 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAndi Han
A Framework for Bilevel Optimization on Riemannian Manifolds
Feb 06, 2024
Bilevel optimization has seen an increasing presence in various domains of applications. In this work, we propose a framework for solving bilevel optimization problems where variables of both lower and upper level problems are constrained on Riemannian manifolds. We provide several hypergradient estimation strategies on manifolds and study their estimation error. We provide convergence and complexity analysis for the proposed hypergradient descent algorithm on manifolds. We also extend the developments to stochastic bilevel optimization and to the use of general retraction. We showcase the utility of the proposed framework on various applications.
Design Your Own Universe: A Physics-Informed Agnostic Method for Enhancing Graph Neural Networks
Feb 05, 2024Physics-informed Graph Neural Networks have achieved remarkable performance in learning through graph-structured data by mitigating common GNN challenges such as over-smoothing, over-squashing, and heterophily adaption. Despite these advancements, the development of a simple yet effective paradigm that appropriately integrates previous methods for handling all these challenges is still underway. In this paper, we draw an analogy between the propagation of GNNs and particle systems in physics, proposing a model-agnostic enhancement framework. This framework enriches the graph structure by introducing additional nodes and rewiring connections with both positive and negative weights, guided by node labeling information. We theoretically verify that GNNs enhanced through our approach can effectively circumvent the over-smoothing issue and exhibit robustness against over-squashing. Moreover, we conduct a spectral analysis on the rewired graph to demonstrate that the corresponding GNNs can fit both homophilic and heterophilic graphs. Empirical validations on benchmarks for homophilic, heterophilic graphs, and long-term graph datasets show that GNNs enhanced by our method significantly outperform their original counterparts.
SpecSTG: A Fast Spectral Diffusion Framework for Probabilistic Spatio-Temporal Traffic Forecasting
Jan 23, 2024Traffic forecasting, a crucial application of spatio-temporal graph (STG) learning, has traditionally relied on deterministic models for accurate point estimations. Yet, these models fall short of identifying latent risks of unexpected volatility in future observations. To address this gap, probabilistic methods, especially variants of diffusion models, have emerged as uncertainty-aware solutions. However, existing diffusion methods typically focus on generating separate future time series for individual sensors in the traffic network, resulting in insufficient involvement of spatial network characteristics in the probabilistic learning process. To better leverage spatial dependencies and systematic patterns inherent in traffic data, we propose SpecSTG, a novel spectral diffusion framework. Our method generates the Fourier representation of future time series, transforming the learning process into the spectral domain enriched with spatial information. Additionally, our approach incorporates a fast spectral graph convolution designed for Fourier input, alleviating the computational burden associated with existing models. Numerical experiments show that SpecSTG achieves outstanding performance with traffic flow and traffic speed datasets compared to state-of-the-art baselines. The source code for SpecSTG is available at https://anonymous.4open.science/r/SpecSTG.
Exposition on over-squashing problem on GNNs: Current Methods, Benchmarks and Challenges
Nov 17, 2023Graph-based message-passing neural networks (MPNNs) have achieved remarkable success in both node and graph-level learning tasks. However, several identified problems, including over-smoothing (OSM), limited expressive power, and over-squashing (OSQ), still limit the performance of MPNNs. In particular, OSQ serves as the latest identified problem, where MPNNs gradually lose their learning accuracy when long-range dependencies between graph nodes are required. In this work, we provide an exposition on the OSQ problem by summarizing different formulations of OSQ from current literature, as well as the three different categories of approaches for addressing the OSQ problem. In addition, we also discuss the alignment between OSQ and expressive power and the trade-off between OSQ and OSM. Furthermore, we summarize the empirical methods leveraged from existing works to verify the efficiency of OSQ mitigation approaches, with illustrations of their computational complexities. Lastly, we list some open questions that are of interest for further exploration of the OSQ problem along with potential directions from the best of our knowledge.
From Continuous Dynamics to Graph Neural Networks: Neural Diffusion and Beyond
Oct 29, 2023Graph neural networks (GNNs) have demonstrated significant promise in modelling relational data and have been widely applied in various fields of interest. The key mechanism behind GNNs is the so-called message passing where information is being iteratively aggregated to central nodes from their neighbourhood. Such a scheme has been found to be intrinsically linked to a physical process known as heat diffusion, where the propagation of GNNs naturally corresponds to the evolution of heat density. Analogizing the process of message passing to the heat dynamics allows to fundamentally understand the power and pitfalls of GNNs and consequently informs better model design. Recently, there emerges a plethora of works that proposes GNNs inspired from the continuous dynamics formulation, in an attempt to mitigate the known limitations of GNNs, such as oversmoothing and oversquashing. In this survey, we provide the first systematic and comprehensive review of studies that leverage the continuous perspective of GNNs. To this end, we introduce foundational ingredients for adapting continuous dynamics to GNNs, along with a general framework for the design of graph neural dynamics. We then review and categorize existing works based on their driven mechanisms and underlying dynamics. We also summarize how the limitations of classic GNNs can be addressed under the continuous framework. We conclude by identifying multiple open research directions.
