 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnkur Handa
Geometric Fabrics: a Safe Guiding Medium for Policy Learning
May 03, 2024
Robotics policies are always subjected to complex, second order dynamics that entangle their actions with resulting states. In reinforcement learning (RL) contexts, policies have the burden of deciphering these complicated interactions over massive amounts of experience and complex reward functions to learn how to accomplish tasks. Moreover, policies typically issue actions directly to controllers like Operational Space Control (OSC) or joint PD control, which induces straightline motion towards these action targets in task or joint space. However, straightline motion in these spaces for the most part do not capture the rich, nonlinear behavior our robots need to exhibit, shifting the burden of discovering these behaviors more completely to the agent. Unlike these simpler controllers, geometric fabrics capture a much richer and desirable set of behaviors via artificial, second order dynamics grounded in nonlinear geometry. These artificial dynamics shift the uncontrolled dynamics of a robot via an appropriate control law to form behavioral dynamics. Behavioral dynamics unlock a new action space and safe, guiding behavior over which RL policies are trained. Behavioral dynamics enable bang-bang-like RL policy actions that are still safe for real robots, simplify reward engineering, and help sequence real-world, high-performance policies. We describe the framework more generally and create a specific instantiation for the problem of dexterous, in-hand reorientation of a cube by a highly actuated robot hand.
Scaling Population-Based Reinforcement Learning with GPU Accelerated Simulation
Apr 08, 2024In recent years, deep reinforcement learning (RL) has shown its effectiveness in solving complex continuous control tasks like locomotion and dexterous manipulation. However, this comes at the cost of an enormous amount of experience required for training, exacerbated by the sensitivity of learning efficiency and the policy performance to hyperparameter selection, which often requires numerous trials of time-consuming experiments. This work introduces a Population-Based Reinforcement Learning (PBRL) approach that exploits a GPU-accelerated physics simulator to enhance the exploration capabilities of RL by concurrently training multiple policies in parallel. The PBRL framework is applied to three state-of-the-art RL algorithms -- PPO, SAC, and DDPG -- dynamically adjusting hyperparameters based on the performance of learning agents. The experiments are performed on four challenging tasks in Isaac Gym -- Anymal Terrain, Shadow Hand, Humanoid, Franka Nut Pick -- by analyzing the effect of population size and mutation mechanisms for hyperparameters. The results show that PBRL agents achieve superior performance, in terms of cumulative reward, compared to non-evolutionary baseline agents. The trained agents are finally deployed in the real world for a Franka Nut Pick task, demonstrating successful sim-to-real transfer. Code and videos of the learned policies are available on our project website.
