 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAndrew M. Saxe
What needs to go right for an induction head? A mechanistic study of in-context learning circuits and their formation
Apr 10, 2024
In-context learning is a powerful emergent ability in transformer models. Prior work in mechanistic interpretability has identified a circuit element that may be critical for in-context learning -- the induction head (IH), which performs a match-and-copy operation. During training of large transformers on natural language data, IHs emerge around the same time as a notable phase change in the loss. Despite the robust evidence for IHs and this interesting coincidence with the phase change, relatively little is known about the diversity and emergence dynamics of IHs. Why is there more than one IH, and how are they dependent on each other? Why do IHs appear all of a sudden, and what are the subcircuits that enable them to emerge? We answer these questions by studying IH emergence dynamics in a controlled setting by training on synthetic data. In doing so, we develop and share a novel optogenetics-inspired causal framework for modifying activations throughout training. Using this framework, we delineate the diverse and additive nature of IHs. By clamping subsets of activations throughout training, we then identify three underlying subcircuits that interact to drive IH formation, yielding the phase change. Furthermore, these subcircuits shed light on data-dependent properties of formation, such as phase change timing, already showing the promise of this more in-depth understanding of subcircuits that need to "go right" for an induction head.
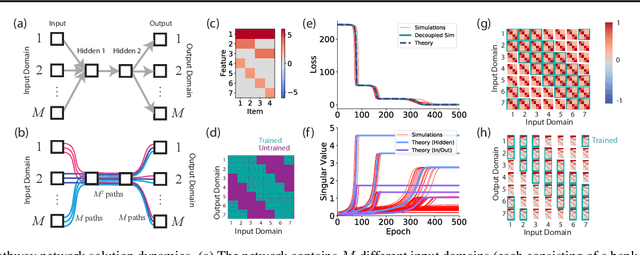
When Representations Align: Universality in Representation Learning Dynamics
Feb 14, 2024Deep neural networks come in many sizes and architectures. The choice of architecture, in conjunction with the dataset and learning algorithm, is commonly understood to affect the learned neural representations. Yet, recent results have shown that different architectures learn representations with striking qualitative similarities. Here we derive an effective theory of representation learning under the assumption that the encoding map from input to hidden representation and the decoding map from representation to output are arbitrary smooth functions. This theory schematizes representation learning dynamics in the regime of complex, large architectures, where hidden representations are not strongly constrained by the parametrization. We show through experiments that the effective theory describes aspects of representation learning dynamics across a range of deep networks with different activation functions and architectures, and exhibits phenomena similar to the "rich" and "lazy" regime. While many network behaviors depend quantitatively on architecture, our findings point to certain behaviors that are widely conserved once models are sufficiently flexible.
The Transient Nature of Emergent In-Context Learning in Transformers
Nov 15, 2023Transformer neural networks can exhibit a surprising capacity for in-context learning (ICL) despite not being explicitly trained for it. Prior work has provided a deeper understanding of how ICL emerges in transformers, e.g. through the lens of mechanistic interpretability, Bayesian inference, or by examining the distributional properties of training data. However, in each of these cases, ICL is treated largely as a persistent phenomenon; namely, once ICL emerges, it is assumed to persist asymptotically. Here, we show that the emergence of ICL during transformer training is, in fact, often transient. We train transformers on synthetic data designed so that both ICL and in-weights learning (IWL) strategies can lead to correct predictions. We find that ICL first emerges, then disappears and gives way to IWL, all while the training loss decreases, indicating an asymptotic preference for IWL. The transient nature of ICL is observed in transformers across a range of model sizes and datasets, raising the question of how much to "overtrain" transformers when seeking compact, cheaper-to-run models. We find that L2 regularization may offer a path to more persistent ICL that removes the need for early stopping based on ICL-style validation tasks. Finally, we present initial evidence that ICL transience may be caused by competition between ICL and IWL circuits.
