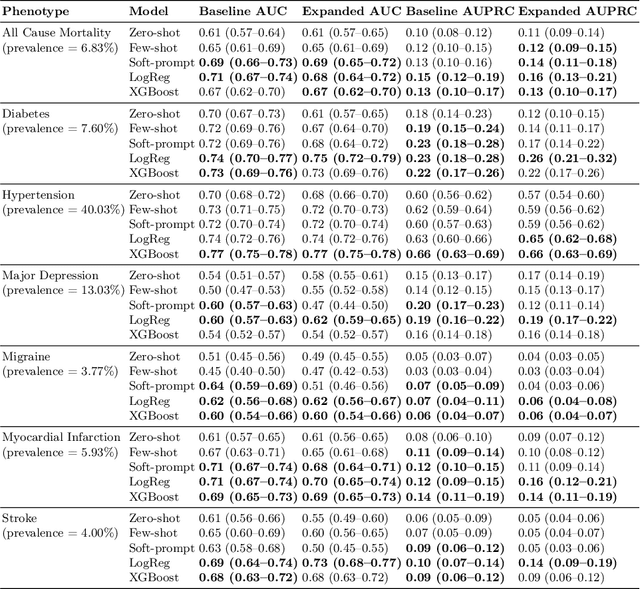
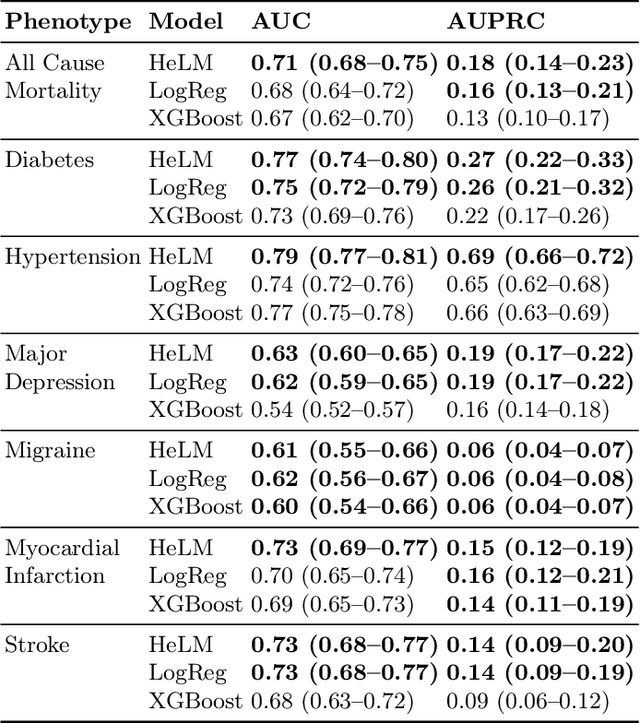
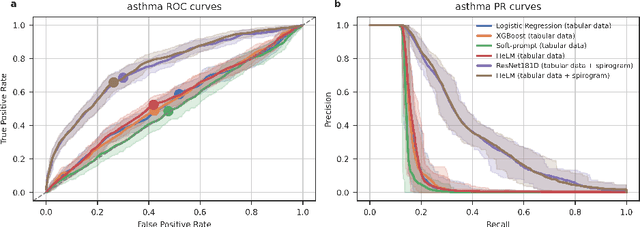
Foundation large language models (LLMs) have shown an impressive ability to solve tasks across a wide range of fields including health. To effectively solve personalized health tasks, LLMs need the ability to ingest a diversity of data modalities that are relevant to an individual's health status. In this paper, we take a step towards creating multimodal LLMs for health that are grounded in individual-specific data by developing a framework (HeLM: Health Large Language Model for Multimodal Understanding) that enables LLMs to use high-dimensional clinical modalities to estimate underlying disease risk. HeLM encodes complex data modalities by learning an encoder that maps them into the LLM's token embedding space and for simple modalities like tabular data by serializing the data into text. Using data from the UK Biobank, we show that HeLM can effectively use demographic and clinical features in addition to high-dimensional time-series data to estimate disease risk. For example, HeLM achieves an AUROC of 0.75 for asthma prediction when combining tabular and spirogram data modalities compared with 0.49 when only using tabular data. Overall, we find that HeLM outperforms or performs at parity with classical machine learning approaches across a selection of eight binary traits. Furthermore, we investigate the downstream uses of this model such as its generalizability to out-of-distribution traits and its ability to power conversations around individual health and wellness.
Knowledge distillation for fast and accurate DNA sequence correction
Nov 17, 2022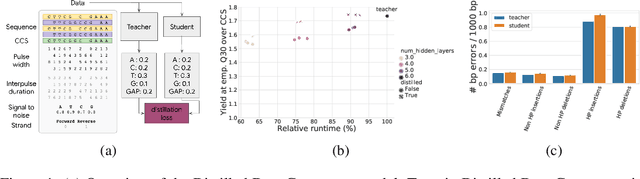

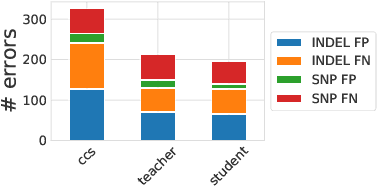
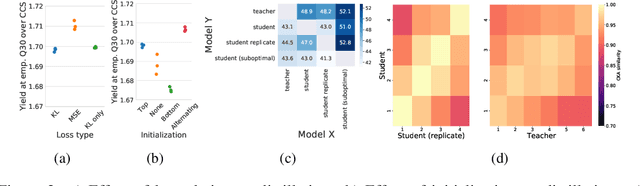
Accurate genome sequencing can improve our understanding of biology and the genetic basis of disease. The standard approach for generating DNA sequences from PacBio instruments relies on HMM-based models. Here, we introduce Distilled DeepConsensus - a distilled transformer-encoder model for sequence correction, which improves upon the HMM-based methods with runtime constraints in mind. Distilled DeepConsensus is 1.3x faster and 1.5x smaller than its larger counterpart while improving the yield of high quality reads (Q30) over the HMM-based method by 1.69x (vs. 1.73x for larger model). With improved accuracy of genomic sequences, Distilled DeepConsensus improves downstream applications of genomic sequence analysis such as reducing variant calling errors by 39% (34% for larger model) and improving genome assembly quality by 3.8% (4.2% for larger model). We show that the representations learned by Distilled DeepConsensus are similar between faster and slower models.