 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeArian Hosseini
The N+ Implementation Details of RLHF with PPO: A Case Study on TL;DR Summarization
Mar 24, 2024
This work is the first to openly reproduce the Reinforcement Learning from Human Feedback (RLHF) scaling behaviors reported in OpenAI's seminal TL;DR summarization work. We create an RLHF pipeline from scratch, enumerate over 20 key implementation details, and share key insights during the reproduction. Our RLHF-trained Pythia models demonstrate significant gains in response quality that scale with model size, with our 2.8B, 6.9B models outperforming OpenAI's released 1.3B checkpoint. We publicly release the trained model checkpoints and code to facilitate further research and accelerate progress in the field (\url{https://github.com/vwxyzjn/summarize_from_feedback_details}).
V-STaR: Training Verifiers for Self-Taught Reasoners
Feb 09, 2024Common self-improvement approaches for large language models (LLMs), such as STaR (Zelikman et al., 2022), iteratively fine-tune LLMs on self-generated solutions to improve their problem-solving ability. However, these approaches discard the large amounts of incorrect solutions generated during this process, potentially neglecting valuable information in such solutions. To address this shortcoming, we propose V-STaR that utilizes both the correct and incorrect solutions generated during the self-improvement process to train a verifier using DPO that judges correctness of model-generated solutions. This verifier is used at inference time to select one solution among many candidate solutions. Running V-STaR for multiple iterations results in progressively better reasoners and verifiers, delivering a 4% to 17% test accuracy improvement over existing self-improvement and verification approaches on common code generation and math reasoning benchmarks with LLaMA2 models.
Deep Language Networks: Joint Prompt Training of Stacked LLMs using Variational Inference
Jun 21, 2023We view large language models (LLMs) as stochastic \emph{language layers} in a network, where the learnable parameters are the natural language \emph{prompts} at each layer. We stack two such layers, feeding the output of one layer to the next. We call the stacked architecture a \emph{Deep Language Network} (DLN). We first show how to effectively perform prompt optimization for a 1-Layer language network (DLN-1). We then show how to train 2-layer DLNs (DLN-2), where two prompts must be learnt. We consider the output of the first layer as a latent variable to marginalize, and devise a variational inference algorithm for joint prompt training. A DLN-2 reaches higher performance than a single layer, sometimes comparable to few-shot GPT-4 even when each LLM in the network is smaller and less powerful. The DLN code is open source: https://github.com/microsoft/deep-language-networks .
On the Compositional Generalization Gap of In-Context Learning
Nov 15, 2022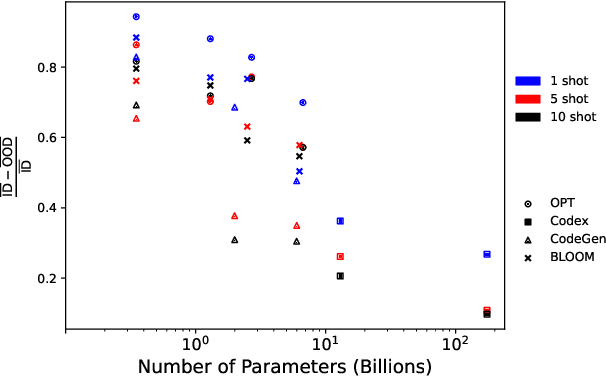
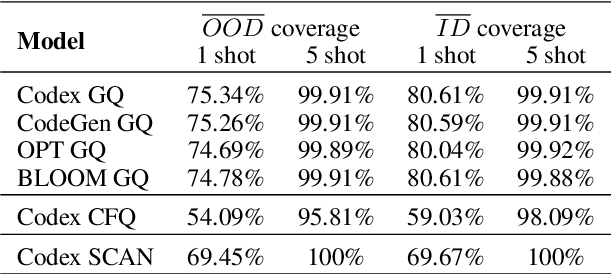

