 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAndy Zhou
FedSelect: Personalized Federated Learning with Customized Selection of Parameters for Fine-Tuning
Apr 03, 2024
Standard federated learning approaches suffer when client data distributions have sufficient heterogeneity. Recent methods addressed the client data heterogeneity issue via personalized federated learning (PFL) - a class of FL algorithms aiming to personalize learned global knowledge to better suit the clients' local data distributions. Existing PFL methods usually decouple global updates in deep neural networks by performing personalization on particular layers (i.e. classifier heads) and global aggregation for the rest of the network. However, preselecting network layers for personalization may result in suboptimal storage of global knowledge. In this work, we propose FedSelect, a novel PFL algorithm inspired by the iterative subnetwork discovery procedure used for the Lottery Ticket Hypothesis. FedSelect incrementally expands subnetworks to personalize client parameters, concurrently conducting global aggregations on the remaining parameters. This approach enables the personalization of both client parameters and subnetwork structure during the training process. Finally, we show that FedSelect outperforms recent state-of-the-art PFL algorithms under challenging client data heterogeneity settings and demonstrates robustness to various real-world distributional shifts. Our code is available at https://github.com/lapisrocks/fedselect.
GUARD: Role-playing to Generate Natural-language Jailbreakings to Test Guideline Adherence of Large Language Models
Feb 05, 2024The discovery of "jailbreaks" to bypass safety filters of Large Language Models (LLMs) and harmful responses have encouraged the community to implement safety measures. One major safety measure is to proactively test the LLMs with jailbreaks prior to the release. Therefore, such testing will require a method that can generate jailbreaks massively and efficiently. In this paper, we follow a novel yet intuitive strategy to generate jailbreaks in the style of the human generation. We propose a role-playing system that assigns four different roles to the user LLMs to collaborate on new jailbreaks. Furthermore, we collect existing jailbreaks and split them into different independent characteristics using clustering frequency and semantic patterns sentence by sentence. We organize these characteristics into a knowledge graph, making them more accessible and easier to retrieve. Our system of different roles will leverage this knowledge graph to generate new jailbreaks, which have proved effective in inducing LLMs to generate unethical or guideline-violating responses. In addition, we also pioneer a setting in our system that will automatically follow the government-issued guidelines to generate jailbreaks to test whether LLMs follow the guidelines accordingly. We refer to our system as GUARD (Guideline Upholding through Adaptive Role-play Diagnostics). We have empirically validated the effectiveness of GUARD on three cutting-edge open-sourced LLMs (Vicuna-13B, LongChat-7B, and Llama-2-7B), as well as a widely-utilized commercial LLM (ChatGPT). Moreover, our work extends to the realm of vision language models (MiniGPT-v2 and Gemini Vision Pro), showcasing GUARD's versatility and contributing valuable insights for the development of safer, more reliable LLM-based applications across diverse modalities.
Robust Prompt Optimization for Defending Language Models Against Jailbreaking Attacks
Feb 02, 2024Despite advances in AI alignment, language models (LM) remain vulnerable to adversarial attacks or jailbreaking, in which adversaries modify input prompts to induce harmful behavior. While some defenses have been proposed, they focus on narrow threat models and fall short of a strong defense, which we posit should be effective, universal, and practical. To achieve this, we propose the first adversarial objective for defending LMs against jailbreaking attacks and an algorithm, robust prompt optimization (RPO), that uses gradient-based token optimization to enforce harmless outputs. This results in an easily accessible suffix that significantly improves robustness to both jailbreaks seen during optimization and unknown, held-out jailbreaks, reducing the attack success rate on Starling-7B from 84% to 8.66% across 20 jailbreaks. In addition, we find that RPO has a minor effect on benign use, is successful under adaptive attacks, and can transfer to black-box models, reducing the success rate of the strongest attack on GPT-4, GUARD, from 92% to 6%.
Distilling Out-of-Distribution Robustness from Vision-Language Foundation Models
Nov 02, 2023We propose a conceptually simple and lightweight framework for improving the robustness of vision models through the combination of knowledge distillation and data augmentation. We address the conjecture that larger models do not make for better teachers by showing strong gains in out-of-distribution robustness when distilling from pretrained foundation models. Following this finding, we propose Discrete Adversarial Distillation (DAD), which leverages a robust teacher to generate adversarial examples and a VQGAN to discretize them, creating more informative samples than standard data augmentation techniques. We provide a theoretical framework for the use of a robust teacher in the knowledge distillation with data augmentation setting and demonstrate strong gains in out-of-distribution robustness and clean accuracy across different student architectures. Notably, our method adds minor computational overhead compared to similar techniques and can be easily combined with other data augmentations for further improvements.
