 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAntoine Cully
Multi-Objective Quality-Diversity for Crystal Structure Prediction
Mar 25, 2024
Crystal structures are indispensable across various domains, from batteries to solar cells, and extensive research has been dedicated to predicting their properties based on their atomic configurations. However, prevailing Crystal Structure Prediction methods focus on identifying the most stable solutions that lie at the global minimum of the energy function. This approach overlooks other potentially interesting materials that lie in neighbouring local minima and have different material properties such as conductivity or resistance to deformation. By contrast, Quality-Diversity algorithms provide a promising avenue for Crystal Structure Prediction as they aim to find a collection of high-performing solutions that have diverse characteristics. However, it may also be valuable to optimise for the stability of crystal structures alongside other objectives such as magnetism or thermoelectric efficiency. Therefore, in this work, we harness the power of Multi-Objective Quality-Diversity algorithms in order to find crystal structures which have diverse features and achieve different trade-offs of objectives. We analyse our approach on 5 crystal systems and demonstrate that it is not only able to re-discover known real-life structures, but also find promising new ones. Moreover, we propose a method for illuminating the objective space to gain an understanding of what trade-offs can be achieved.
Quality-Diversity Actor-Critic: Learning High-Performing and Diverse Behaviors via Value and Successor Features Critics
Mar 15, 2024
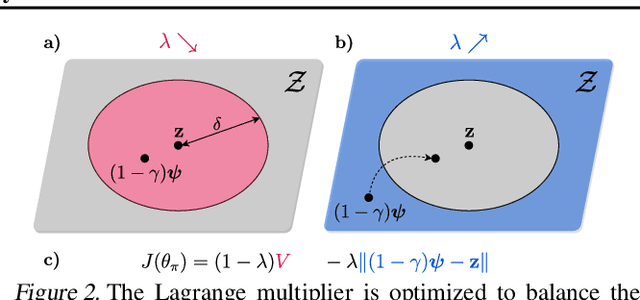
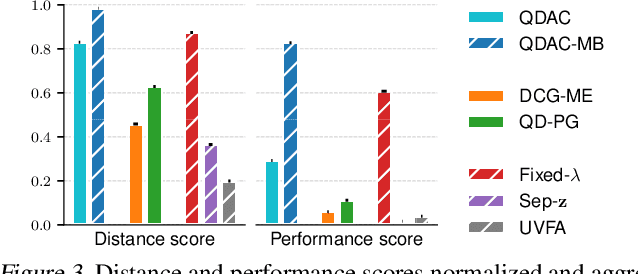
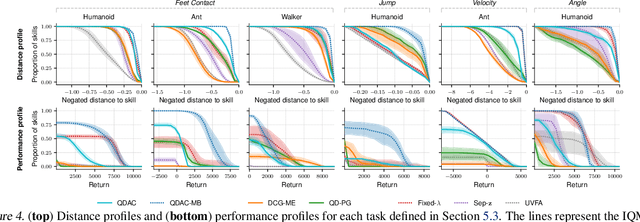
A key aspect of intelligence is the ability to demonstrate a broad spectrum of behaviors for adapting to unexpected situations. Over the past decade, advancements in deep reinforcement learning have led to groundbreaking achievements to solve complex continuous control tasks. However, most approaches return only one solution specialized for a specific problem. We introduce Quality-Diversity Actor-Critic (QDAC), an off-policy actor-critic deep reinforcement learning algorithm that leverages a value function critic and a successor features critic to learn high-performing and diverse behaviors. In this framework, the actor optimizes an objective that seamlessly unifies both critics using constrained optimization to (1) maximize return, while (2) executing diverse skills. Compared with other Quality-Diversity methods, QDAC achieves significantly higher performance and more diverse behaviors on six challenging continuous control locomotion tasks. We also demonstrate that we can harness the learned skills to adapt better than other baselines to five perturbed environments. Finally, qualitative analyses showcase a range of remarkable behaviors, available at: http://bit.ly/qdac.
