 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAngelos Karlas
Invisible Needle Detection in Ultrasound: Leveraging Mechanism-Induced Vibration
Mar 21, 2024
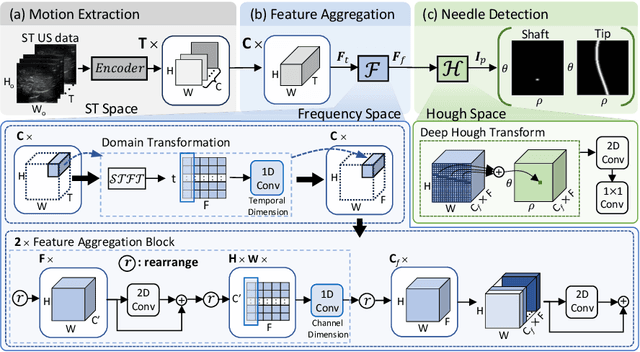
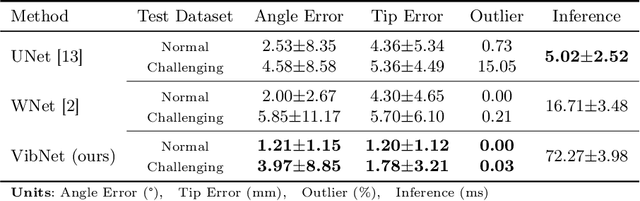
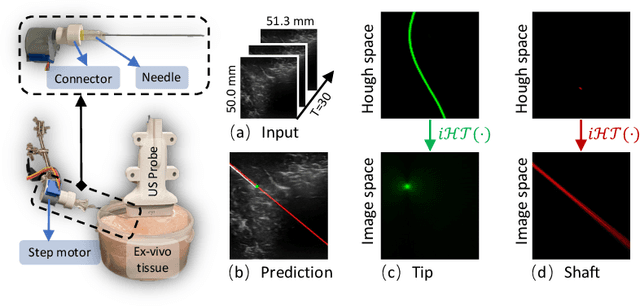
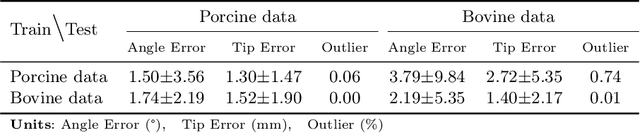
In clinical applications that involve ultrasound-guided intervention, the visibility of the needle can be severely impeded due to steep insertion and strong distractors such as speckle noise and anatomical occlusion. To address this challenge, we propose VibNet, a learning-based framework tailored to enhance the robustness and accuracy of needle detection in ultrasound images, even when the target becomes invisible to the naked eye. Inspired by Eulerian Video Magnification techniques, we utilize an external step motor to induce low-amplitude periodic motion on the needle. These subtle vibrations offer the potential to generate robust frequency features for detecting the motion patterns around the needle. To robustly and precisely detect the needle leveraging these vibrations, VibNet integrates learning-based Short-Time-Fourier-Transform and Hough-Transform modules to achieve successive sub-goals, including motion feature extraction in the spatiotemporal space, frequency feature aggregation, and needle detection in the Hough space. Based on the results obtained on distinct ex vivo porcine and bovine tissue samples, the proposed algorithm exhibits superior detection performance with efficient computation and generalization capability.
Robot-Assisted Deep Venous Thrombosis Ultrasound Examination using Virtual Fixture
Jan 04, 2024Deep Venous Thrombosis (DVT) is a common vascular disease with blood clots inside deep veins, which may block blood flow or even cause a life-threatening pulmonary embolism. A typical exam for DVT using ultrasound (US) imaging is by pressing the target vein until its lumen is fully compressed. However, the compression exam is highly operator-dependent. To alleviate intra- and inter-variations, we present a robotic US system with a novel hybrid force motion control scheme ensuring position and force tracking accuracy, and soft landing of the probe onto the target surface. In addition, a path-based virtual fixture is proposed to realize easy human-robot interaction for repeat compression operation at the lesion location. To ensure the biometric measurements obtained in different examinations are comparable, the 6D scanning path is determined in a coarse-to-fine manner using both an external RGBD camera and US images. The RGBD camera is first used to extract a rough scanning path on the object. Then, the segmented vascular lumen from US images are used to optimize the scanning path to ensure the visibility of the target object. To generate a continuous scan path for developing virtual fixtures, an arc-length based path fitting model considering both position and orientation is proposed. Finally, the whole system is evaluated on a human-like arm phantom with an uneven surface.