cuRobo: Parallelized Collision-Free Minimum-Jerk Robot Motion Generation
Nov 03, 2023
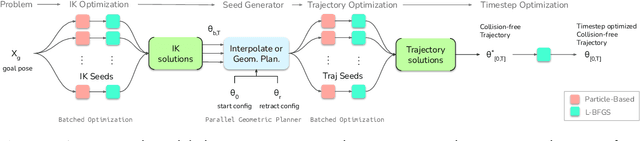
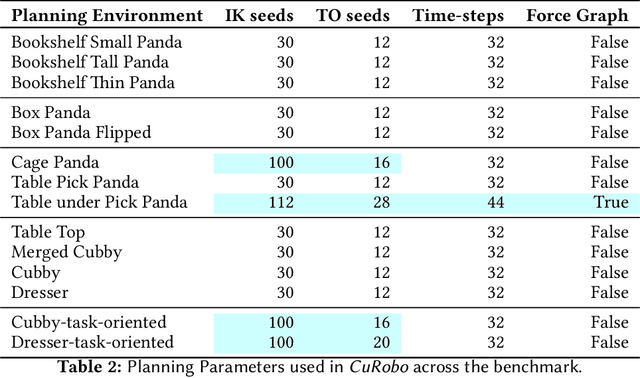
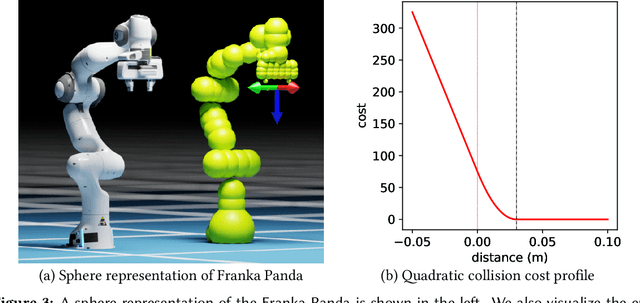
This paper explores the problem of collision-free motion generation for manipulators by formulating it as a global motion optimization problem. We develop a parallel optimization technique to solve this problem and demonstrate its effectiveness on massively parallel GPUs. We show that combining simple optimization techniques with many parallel seeds leads to solving difficult motion generation problems within 50ms on average, 60x faster than state-of-the-art (SOTA) trajectory optimization methods. We achieve SOTA performance by combining L-BFGS step direction estimation with a novel parallel noisy line search scheme and a particle-based optimization solver. To further aid trajectory optimization, we develop a parallel geometric planner that plans within 20ms and also introduce a collision-free IK solver that can solve over 7000 queries/s. We package our contributions into a state of the art GPU accelerated motion generation library, cuRobo and release it to enrich the robotics community. Additional details are available at https://curobo.org
IndustReal: Transferring Contact-Rich Assembly Tasks from Simulation to Reality
May 26, 2023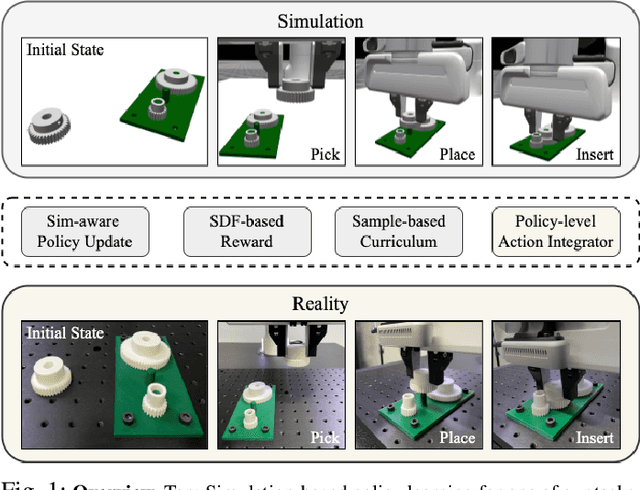

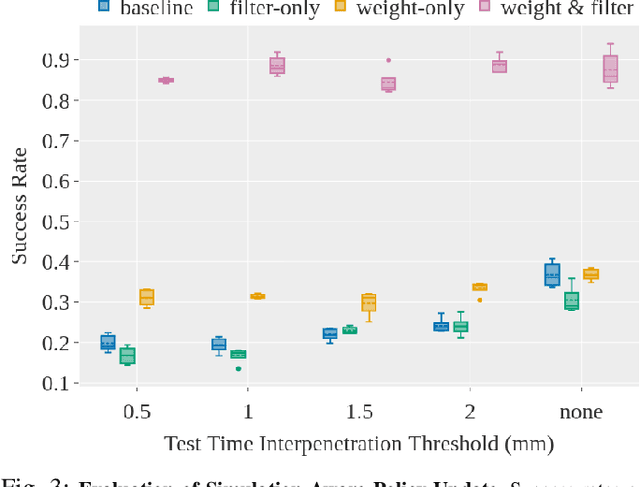
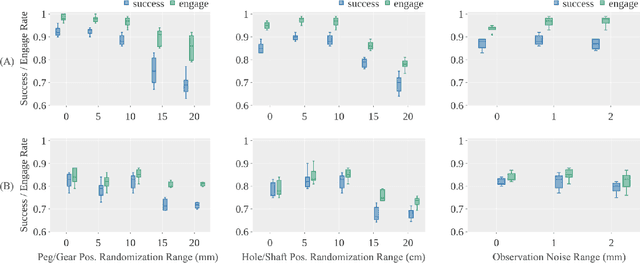
Robotic assembly is a longstanding challenge, requiring contact-rich interaction and high precision and accuracy. Many applications also require adaptivity to diverse parts, poses, and environments, as well as low cycle times. In other areas of robotics, simulation is a powerful tool to develop algorithms, generate datasets, and train agents. However, simulation has had a more limited impact on assembly. We present IndustReal, a set of algorithms, systems, and tools that solve assembly tasks in simulation with reinforcement learning (RL) and successfully achieve policy transfer to the real world. Specifically, we propose 1) simulation-aware policy updates, 2) signed-distance-field rewards, and 3) sampling-based curricula for robotic RL agents. We use these algorithms to enable robots to solve contact-rich pick, place, and insertion tasks in simulation. We then propose 4) a policy-level action integrator to minimize error at policy deployment time. We build and demonstrate a real-world robotic assembly system that uses the trained policies and action integrator to achieve repeatable performance in the real world. Finally, we present hardware and software tools that allow other researchers to reproduce our system and results. For videos and additional details, please see http://sites.google.com/nvidia.com/industreal .