Meta-Learning Strategies through Value Maximization in Neural Networks
Oct 30, 2023Biological and artificial learning agents face numerous choices about how to learn, ranging from hyperparameter selection to aspects of task distributions like curricula. Understanding how to make these meta-learning choices could offer normative accounts of cognitive control functions in biological learners and improve engineered systems. Yet optimal strategies remain challenging to compute in modern deep networks due to the complexity of optimizing through the entire learning process. Here we theoretically investigate optimal strategies in a tractable setting. We present a learning effort framework capable of efficiently optimizing control signals on a fully normative objective: discounted cumulative performance throughout learning. We obtain computational tractability by using average dynamical equations for gradient descent, available for simple neural network architectures. Our framework accommodates a range of meta-learning and automatic curriculum learning methods in a unified normative setting. We apply this framework to investigate the effect of approximations in common meta-learning algorithms; infer aspects of optimal curricula; and compute optimal neuronal resource allocation in a continual learning setting. Across settings, we find that control effort is most beneficial when applied to easier aspects of a task early in learning; followed by sustained effort on harder aspects. Overall, the learning effort framework provides a tractable theoretical test bed to study normative benefits of interventions in a variety of learning systems, as well as a formal account of optimal cognitive control strategies over learning trajectories posited by established theories in cognitive neuroscience.
Regularised neural networks mimic human insight
Feb 22, 2023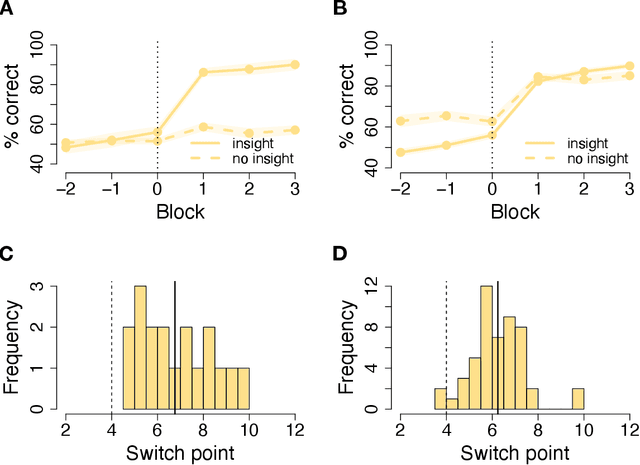
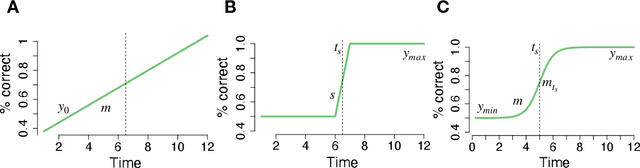
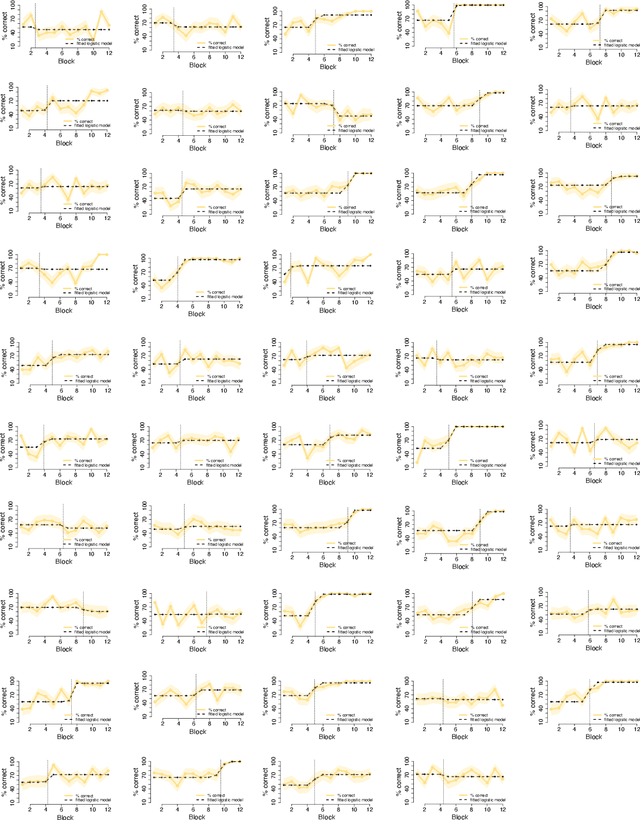
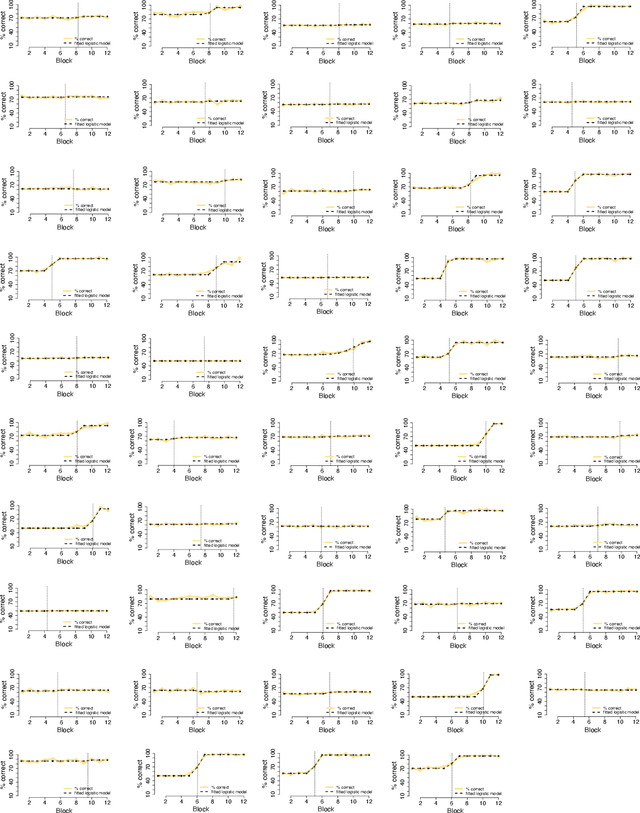
Humans sometimes show sudden improvements in task performance that have been linked to moments of insight. Such insight-related performance improvements appear special because they are preceded by an extended period of impasse, are unusually abrupt, and occur only in some, but not all, learners. Here, we ask whether insight-like behaviour also occurs in artificial neural networks trained with