Language Agent Tree Search Unifies Reasoning Acting and Planning in Language Models
Oct 06, 2023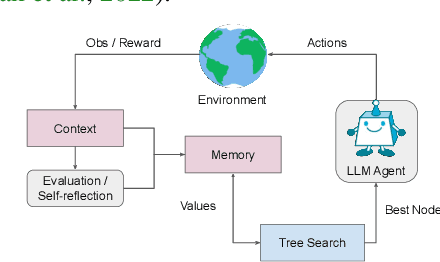
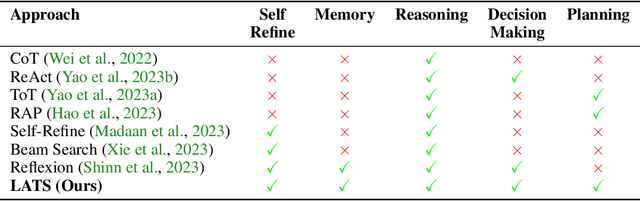
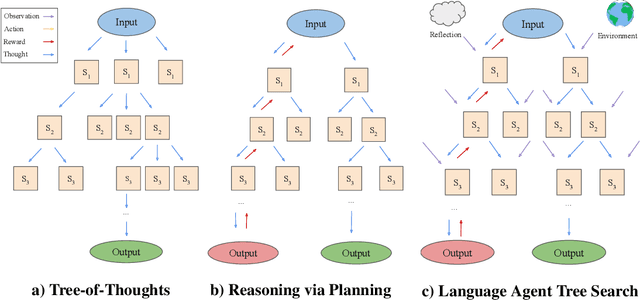
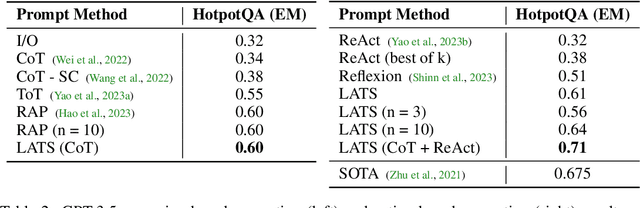
While large language models (LLMs) have demonstrated impressive performance on a range of decision-making tasks, they rely on simple acting processes and fall short of broad deployment as autonomous agents. We introduce LATS (Language Agent Tree Search), a general framework that synergizes the capabilities of LLMs in planning, acting, and reasoning. Drawing inspiration from Monte Carlo tree search in model-based reinforcement learning, LATS employs LLMs as agents, value functions, and optimizers, repurposing their latent strengths for enhanced decision-making. What is crucial in this method is the use of an environment for external feedback, which offers a more deliberate and adaptive problem-solving mechanism that moves beyond the limitations of existing techniques. Our experimental evaluation across diverse domains, such as programming, HotPotQA, and WebShop, illustrates the applicability of LATS for both reasoning and acting. In particular, LATS achieves 94.4\% for programming on HumanEval with GPT-4 and an average score of 75.9 for web browsing on WebShop with GPT-3.5, demonstrating the effectiveness and generality of our method.
A Sentence Speaks a Thousand Images: Domain Generalization through Distilling CLIP with Language Guidance
Sep 21, 2023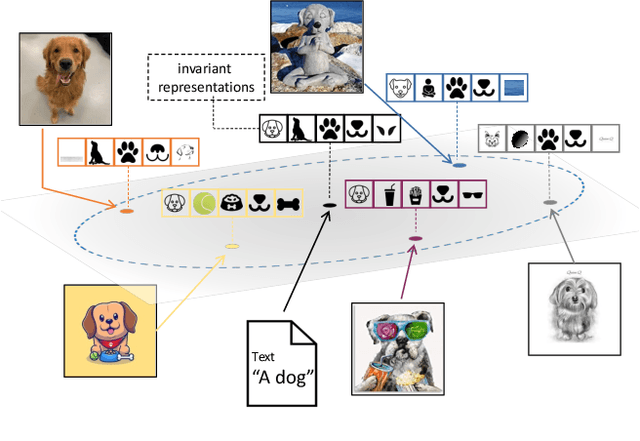



Domain generalization studies the problem of training a model with samples from several domains (or distributions) and then testing the model with samples from a new, unseen domain. In this paper, we propose a novel approach for domain generalization that leverages recent advances in large vision-language models, specifically a CLIP teacher model, to train a smaller model that generalizes to unseen domains. The key technical contribution is a new type of regularization that requires the student's learned image representations to be close to the teacher's learned text representations obtained from encoding the corresponding text descriptions of images. We introduce two designs of the loss function, absolute and relative distance, which provide specific guidance on how the training process of the student model should be regularized. We evaluate our proposed method, dubbed RISE (Regularized Invariance with Semantic Embeddings), on various benchmark datasets and show that it outperforms several state-of-the-art domain generalization methods. To our knowledge, our work is the first to leverage knowledge distillation using a large vision-language model for domain generalization. By incorporating text-based information, RISE improves the generalization capability of machine learning models.