Imitating Task and Motion Planning with Visuomotor Transformers
May 25, 2023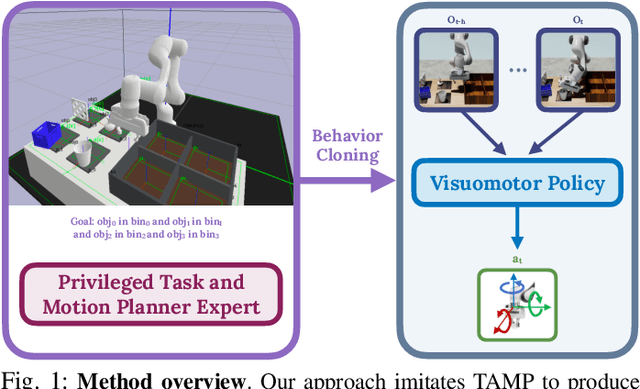

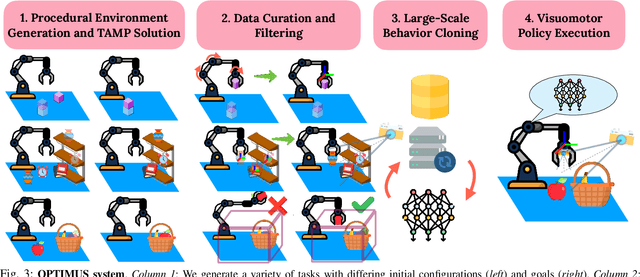
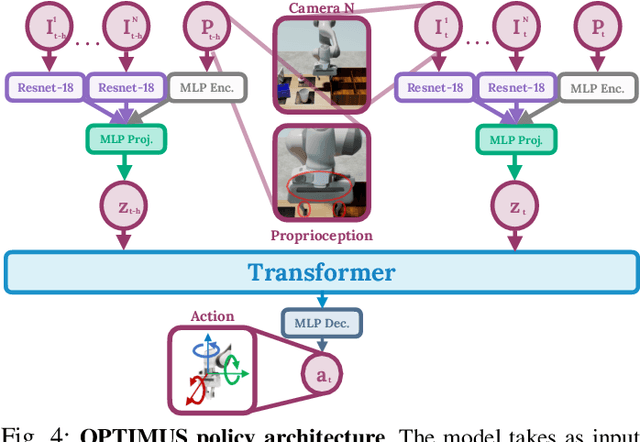
Imitation learning is a powerful tool for training robot manipulation policies, allowing them to learn from expert demonstrations without manual programming or trial-and-error. However, common methods of data collection, such as human supervision, scale poorly, as they are time-consuming and labor-intensive. In contrast, Task and Motion Planning (TAMP) can autonomously generate large-scale datasets of diverse demonstrations. In this work, we show that the combination of large-scale datasets generated by TAMP supervisors and flexible Transformer models to fit them is a powerful paradigm for robot manipulation. To that end, we present a novel imitation learning system called OPTIMUS that trains large-scale visuomotor Transformer policies by imitating a TAMP agent. OPTIMUS introduces a pipeline for generating TAMP data that is specifically curated for imitation learning and can be used to train performant transformer-based policies. In this paper, we present a thorough study of the design decisions required to imitate TAMP and demonstrate that OPTIMUS can solve a wide variety of challenging vision-based manipulation tasks with over 70 different objects, ranging from long-horizon pick-and-place tasks, to shelf and articulated object manipulation, achieving 70 to 80% success rates. Video results at https://mihdalal.github.io/optimus/
DexPBT: Scaling up Dexterous Manipulation for Hand-Arm Systems with Population Based Training
May 20, 2023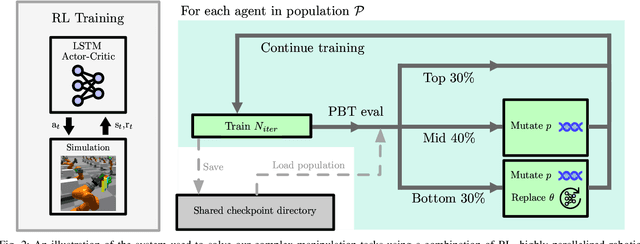

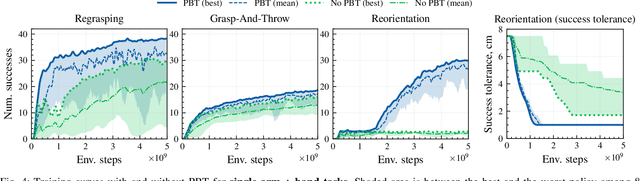
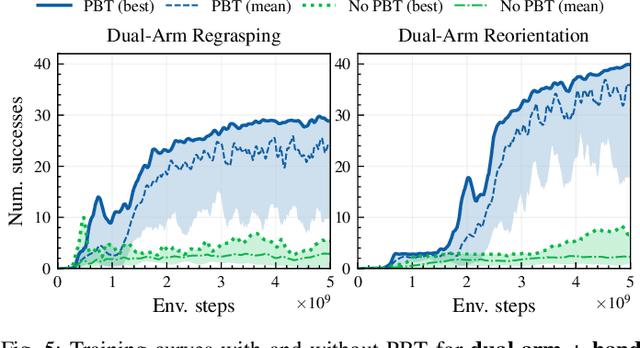
