 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeArash Shahriari
Unified Backpropagation for Multi-Objective Deep Learning
Oct 20, 2017
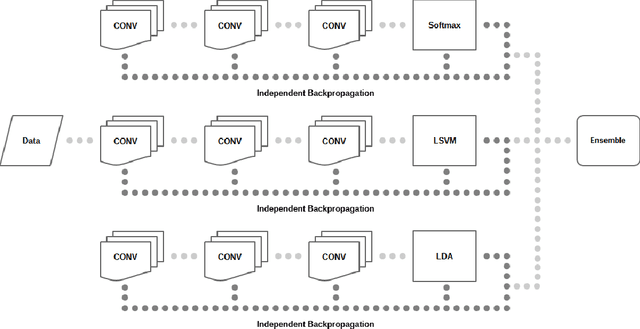
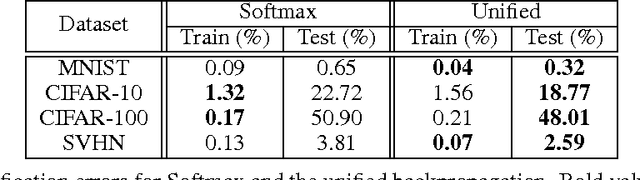
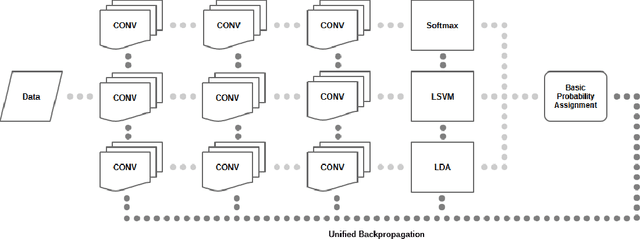
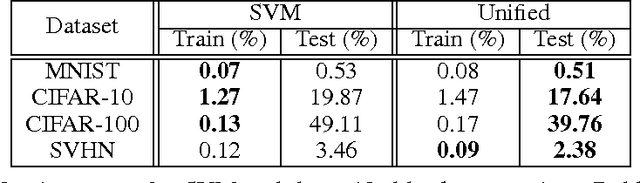
A common practice in most of deep convolutional neural architectures is to employ fully-connected layers followed by Softmax activation to minimize cross-entropy loss for the sake of classification. Recent studies show that substitution or addition of the Softmax objective to the cost functions of support vector machines or linear discriminant analysis is highly beneficial to improve the classification performance in hybrid neural networks. We propose a novel paradigm to link the optimization of several hybrid objectives through unified backpropagation. This highly alleviates the burden of extensive boosting for independent objective functions or complex formulation of multiobjective gradients. Hybrid loss functions are linked by basic probability assignment from evidence theory. We conduct our experiments for a variety of scenarios and standard datasets to evaluate the advantage of our proposed unification approach to deliver consistent improvements into the classification performance of deep convolutional neural networks.
Distributed Deep Transfer Learning by Basic Probability Assignment
Oct 20, 2017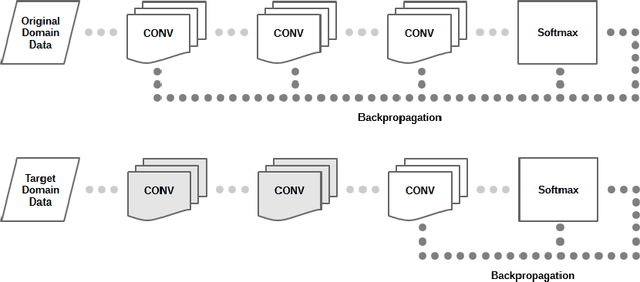
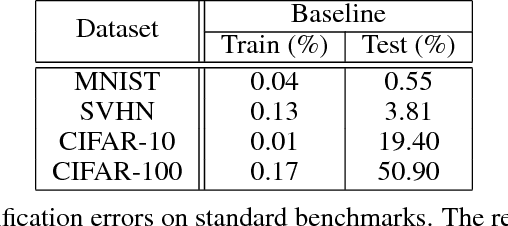
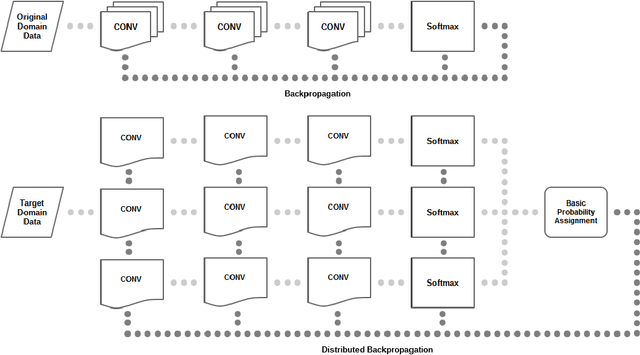
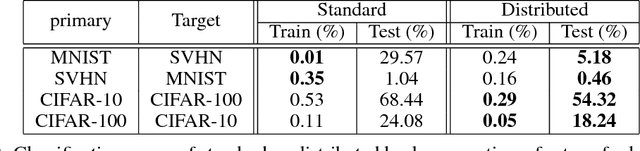
Transfer learning is a popular practice in deep neural networks, but fine-tuning of large number of parameters is a hard task due to the complex wiring of neurons between splitting layers and imbalance distributions of data in pretrained and transferred domains. The reconstruction of the original wiring for the target domain is a heavy burden due to the size of interconnections across neurons. We propose a distributed scheme that tunes the convolutional filters individually while backpropagates them jointly by means of basic probability assignment. Some of the most recent advances in evidence theory show that in a vast variety of the imbalanced regimes, optimizing of some proper objective functions derived from contingency matrices prevents biases towards high-prior class distributions. Therefore, the original filters get gradually transferred based on individual contributions to overall performance of the target domain. This largely reduces the expected complexity of transfer learning whilst highly improves precision. Our experiments on standard benchmarks and scenarios confirm the consistent improvement of our distributed deep transfer learning strategy.