Unifying over-smoothing and over-squashing in graph neural networks: A physics informed approach and beyond
Sep 13, 2023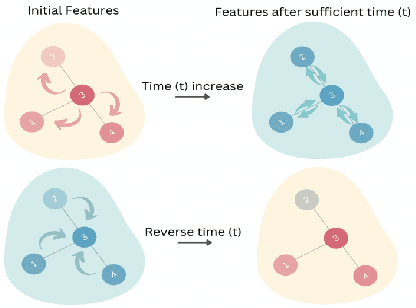
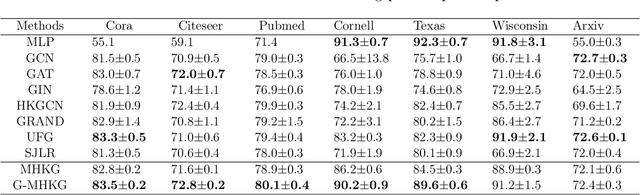
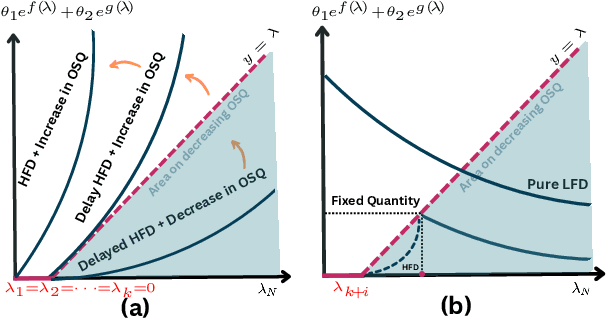
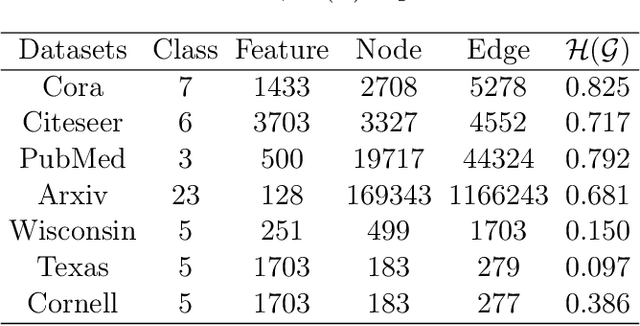
Graph Neural Networks (GNNs) have emerged as one of the leading approaches for machine learning on graph-structured data. Despite their great success, critical computational challenges such as over-smoothing, over-squashing, and limited expressive power continue to impact the performance of GNNs. In this study, inspired from the time-reversal principle commonly utilized in classical and quantum physics, we reverse the time direction of the graph heat equation. The resulted reversing process yields a class of high pass filtering functions that enhance the sharpness of graph node features. Leveraging this concept, we introduce the Multi-Scaled Heat Kernel based GNN (MHKG) by amalgamating diverse filtering functions' effects on node features. To explore more flexible filtering conditions, we further generalize MHKG into a model termed G-MHKG and thoroughly show the roles of each element in controlling over-smoothing, over-squashing and expressive power. Notably, we illustrate that all aforementioned issues can be characterized and analyzed via the properties of the filtering functions, and uncover a trade-off between over-smoothing and over-squashing: enhancing node feature sharpness will make model suffer more from over-squashing, and vice versa. Furthermore, we manipulate the time again to show how G-MHKG can handle both two issues under mild conditions. Our conclusive experiments highlight the effectiveness of proposed models. It surpasses several GNN baseline models in performance across graph datasets characterized by both homophily and heterophily.