In this work, we propose algorithms and methods that enable learning dexterous object manipulation using simulated one- or two-armed robots equipped with multi-fingered hand end-effectors. Using a parallel GPU-accelerated physics simulator (Isaac Gym), we implement challenging tasks for these robots, including regrasping, grasp-and-throw, and object reorientation. To solve these problems we introduce a decentralized Population-Based Training (PBT) algorithm that allows us to massively amplify the exploration capabilities of deep reinforcement learning. We find that this method significantly outperforms regular end-to-end learning and is able to discover robust control policies in challenging tasks. Video demonstrations of learned behaviors and the code can be found at https://sites.google.com/view/dexpbt
DeXtreme: Transfer of Agile In-hand Manipulation from Simulation to Reality
Oct 25, 2022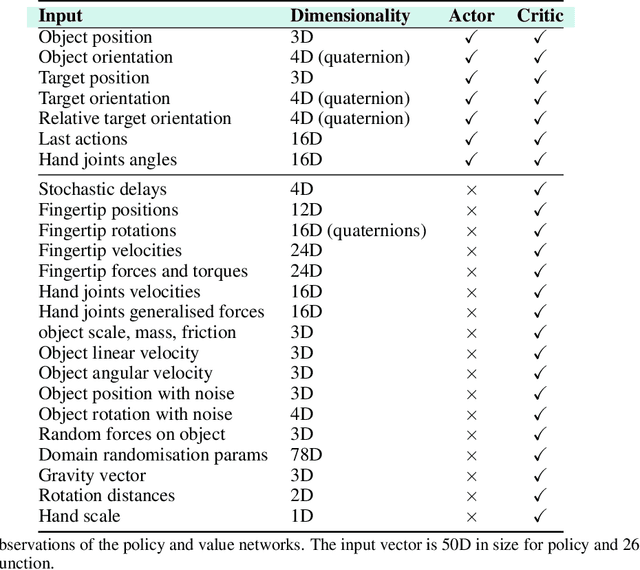


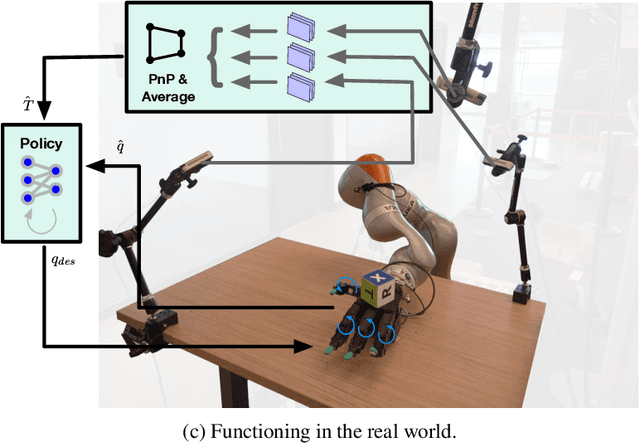
Recent work has demonstrated the ability of deep reinforcement learning (RL) algorithms to learn complex robotic behaviours in simulation, including in the domain of multi-fingered manipulation. However, such models can be challenging to transfer to the real world due to the gap between simulation and reality. In this paper, we present our techniques to train a) a policy that can perform robust dexterous manipulation on an anthropomorphic robot hand and b) a robust pose estimator suitable for providing reliable real-time information on the state of the object being manipulated. Our policies are trained to adapt to a wide range of conditions in simulation. Consequently, our vision-based policies significantly outperform the best vision policies in the literature on the same reorientation task and are competitive with policies that are given