FedSelect: Customized Selection of Parameters for Fine-Tuning during Personalized Federated Learning
Jul 07, 2023
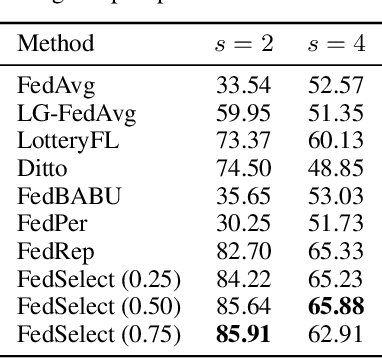

Recent advancements in federated learning (FL) seek to increase client-level performance by fine-tuning client parameters on local data or personalizing architectures for the local task. Existing methods for such personalization either prune a global model or fine-tune a global model on a local client distribution. However, these existing methods either personalize at the expense of retaining important global knowledge, or predetermine network layers for fine-tuning, resulting in suboptimal storage of global knowledge within client models. Enlightened by the lottery ticket hypothesis, we first introduce a hypothesis for finding optimal client subnetworks to locally fine-tune while leaving the rest of the parameters frozen. We then propose a novel FL framework, FedSelect, using this procedure that directly personalizes both client subnetwork structure and parameters, via the simultaneous discovery of optimal parameters for personalization and the rest of parameters for global aggregation during training. We show that this method achieves promising results on CIFAR-10.
* Work in progress
Memory-Efficient, Limb Position-Aware Hand Gesture Recognition using Hyperdimensional Computing
Mar 09, 2021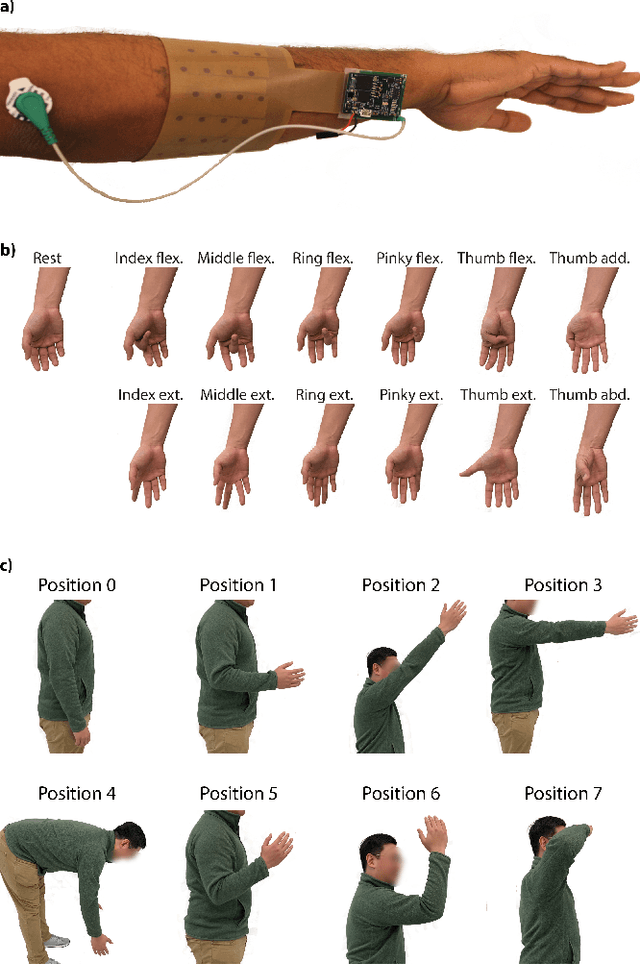
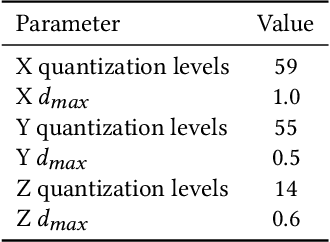
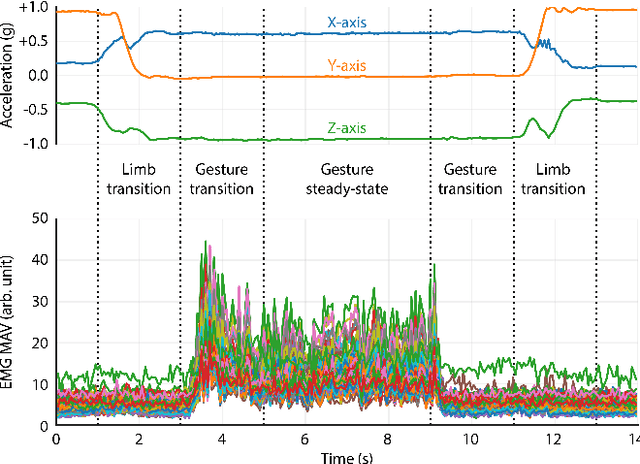
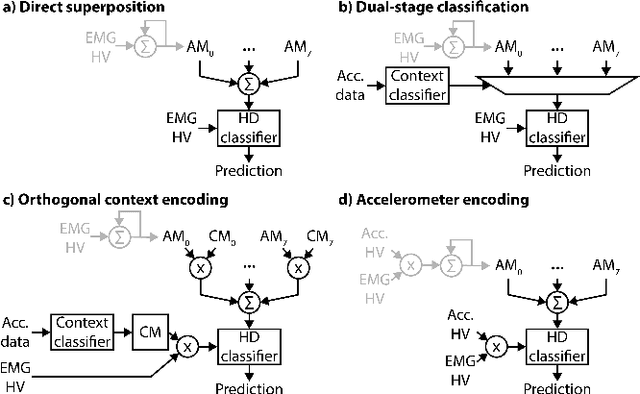
Electromyogram (EMG) pattern recognition can be used to classify hand gestures and movements for human-machine interface and prosthetics applications, but it often faces reliability issues resulting from limb position change. One method to address this is dual-stage classification, in which the limb position is first determined using additional sensors to select between multiple