Illuminating the property space in crystal structure prediction using Quality-Diversity algorithms
Mar 06, 2024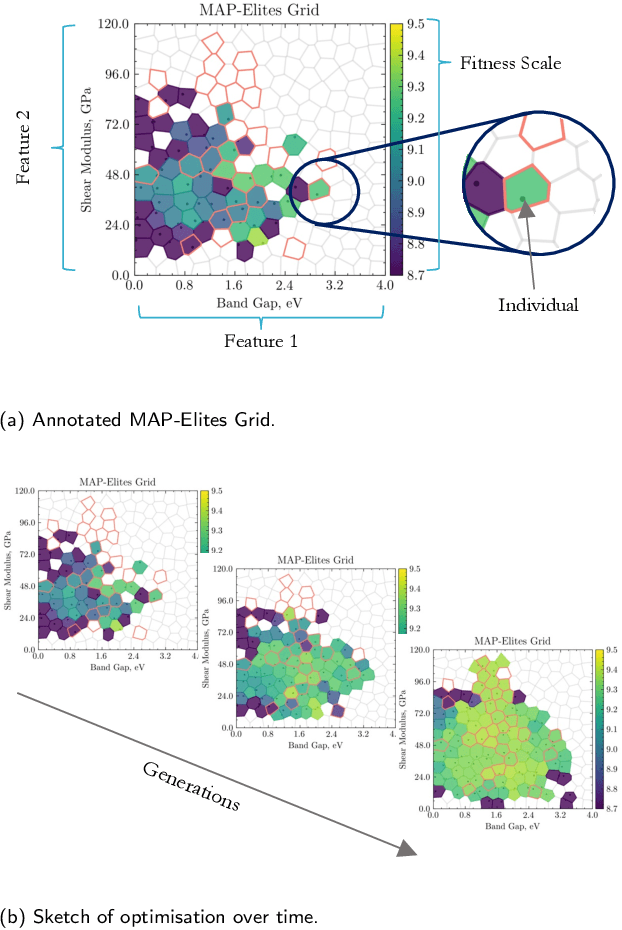
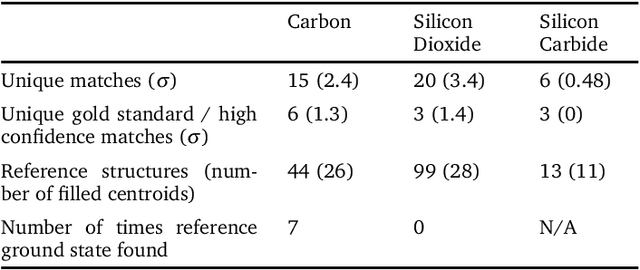
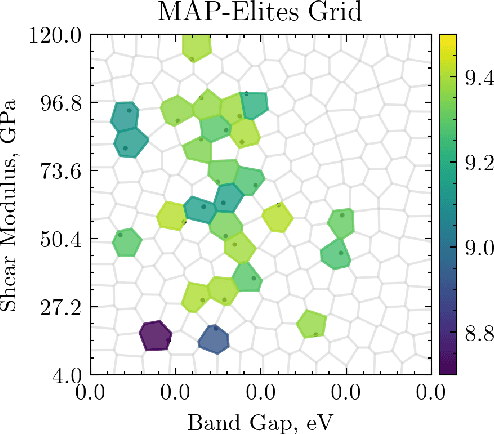
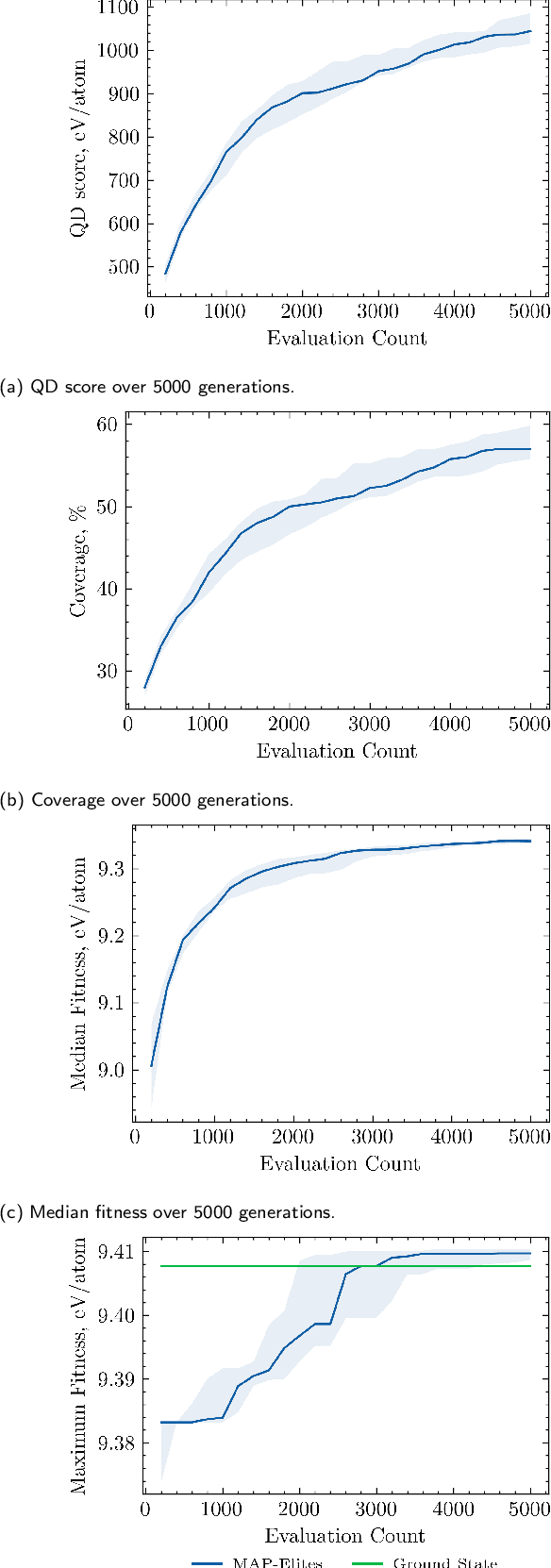
The identification of materials with exceptional properties is an essential objective to enable technological progress. We propose the application of \textit{Quality-Diversity} algorithms to the field of crystal structure prediction. The objective of these algorithms is to identify a diverse set of high-performing solutions, which has been successful in a range of fields such as robotics, architecture and aeronautical engineering. As these methods rely on a high number of evaluations, we employ machine-learning surrogate models to compute the interatomic potential and material properties that are used to guide optimisation. Consequently, we also show the value of using neural networks to model crystal properties and enable the identification of novel composition--structure combinations. In this work, we specifically study the application of the MAP-Elites algorithm to predict polymorphs of TiO$_2$. We rediscover the known ground state, in addition to a set of other polymorphs with distinct properties. We validate our method for C, SiO$_2$ and SiC systems, where we show that the algorithm can uncover multiple local minima with distinct electronic and mechanical properties.