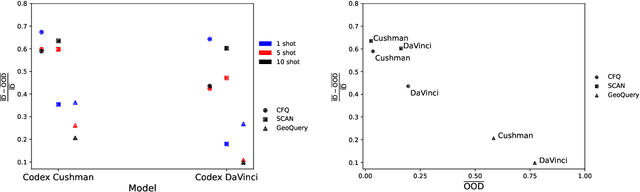
Pretrained large generative language models have shown great performance on many tasks, but exhibit low compositional generalization abilities. Scaling such models has been shown to improve their performance on various NLP tasks even just by conditioning them on a few examples to solve the task without any fine-tuning (also known as in-context learning). In this work, we look at the gap between the in-distribution (ID) and out-of-distribution (OOD) performance of such models in semantic parsing tasks with in-context learning. In the ID settings, the demonstrations are from the same split (test or train) that the model is being evaluated on, and in the OOD settings, they are from the other split. We look at how the relative generalization gap of in-context learning evolves as models are scaled up. We evaluate four model families, OPT, BLOOM, CodeGen and Codex on three semantic parsing datasets, CFQ, SCAN and GeoQuery with different number of exemplars, and observe a trend of decreasing relative generalization gap as models are scaled up.
Understanding by Understanding Not: Modeling Negation in Language Models
May 07, 2021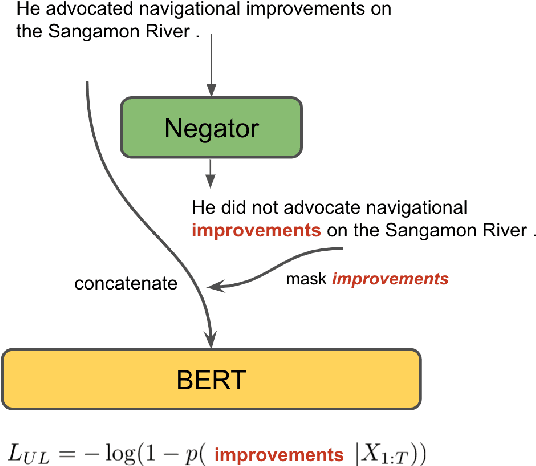



Negation is a core construction in natural language. Despite being very successful on many tasks, state-of-the-art pre-trained language models often handle negation incorrectly. To improve language models in this regard, we propose to augment the language modeling objective with an unlikelihood objective that is based on negated generic sentences from a raw text corpus. By training BERT with the resulting combined objective we reduce the mean top~1 error rate to 4% on the negated LAMA dataset. We also see some improvements on the negated NLI benchmarks.
Ordered Memory
Nov 03, 2019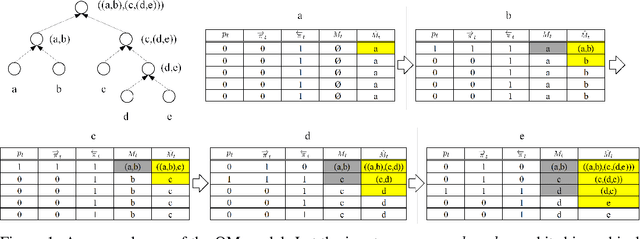
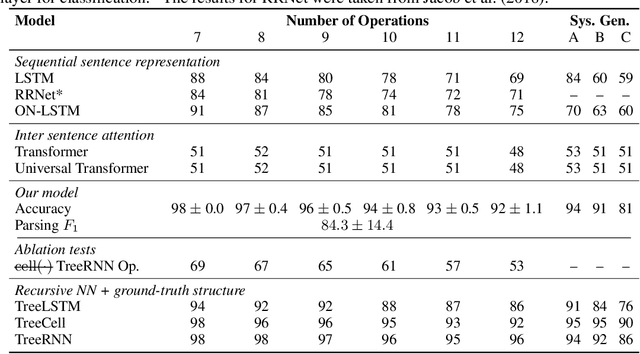

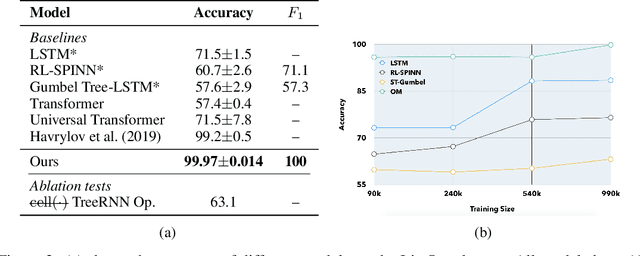
Stack-augmented recurrent neural networks (RNNs) have been of interest to the deep learning community for some time. However, the difficulty of training memory models remains a problem obstructing the widespread use of such models. In this paper, we propose the Ordered Memory architecture. Inspired by Ordered Neurons (Shen et al., 2018), we introduce a new attention-based mechanism and use its cumulative probability to control the writing and erasing operation of the memory. We also introduce a new Gated Recursive Cell to compose lower-level representations into higher-level representation. We demonstrate that our model achieves strong performance on the logical inference task (Bowman et al., 2015)and the ListOps (Nangia and Bowman, 2018) task. We can also interpret the model to retrieve the induced tree structure, and find that these induced structures align with the ground truth. Finally, we evaluate our model on the Stanford SentimentTreebank tasks (Socher et al., 2013), and find that it performs comparatively with the state-of-the-art methods in the literature.