gradient descent algorithms. We compared learning dynamics in humans and regularised neural networks in a perceptual decision task that provided a hidden opportunity which allowed to solve the task more efficiently. We show that humans tend to discover this regularity through insight, rather than gradually. Notably, neural networks with regularised gate modulation closely mimicked behavioural characteristics of human insights, exhibiting delay of insight, suddenness and selective occurrence. Analyses of network learning dynamics revealed that insight-like behaviour crucially depended on noise added to gradient updates, and was preceded by ``silent knowledge'' that is initially suppressed by regularised (attentional) gating. This suggests that insights can arise naturally from gradual learning, where they reflect the combined influences of noise, attentional gating and regularisation.
The Neural Race Reduction: Dynamics of Abstraction in Gated Networks
Jul 21, 2022
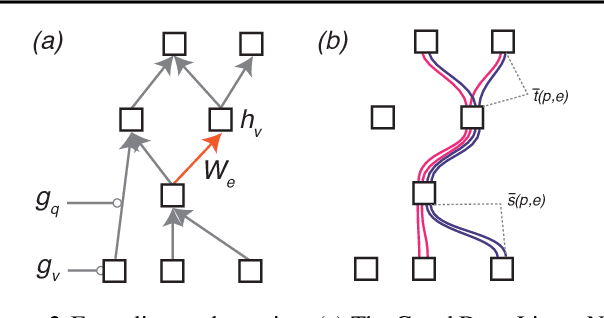
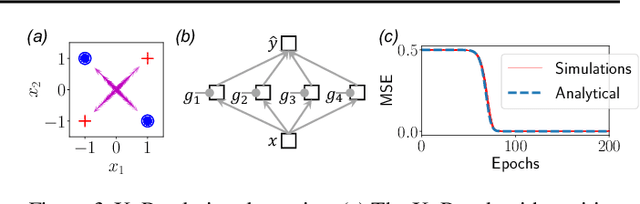
Our theoretical understanding of deep learning has not kept pace with its empirical success. While network architecture is known to be critical, we do not yet understand its effect on learned representations and network behavior, or how this architecture should reflect task structure.In this work, we begin to address this gap by introducing the Gated Deep Linear Network framework that schematizes how pathways of information flow impact learning dynamics within an architecture. Crucially, because of the gating, these networks can compute nonlinear functions of their input. We derive an exact reduction and, for certain cases, exact solutions to the dynamics of learning. Our analysis demonstrates that the learning dynamics in structured networks can be conceptualized as a neural race with an implicit bias towards shared representations, which then govern the model's ability to systematically generalize, multi-task, and transfer. We validate our key insights on naturalistic datasets and with relaxed assumptions. Taken together, our work gives rise to general hypotheses relating neural architecture to learning and provides a mathematical approach towards understanding the design of more complex architectures and the role of modularity and compositionality in solving real-world problems. The code and results are available at https://www.saxelab.org/gated-dln .