privileged state information via motion capture systems. Our work reaffirms the possibilities of sim-to-real transfer for dexterous manipulation in diverse kinds of hardware and simulator setups, and in our case, with the Allegro Hand and Isaac Gym GPU-based simulation. Furthermore, it opens up possibilities for researchers to achieve such results with commonly-available, affordable robot hands and cameras. Videos of the resulting policy and supplementary information, including experiments and demos, can be found at \url{https://dextreme.org/}
Factory: Fast Contact for Robotic Assembly
May 07, 2022
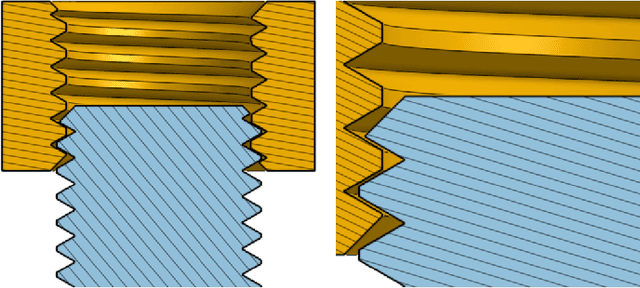


Robotic assembly is one of the oldest and most challenging applications of robotics. In other areas of robotics, such as perception and grasping, simulation has rapidly accelerated research progress, particularly when combined with modern deep learning. However, accurately, efficiently, and robustly simulating the range of contact-rich interactions in assembly remains a longstanding challenge. In this work, we present Factory, a set of physics simulation methods and robot learning tools for such applications. We achieve real-time or faster simulation of a wide range of contact-rich scenes, including simultaneous simulation of 1000 nut-and-bolt interactions. We provide $60$ carefully-designed part models, 3 robotic assembly environments, and 7 robot controllers for training and testing virtual robots. Finally, we train and evaluate proof-of-concept reinforcement learning policies for nut-and-bolt assembly. We aim for Factory to open the doors to using simulation for robotic assembly, as well as many other contact-rich applications in robotics. Please see https://sites.google.com/nvidia.com/factory for supplementary content, including videos.