Multipartite Pooling for Deep Convolutional Neural Networks
Oct 20, 2017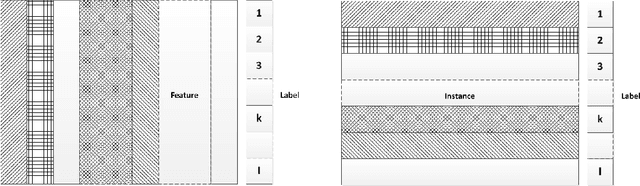
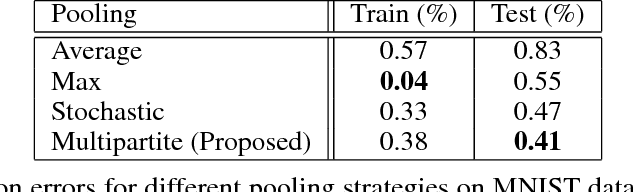
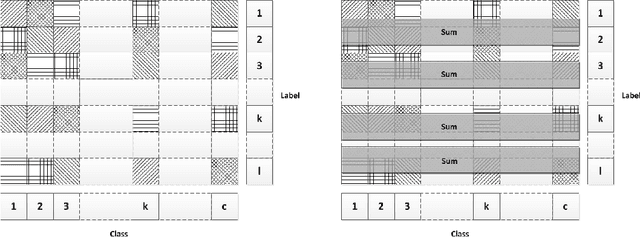
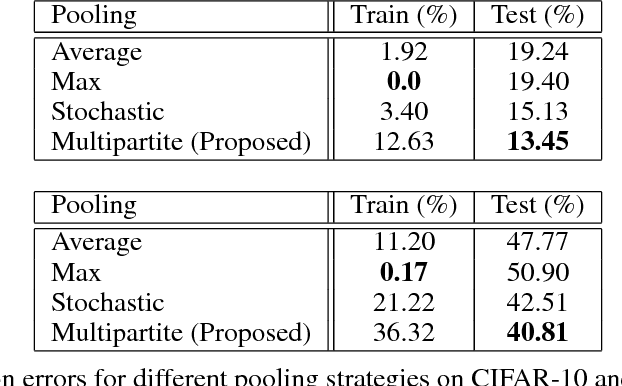
We propose a novel pooling strategy that learns how to adaptively rank deep convolutional features for selecting more informative representations. To this end, we exploit discriminative analysis to project the features onto a space spanned by the number of classes in the dataset under study. This maps the notion of labels in the feature space into instances in the projected space. We employ these projected distances as a measure to rank the existing features with respect to their specific discriminant power for each individual class. We then apply multipartite ranking to score the separability of the instances and aggregate one-versus-all scores to compute an overall distinction score for each feature. For the pooling, we pick features with the highest scores in a pooling window instead of maximum, average or stochastic random assignments. Our experiments on various benchmarks confirm that the proposed strategy of multipartite pooling is highly beneficial to consistently improve the performance of deep convolutional networks via better generalization of the trained models for the test-time data.
Multipartite Ranking-Selection of Low-Dimensional Instances by Supervised Projection to High-Dimensional Space
Jun 24, 2016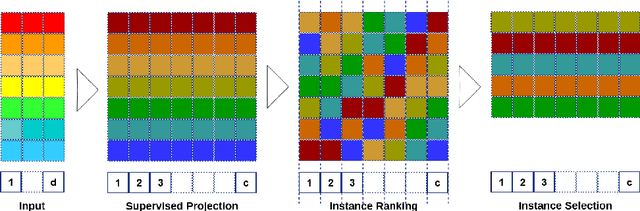
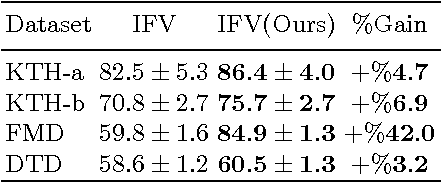

Pruning of redundant or irrelevant instances of data is a key to every successful solution for pattern recognition. In this paper, we present a novel ranking-selection framework for low-length but highly correlated instances. Instead of working in the low-dimensional instance space, we learn a supervised projection to high-dimensional space spanned by the number of classes in the dataset under study. Imposing higher distinctions via exposing the notion of labels to the instances, lets to deploy one versus all ranking for each individual classes and selecting quality instances via adaptive thresholding of the overall scores. To prove the efficiency of our paradigm, we employ it for the purpose of texture understanding which is a hard recognition challenge due to high similarity of texture pixels and low dimensionality of their color features. Our experiments show considerable improvements in recognition performance over other local descriptors on several publicly available datasets.