Generalized Laplacian Regularized Framelet GCNs
Oct 27, 2022
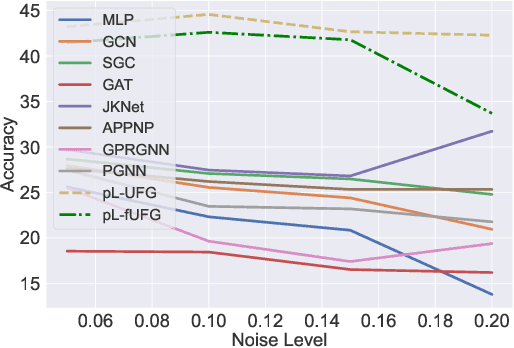
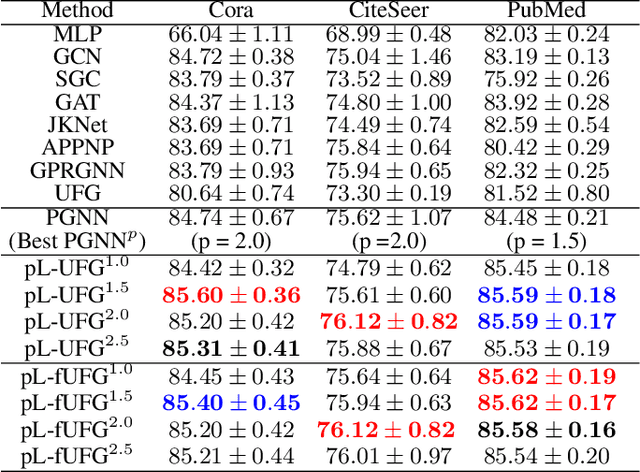

This paper introduces a novel Framelet Graph approach based on p-Laplacian GNN. The proposed two models, named p-Laplacian undecimated framelet graph convolution (pL-UFG) and generalized p-Laplacian undecimated framelet graph convolution (pL-fUFG) inherit the nature of p-Laplacian with the expressive power of multi-resolution decomposition of graph signals. The empirical study highlights the excellent performance of the pL-UFG and pL-fUFG in different graph learning tasks including node classification and signal denoising.
Rieoptax: Riemannian Optimization in JAX
Oct 10, 2022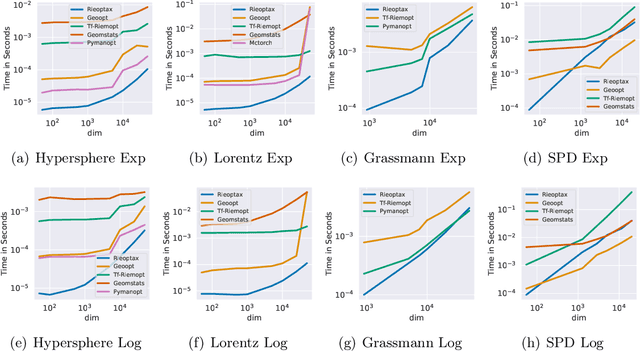


We present Rieoptax, an open source Python library for Riemannian optimization in JAX. We show that many differential geometric primitives, such as Riemannian exponential and logarithm maps, are usually faster in Rieoptax than existing frameworks in Python, both on CPU and GPU. We support various range of basic and advanced stochastic optimization solvers like Riemannian stochastic gradient, stochastic variance reduction, and adaptive gradient methods. A distinguishing feature of the proposed toolbox is that we also support differentially private optimization on Riemannian manifolds.
Generalized energy and gradient flow via graph framelets
Oct 08, 2022In this work, we provide a theoretical understanding of the framelet-based graph neural networks through the perspective of energy gradient flow. By viewing the framelet-based models as discretized gradient flows of some energy, we show it can induce both low-frequency and high-frequency-dominated dynamics, via the separate weight matrices for different frequency components. This substantiates its good empirical performance on both homophilic and heterophilic graphs. We then propose a generalized energy via framelet decomposition and show its gradient flow leads to a novel graph neural network, which includes many existing models as special cases. We then explain how the proposed model generally leads to more flexible dynamics, thus potentially enhancing the representation power of graph neural networks.
Riemannian accelerated gradient methods via extrapolation
Aug 13, 2022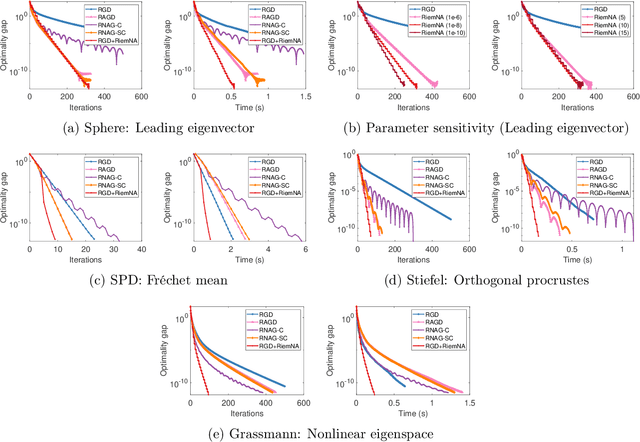
In this paper, we propose a simple acceleration scheme for Riemannian gradient methods by extrapolating iterates on manifolds. We show when the iterates are generated from Riemannian gradient descent method, the accelerated scheme achieves the optimal convergence rate asymptotically and is computationally more favorable than the recently proposed Riemannian Nesterov accelerated gradient methods. Our experiments verify the practical benefit of the novel acceleration strategy.