Beyond Expected Return: Accounting for Policy Reproducibility when Evaluating Reinforcement Learning Algorithms
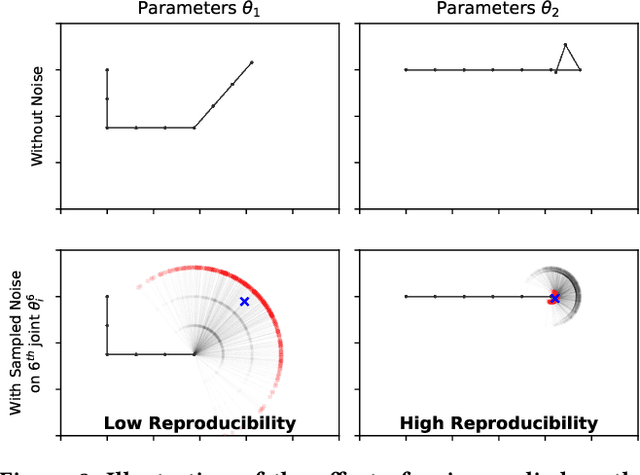
Dec 12, 2023Many applications in Reinforcement Learning (RL) usually have noise or stochasticity present in the environment. Beyond their impact on learning, these uncertainties lead the exact same policy to perform differently, i.e. yield different return, from one roll-out to another. Common evaluation procedures in RL summarise the consequent return distributions using solely the expected return, which does not account for the spread of the distribution. Our work defines this spread as the policy reproducibility: the ability of a policy to obtain similar performance when rolled out many times, a crucial property in some real-world applications. We highlight that existing procedures that only use the expected return are limited on two fronts: first an infinite number of return distributions with a wide range of performance-reproducibility trade-offs can have the same expected return, limiting its effectiveness when used for comparing policies; second, the expected return metric does not leave any room for practitioners to choose the best trade-off value for considered applications. In this work, we address these limitations by recommending the use of Lower Confidence Bound, a metric taken from Bayesian optimisation that provides the user with a preference parameter to choose a desired performance-reproducibility trade-off. We also formalise and quantify policy reproducibility, and demonstrate the benefit of our metrics using extensive experiments of popular RL algorithms on common uncertain RL tasks.
Mix-ME: Quality-Diversity for Multi-Agent Learning
Nov 03, 2023In many real-world systems, such as adaptive robotics, achieving a single, optimised solution may be insufficient. Instead, a diverse set of high-performing solutions is often required to adapt to varying contexts and requirements. This is the realm of Quality-Diversity (QD), which aims to discover a collection of high-performing solutions, each with their own unique characteristics. QD methods have recently seen success in many domains, including robotics, where they have been used to discover damage-adaptive locomotion controllers. However, most existing work has focused on single-agent settings, despite many tasks of interest being multi-agent. To this end, we introduce Mix-ME, a novel multi-agent variant of the popular MAP-Elites algorithm that forms new solutions using a crossover-like operator by mixing together agents from different teams. We evaluate the proposed methods on a variety of partially observable continuous control tasks. Our evaluation shows that these multi-agent variants obtained by Mix-ME not only compete with single-agent baselines but also often outperform them in multi-agent settings under partial observability.