Dynamics of stochastic gradient descent for two-layer neural networks in the teacher-student setup
Jun 18, 2019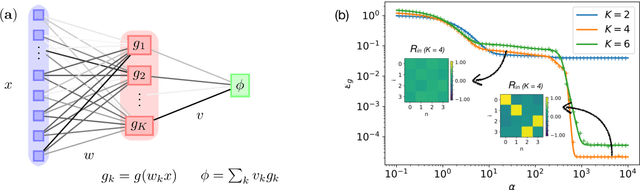
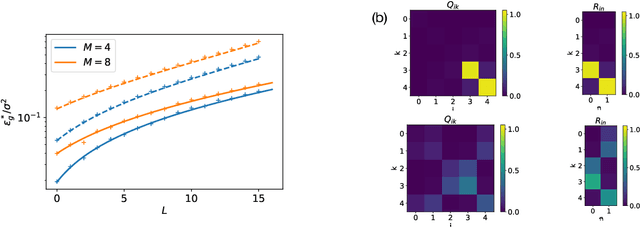
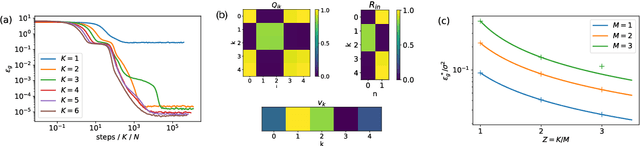
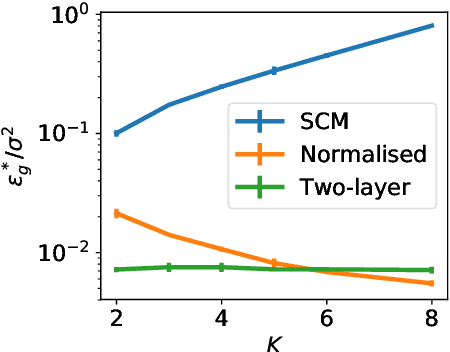
Deep neural networks achieve stellar generalisation even when they have enough parameters to easily fit all their training data. We study the dynamics and the performance of two-layer neural networks in the teacher-student setup, where one network, the student, is trained on data generated by another network, called the teacher, using stochastic gradient descent (SGD). We show how the dynamics of SGD is captured by a set of differential equations and prove that this description is asymptotically exact in the limit of large inputs. Using this framework, we calculate the final generalisation error of student networks that have more parameters than their teachers. We find that the final generalisation error of the student increases with network size when training only the first layer, but stays constant or even decreases with size when training both layers. We show that these different behaviours have their root in the different solutions SGD finds for different activation functions. Our results indicate that achieving good generalisation in neural networks goes beyond the properties of SGD alone and depends on the interplay of at least the algorithm, the model architecture, and the data set.
Generalisation dynamics of online learning in over-parameterised neural networks
Jan 25, 2019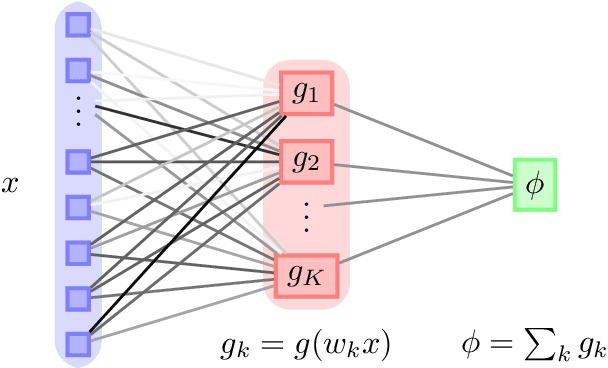
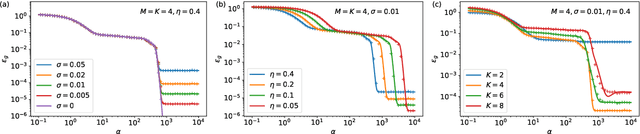
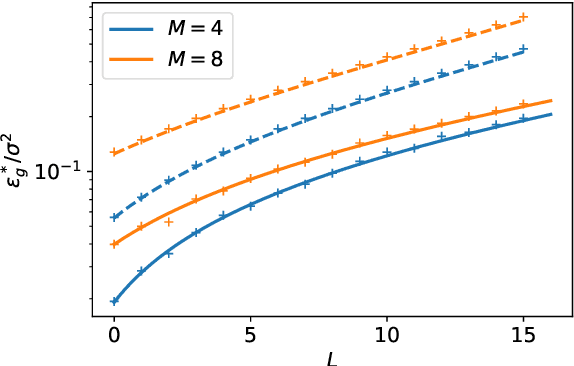
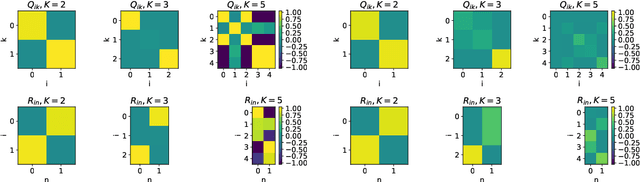
Deep neural networks achieve stellar generalisation on a variety of problems, despite often being large enough to easily fit all their training data. Here we study the generalisation dynamics of two-layer neural networks in a teacher-student setup, where one network, the student, is trained using stochastic gradient descent (SGD) on data generated by another