position-specific gesture classifiers. While improving performance, this also increases model complexity and memory footprint, making a dual-stage classifier difficult to implement in a wearable device with limited resources. In this paper, we present sensor fusion of accelerometer and EMG signals using a hyperdimensional computing model to emulate dual-stage classification in a memory-efficient way. We demonstrate two methods of encoding accelerometer features to act as keys for retrieval of position-specific parameters from multiple models stored in superposition. Through validation on a dataset of 13 gestures in 8 limb positions, we obtain a classification accuracy of up to 93.34%, an improvement of 17.79% over using a model trained solely on EMG. We achieve this while only marginally increasing memory footprint over a single limb position model, requiring $8\times$ less memory than a traditional dual-stage classification architecture.
Adaptive EMG-based hand gesture recognition using hyperdimensional computing
Jan 02, 2019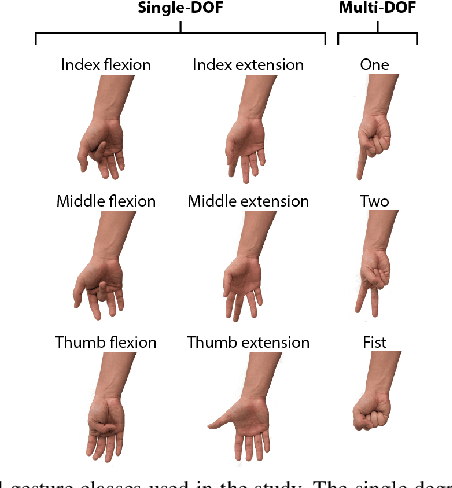
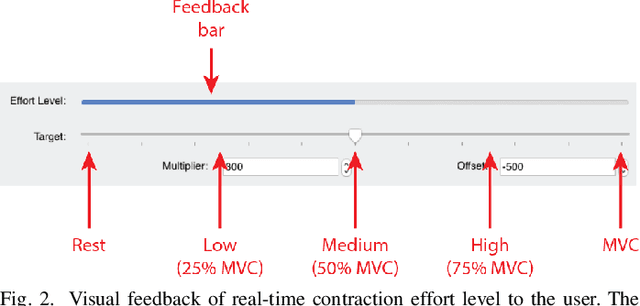
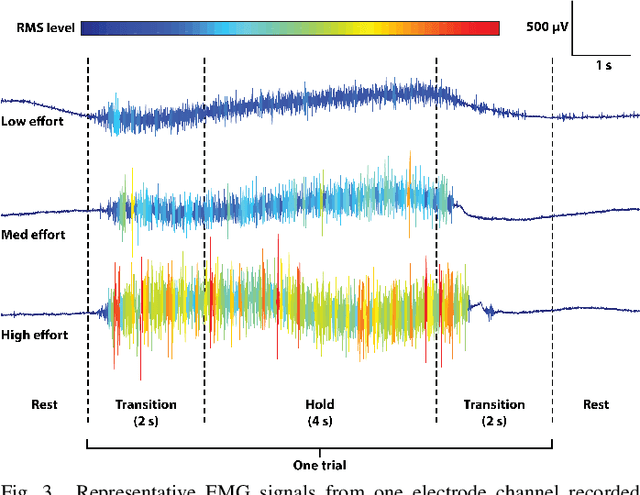
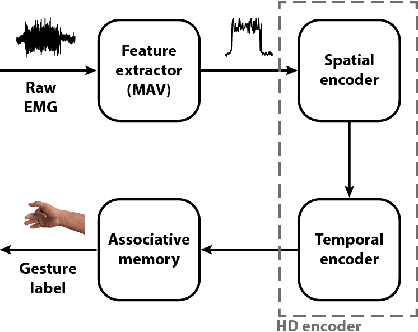
Accurate recognition of hand gestures is crucial to the functionality of smart prosthetics and other modern human-computer interfaces. Many machine learning-based classifiers use electromyography (EMG) signals as input features, but they often misclassify gestures performed in different situational contexts (changing arm position, reapplication of electrodes, etc.) or with different effort levels due to changing signal properties. Here, we describe a learning and classification algorithm based on hyperdimensional (HD) computing that, unlike traditional machine learning algorithms, enables computationally efficient updates to incrementally incorporate new data and adapt to changing contexts. EMG signal encoding for