MI-SegNet: Mutual Information-Based US Segmentation for Unseen Domain Generalization
Mar 22, 2023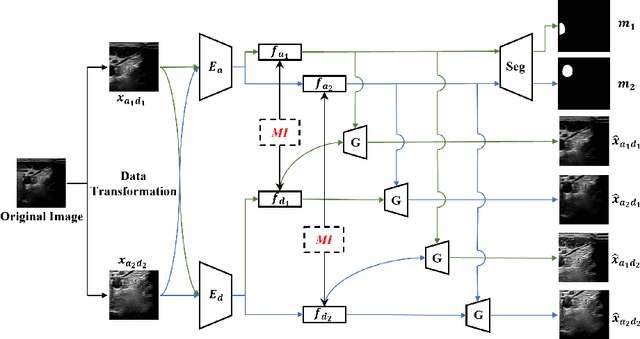
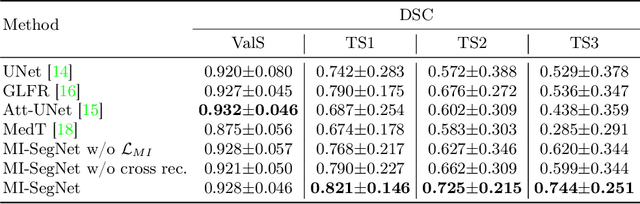

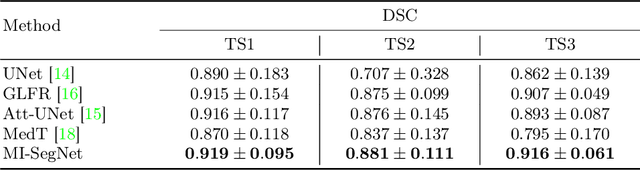
Generalization capabilities of learning-based medical image segmentation across domains are currently limited by the performance degradation caused by the domain shift, particularly for ultrasound (US) imaging. The quality of US images heavily relies on carefully tuned acoustic parameters, which vary across sonographers, machines, and settings. To improve the generalizability on US images across domains, we propose MI-SegNet, a novel mutual information (MI) based framework to explicitly disentangle the anatomical and domain feature representations; therefore, robust domain-independent segmentation can be expected. Two encoders are employed to extract the relevant features for the disentanglement. The segmentation only uses the anatomical feature map for its prediction. In order to force the encoders to learn meaningful feature representations a cross-reconstruction method is used during training. Transformations, specific to either domain or anatomy are applied to guide the encoders in their respective feature extraction task. Additionally, any MI present in both feature maps is punished to further promote separate feature spaces. We validate the generalizability of the proposed domain-independent segmentation approach on several datasets with varying parameters and machines. Furthermore, we demonstrate the effectiveness of the proposed MI-SegNet serving as a pre-trained model by comparing it with state-of-the-art networks.
VesNet-RL: Simulation-based Reinforcement Learning for Real-World US Probe Navigation
May 10, 2022

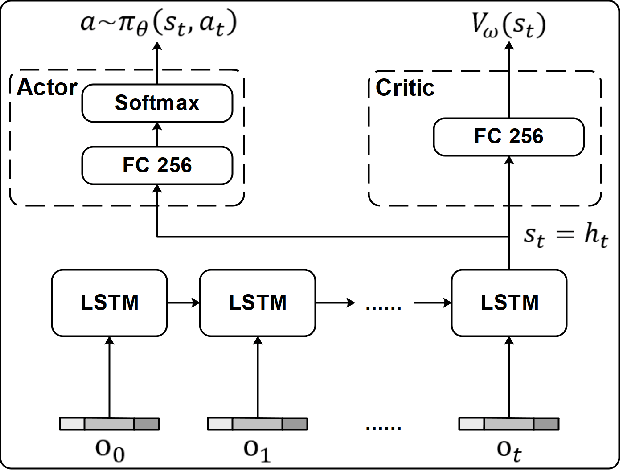
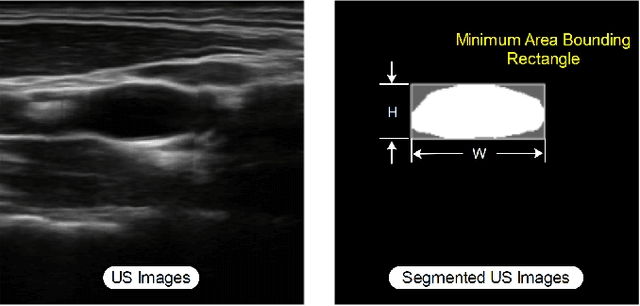
Ultrasound (US) is one of the most common medical imaging modalities since it is radiation-free, low-cost, and real-time. In freehand US examinations, sonographers often navigate a US probe to visualize standard examination planes with rich diagnostic information. However, reproducibility and stability of the resulting images often suffer from intra- and inter-operator variation. Reinforcement learning (RL), as an interaction-based learning method, has demonstrated its effectiveness in visual navigating tasks; however, RL is limited in terms of generalization. To address this challenge, we propose a simulation-based RL framework for real-world navigation of US probes towards the standard longitudinal views of vessels. A UNet is used to provide binary masks from US images; thereby, the RL agent trained on simulated binary vessel images can be applied in real scenarios without further training. To accurately characterize actual states, a multi-modality state representation structure is introduced to facilitate the understanding of environments. Moreover, considering the characteristics of vessels, a novel standard view recognition approach based on the minimum bounding rectangle is proposed to terminate the searching process. To evaluate the effectiveness of the proposed method, the trained policy is validated virtually on 3D volumes of a volunteer's in-vivo carotid artery, and physically on custom-designed gel phantoms using robotic US. The results demonstrate that proposed approach can effectively and accurately navigate the probe towards the longitudinal view of vessels.