network, called the teacher. We show how for this problem, the dynamics of SGD are captured by a set of differential equations. In particular, we demonstrate analytically that the generalisation error of the student increases linearly with the network size, with other relevant parameters held constant. Our results indicate that achieving good generalisation in neural networks depends on the interplay of at least the algorithm, its learning rate, the model architecture, and the data set.
A mathematical theory of semantic development in deep neural networks
Oct 23, 2018
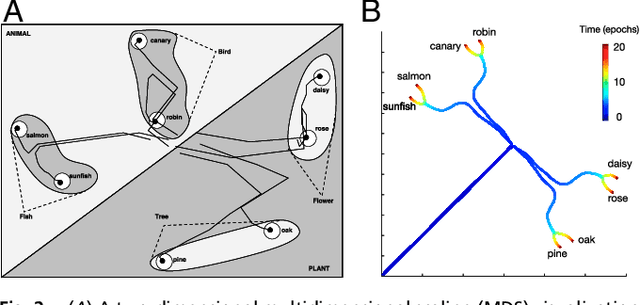
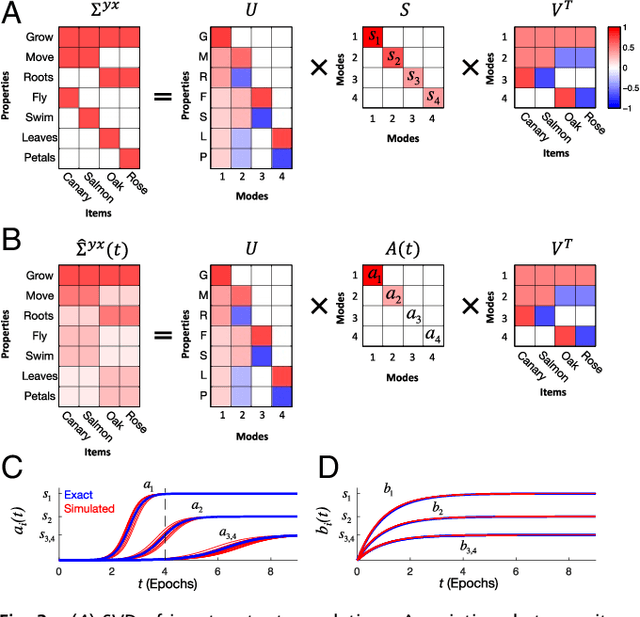
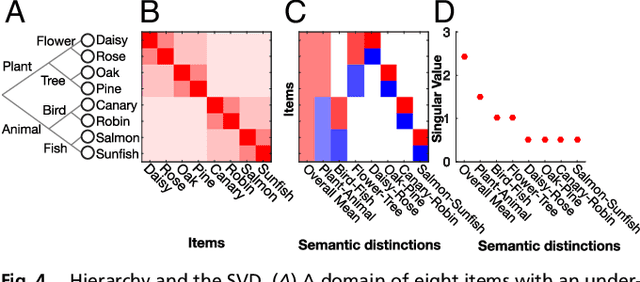
An extensive body of empirical research has revealed remarkable regularities in the acquisition, organization, deployment, and neural representation of human semantic knowledge, thereby raising a fundamental conceptual question: what are the theoretical principles governing the ability of neural networks to acquire, organize, and deploy abstract knowledge by integrating across many individual experiences? We address this question by mathematically analyzing the nonlinear dynamics of learning in deep linear networks. We find exact solutions to this learning dynamics that yield a conceptual explanation for the prevalence of many disparate phenomena in semantic cognition, including the hierarchical differentiation of concepts through rapid developmental transitions, the ubiquity of semantic illusions between such transitions, the emergence of item typicality and category coherence as factors controlling the speed of semantic processing, changing patterns of inductive projection over development, and the conservation of semantic similarity in neural representations across species. Thus, surprisingly, our simple neural model qualitatively recapitulates many diverse regularities underlying semantic development, while providing analytic insight into how the statistical structure of an environment can interact with nonlinear deep learning dynamics to give rise to these regularities.