both training and classification is performed using the same set of simple operations on 10,000-element random hypervectors enabling updates on the fly. Through human experiments using a custom EMG acquisition system, we demonstrate 88.87% classification accuracy on 13 individual finger flexion and extension gestures. Using simple model updates, we preserve this accuracy with less than 5.48% degradation when expanding to 21 commonly used gestures or when subject to changing situational contexts. We also show that the same methods for updating models can be used to account for variations resulting from the effort level with which a gesture is performed.
An EMG Gesture Recognition System with Flexible High-Density Sensors and Brain-Inspired High-Dimensional Classifier
Apr 05, 2018

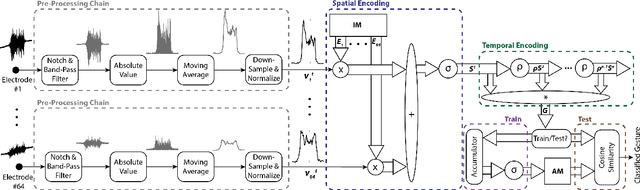
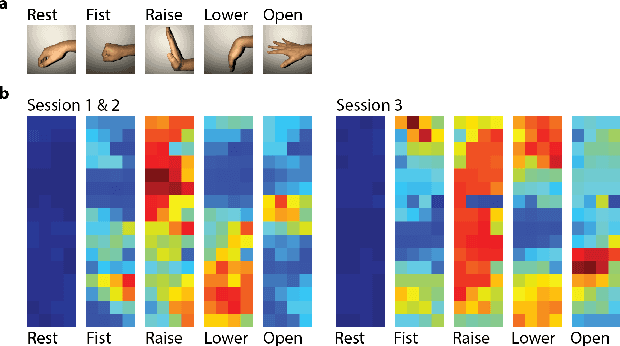
EMG-based gesture recognition shows promise for human-machine interaction. Systems are often afflicted by signal and electrode variability which degrades performance over time. We present an end-to-end system combating this variability using a large-area, high-density sensor array and a robust classification algorithm. EMG electrodes are fabricated on a flexible substrate and interfaced to a custom wireless device for 64-channel signal acquisition and streaming. We use brain-inspired high-dimensional (HD) computing for processing EMG features in one-shot learning. The HD algorithm is tolerant to noise and electrode misplacement and can quickly learn from few gestures without gradient descent or back-propagation. We achieve an average classification accuracy of 96.64% for five gestures, with only 7% degradation when training and testing across different days. Our system maintains this accuracy when trained with only three trials of gestures; it also demonstrates comparable accuracy with the state-of-the-art when trained with one trial.