QDax: A Library for Quality-Diversity and Population-based Algorithms with Hardware Acceleration
Aug 07, 2023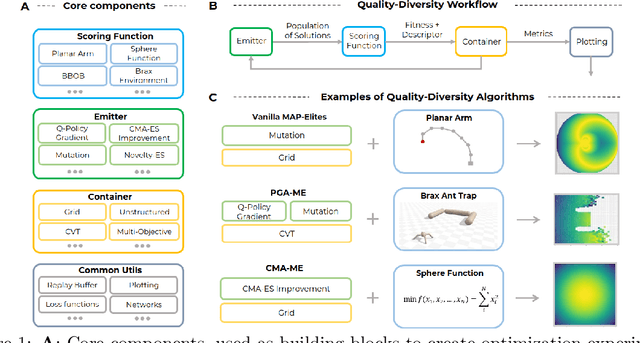
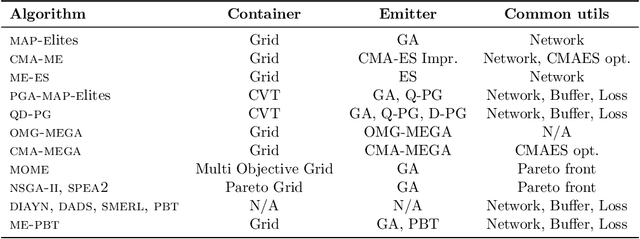
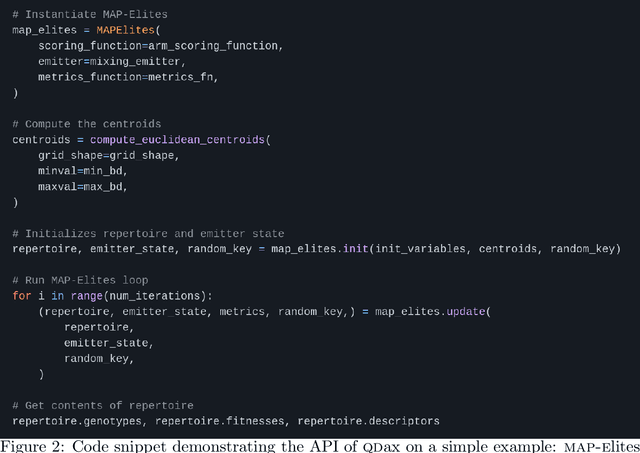
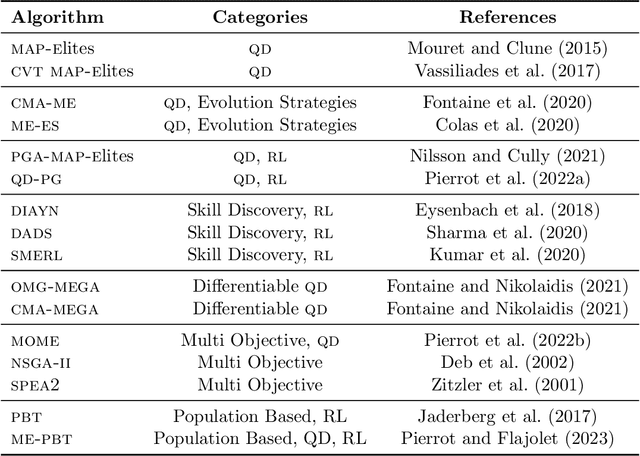
QDax is an open-source library with a streamlined and modular API for Quality-Diversity (QD) optimization algorithms in Jax. The library serves as a versatile tool for optimization purposes, ranging from black-box optimization to continuous control. QDax offers implementations of popular QD, Neuroevolution, and Reinforcement Learning (RL) algorithms, supported by various examples. All the implementations can be just-in-time compiled with Jax, facilitating efficient execution across multiple accelerators, including GPUs and TPUs. These implementations effectively demonstrate the framework's flexibility and user-friendliness, easing experimentation for research purposes. Furthermore, the library is thoroughly documented and tested with 95\% coverage.
Gradient-Informed Quality Diversity for the Illumination of Discrete Spaces
Jun 08, 2023
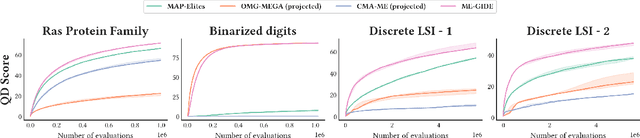
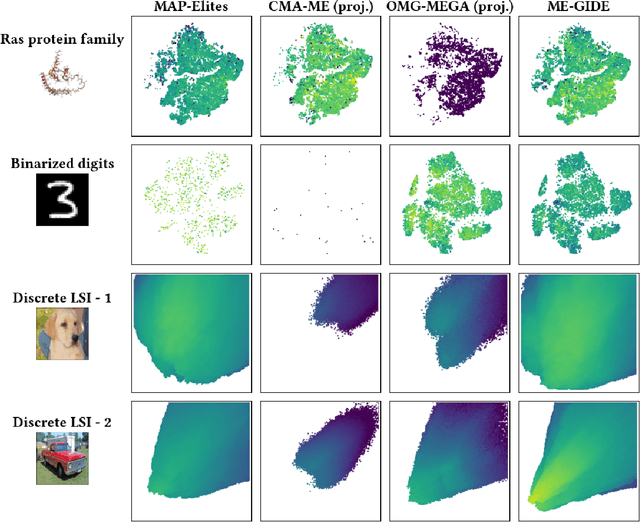
Quality Diversity (QD) algorithms have been proposed to search for a large collection of both diverse and high-performing solutions instead of a single set of local optima. While early QD algorithms view the objective and descriptor functions as black-box functions, novel tools have been introduced to use gradient information to accelerate the search and improve overall performance of those algorithms over continuous input spaces. However a broad range of applications involve discrete spaces, such as drug discovery or image generation. Exploring those spaces is challenging as they are combinatorially large and gradients cannot be used in the same manner as in continuous spaces. We introduce map-elites with a Gradient-Informed Discrete Emitter (ME-GIDE), which extends QD optimisation with differentiable functions over discrete search spaces. ME-GIDE leverages the gradient information of the objective and descriptor functions with respect to its discrete inputs to propose gradient-informed updates that guide the search towards a diverse set of high quality solutions. We evaluate our method on challenging benchmarks including protein design and discrete latent space illumination and find that our method outperforms state-of-the-art QD algorithms in all benchmarks.