Energy-entropy competition and the effectiveness of stochastic gradient descent in machine learning
Mar 05, 2018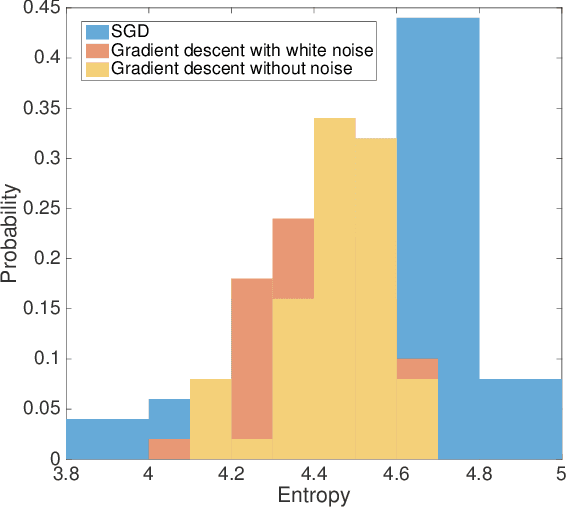
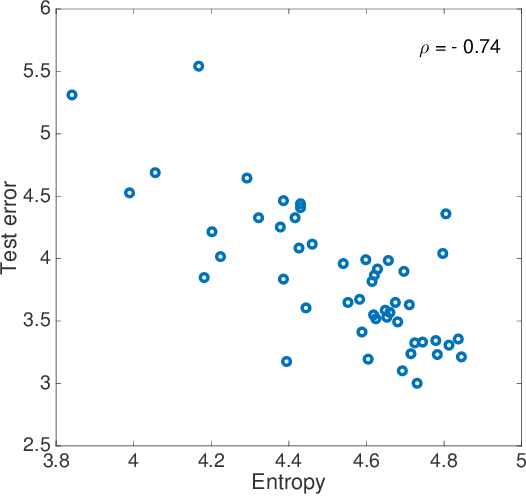
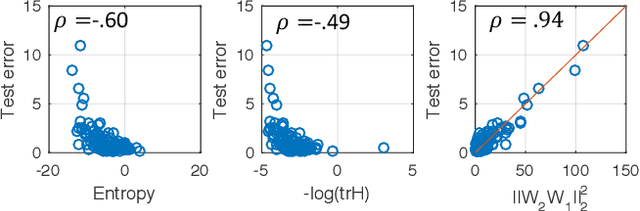
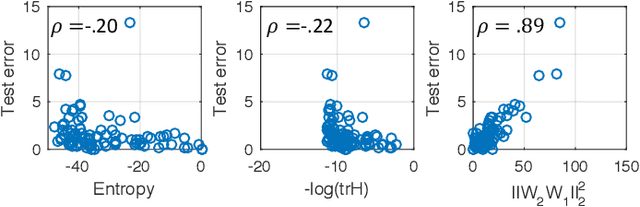
Finding parameters that minimise a loss function is at the core of many machine learning methods. The Stochastic Gradient Descent algorithm is widely used and delivers state of the art results for many problems. Nonetheless, Stochastic Gradient Descent typically cannot find the global minimum, thus its empirical effectiveness is hitherto mysterious. We derive a correspondence between parameter inference and free energy minimisation in statistical physics. The degree of undersampling plays the role of temperature. Analogous to the energy-entropy competition in statistical physics, wide but shallow minima can be optimal if the system is undersampled, as is typical in many applications. Moreover, we show that the stochasticity in the algorithm has a non-trivial correlation structure which systematically biases it towards wide minima. We illustrate our argument with two prototypical models: image classification using deep learning, and a linear neural network where we can analytically reveal the relationship between entropy and out-of-sample error.