Assistive Tele-op: Leveraging Transformers to Collect Robotic Task Demonstrations
Dec 09, 2021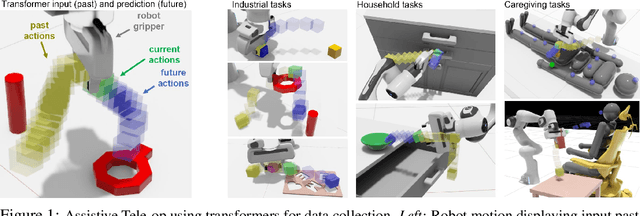
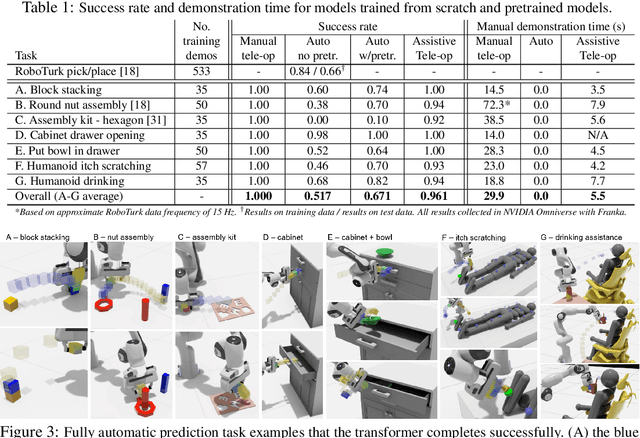
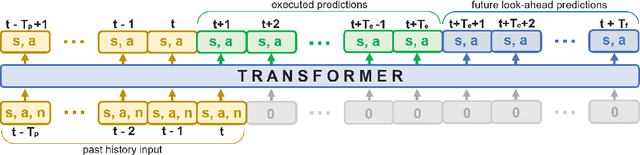
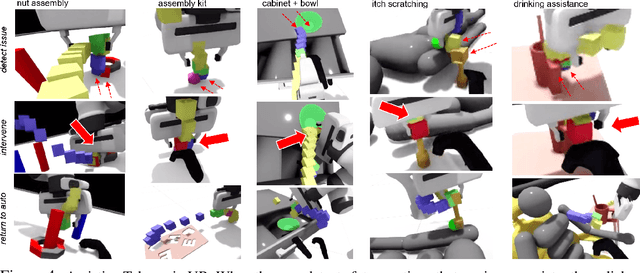
Sharing autonomy between robots and human operators could facilitate data collection of robotic task demonstrations to continuously improve learned models. Yet, the means to communicate intent and reason about the future are disparate between humans and robots. We present Assistive Tele-op, a virtual reality (VR) system for collecting robot task demonstrations that displays an autonomous trajectory forecast to communicate the robot's intent. As the robot moves, the user can switch between autonomous and manual control when desired. This allows users to collect task demonstrations with both a high success rate and with greater ease than manual teleoperation systems. Our system is powered by transformers, which can provide a window of potential states and actions far into the future -- with almost no added computation time. A key insight is that human intent can be injected at any location within the transformer sequence if the user decides that the model-predicted actions are inappropriate. At every time step, the user can (1) do nothing and allow autonomous operation to continue while observing the robot's future plan sequence, or (2) take over and momentarily prescribe a different set of actions to nudge the model back on track. We host the videos and other supplementary material at https://sites.google.com/view/assistive-teleop.
Isaac Gym: High Performance GPU-Based Physics Simulation For Robot Learning
Aug 25, 2021



Isaac Gym offers a high performance learning platform to train policies for wide variety of robotics tasks directly on GPU. Both physics simulation and the neural network policy training reside on GPU and communicate by directly passing data from physics buffers to PyTorch tensors without ever going through any CPU bottlenecks. This leads to blazing fast training times for complex robotics tasks on a single GPU with 2-3 orders of magnitude improvements compared to conventional RL training that uses a CPU based simulator and GPU for neural networks. We host the results and videos at \url{https://sites.google.com/view/isaacgym-nvidia} and isaac gym can be downloaded at \url{https://developer.nvidia.com/isaac-gym}.