Benchmark tasks for Quality-Diversity applied to Uncertain domains
Apr 26, 2023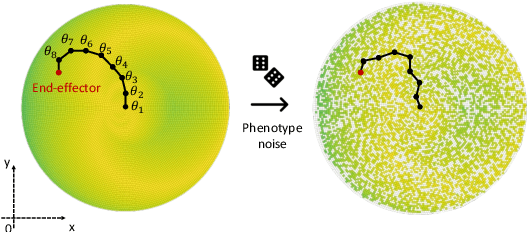
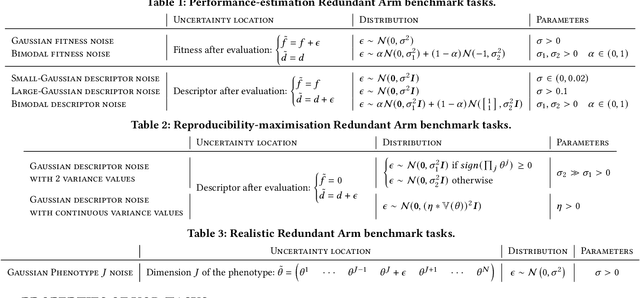
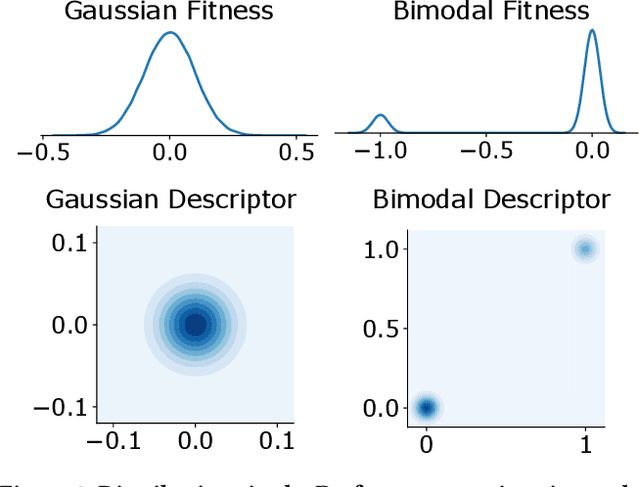
While standard approaches to optimisation focus on producing a single high-performing solution, Quality-Diversity (QD) algorithms allow large diverse collections of such solutions to be found. If QD has proven promising across a large variety of domains, it still struggles when faced with uncertain domains, where quantification of performance and diversity are non-deterministic. Previous work in Uncertain Quality-Diversity (UQD) has proposed methods and metrics designed for such uncertain domains. In this paper, we propose a first set of benchmark tasks to analyse and estimate the performance of UQD algorithms. We identify the key uncertainty properties to easily define UQD benchmark tasks: the uncertainty location, the type of distribution and its parameters. By varying the nature of those key UQD components, we introduce a set of 8 easy-to-implement and lightweight tasks, split into 3 main categories. All our tasks build on the Redundant Arm: a common QD environment that is lightweight and easily replicable. Each one of these tasks highlights one specific limitation that arises when considering UQD domains. With this first benchmark, we hope to facilitate later advances in UQD.
Quality-Diversity Optimisation on a Physical Robot Through Dynamics-Aware and Reset-Free Learning
Apr 24, 2023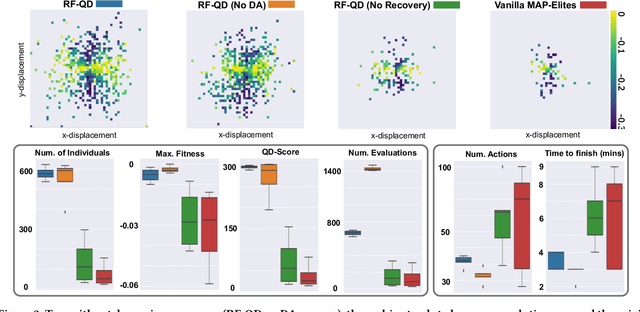
Learning algorithms, like Quality-Diversity (QD), can be used to acquire repertoires of diverse robotics skills. This learning is commonly done via computer simulation due to the large number of evaluations required. However, training in a virtual environment generates a gap between simulation and reality. Here, we build upon the Reset-Free QD (RF-QD) algorithm to learn controllers directly on a physical robot. This method uses a dynamics model, learned from interactions between the robot and the environment, to predict the robot's behaviour and improve sample efficiency. A behaviour selection policy filters out uninteresting or unsafe policies predicted by the model. RF-QD also includes a recovery policy that returns the robot to a safe zone when it has walked outside of it, allowing continuous learning. We demonstrate that our method enables a physical quadruped robot to learn a repertoire of behaviours in two hours without human supervision. We successfully test the solution repertoire using a maze navigation task. Finally, we compare our approach to the MAP-Elites algorithm. We show that dynamics awareness and a recovery policy are required for training on a physical robot for optimal archive generation. Video available at https://youtu.be/BgGNvIsRh7Q
Don't Bet on Luck Alone: Enhancing Behavioral Reproducibility of Quality-Diversity Solutions in Uncertain Domains
Apr 07, 2023

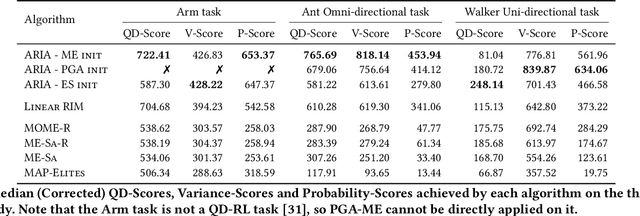
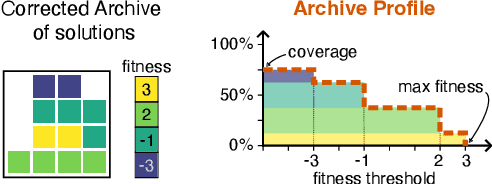
Quality-Diversity (QD) algorithms are designed to generate collections of high-performing solutions while maximizing their diversity in a given descriptor space. However, in the presence of unpredictable noise, the fitness and descriptor of the same solution can differ significantly from one evaluation to another, leading to uncertainty in the estimation of such values. Given the elitist nature of QD algorithms, they commonly end up with many degenerate solutions in such noisy settings. In this work, we introduce Archive Reproducibility Improvement Algorithm (ARIA); a plug-and-play approach that improves the reproducibility of the solutions present in an archive. We propose it as a separate optimization module, relying on natural evolution strategies, that can be executed on top of any QD algorithm. Our module mutates solutions to (1) optimize their probability of belonging to their niche, and (2) maximize their fitness. The performance of our method is evaluated on various tasks, including a classical optimization problem and two high-dimensional control tasks in simulated robotic environments. We show that our algorithm enhances the quality and descriptor space coverage of any given archive by at least 50%.