 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeArman Zharmagambetov
AdvPrompter: Fast Adaptive Adversarial Prompting for LLMs
Apr 21, 2024
While recently Large Language Models (LLMs) have achieved remarkable successes, they are vulnerable to certain jailbreaking attacks that lead to generation of inappropriate or harmful content. Manual red-teaming requires finding adversarial prompts that cause such jailbreaking, e.g. by appending a suffix to a given instruction, which is inefficient and time-consuming. On the other hand, automatic adversarial prompt generation often leads to semantically meaningless attacks that can easily be detected by perplexity-based filters, may require gradient information from the TargetLLM, or do not scale well due to time-consuming discrete optimization processes over the token space. In this paper, we present a novel method that uses another LLM, called the AdvPrompter, to generate human-readable adversarial prompts in seconds, $\sim800\times$ faster than existing optimization-based approaches. We train the AdvPrompter using a novel algorithm that does not require access to the gradients of the TargetLLM. This process alternates between two steps: (1) generating high-quality target adversarial suffixes by optimizing the AdvPrompter predictions, and (2) low-rank fine-tuning of the AdvPrompter with the generated adversarial suffixes. The trained AdvPrompter generates suffixes that veil the input instruction without changing its meaning, such that the TargetLLM is lured to give a harmful response. Experimental results on popular open source TargetLLMs show state-of-the-art results on the AdvBench dataset, that also transfer to closed-source black-box LLM APIs. Further, we demonstrate that by fine-tuning on a synthetic dataset generated by AdvPrompter, LLMs can be made more robust against jailbreaking attacks while maintaining performance, i.e. high MMLU scores.
GenCO: Generating Diverse Solutions to Design Problems with Combinatorial Nature
Oct 03, 2023Generating diverse objects (e.g., images) using generative models (such as GAN or VAE) has achieved impressive results in the recent years, to help solve many design problems that are traditionally done by humans. Going beyond image generation, we aim to find solutions to more general design problems, in which both the diversity of the design and conformity of constraints are important. Such a setting has applications in computer graphics, animation, industrial design, material science, etc, in which we may want the output of the generator to follow discrete/combinatorial constraints and penalize any deviation, which is non-trivial with existing generative models and optimization solvers. To address this, we propose GenCO, a novel framework that conducts end-to-end training of deep generative models integrated with embedded combinatorial solvers, aiming to uncover high-quality solutions aligned with nonlinear objectives. While structurally akin to conventional generative models, GenCO diverges in its role - it focuses on generating instances of combinatorial optimization problems rather than final objects (e.g., images). This shift allows finer control over the generated outputs, enabling assessments of their feasibility and introducing an additional combinatorial loss component. We demonstrate the effectiveness of our approach on a variety of generative tasks characterized by combinatorial intricacies, including game level generation and map creation for path planning, consistently demonstrating its capability to yield diverse, high-quality solutions that reliably adhere to user-specified combinatorial properties.
Landscape Surrogate: Learning Decision Losses for Mathematical Optimization Under Partial Information
Jul 18, 2023



Recent works in learning-integrated optimization have shown promise in settings where the optimization problem is only partially observed or where general-purpose optimizers perform poorly without expert tuning. By learning an optimizer $\mathbf{g}$ to tackle these challenging problems with $f$ as the objective, the optimization process can be substantially accelerated by leveraging past experience. The optimizer can be trained with supervision from known optimal solutions or implicitly by optimizing the compound function $f\circ \mathbf{g}$. The implicit approach may not require optimal solutions as labels and is capable of handling problem uncertainty; however, it is slow to train and deploy due to frequent calls to optimizer $\mathbf{g}$ during both training and testing. The training is further challenged by sparse gradients of $\mathbf{g}$, especially for combinatorial solvers. To address these challenges, we propose using a smooth and learnable Landscape Surrogate $M$ as a replacement for $f\circ \mathbf{g}$. This surrogate, learnable by neural networks, can be computed faster than the solver $\mathbf{g}$, provides dense and smooth gradients during training, can generalize to unseen optimization problems, and is efficiently learned via alternating optimization. We test our approach on both synthetic problems, including shortest path and multidimensional knapsack, and real-world problems such as portfolio optimization, achieving comparable or superior objective values compared to state-of-the-art baselines while reducing the number of calls to $\mathbf{g}$. Notably, our approach outperforms existing methods for computationally expensive high-dimensional problems.
Sparse Oblique Decision Trees: A Tool to Understand and Manipulate Neural Net Features
Apr 07, 2021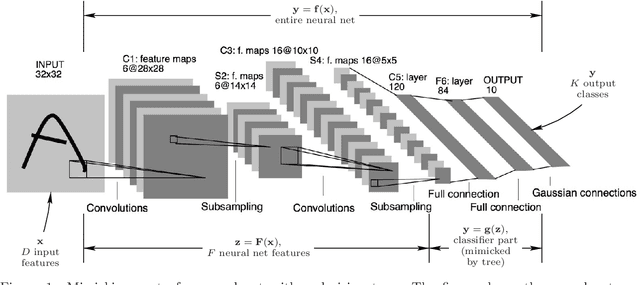

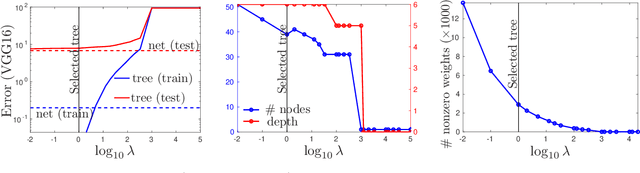

The widespread deployment of deep nets in practical applications has lead to a growing desire to understand how and why such black-box methods perform prediction. Much work has focused on understanding what part of the input pattern (an image, say) is responsible for a particular class being predicted, and how the input may be manipulated to predict a different class. We focus instead on understanding which of the internal features computed by the neural net are responsible for a particular class. We achieve this by mimicking part of the neural net with an oblique decision tree having sparse weight vectors at the decision nodes. Using the recently proposed Tree Alternating Optimization (TAO) algorithm, we are able to learn trees that are both highly accurate and interpretable. Such trees can faithfully mimic the part of the neural net they replaced, and hence they can provide insights into the deep net black box. Further, we show we can easily manipulate the neural net features in order to make the net predict, or not predict, a given class, thus showing that it is possible to carry out adversarial attacks at the level of the features. These insights and manipulations apply globally to the entire training and test set, not just at a local (single-instance) level. We demonstrate this robustly in the MNIST and ImageNet datasets with LeNet5 and VGG networks.
An Experimental Comparison of Old and New Decision Tree Algorithms
Nov 08, 2019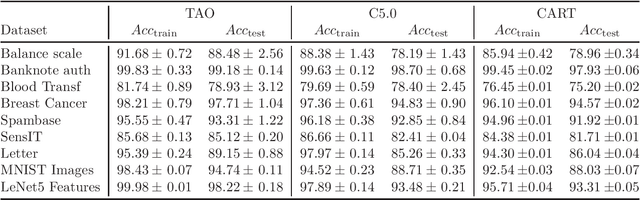
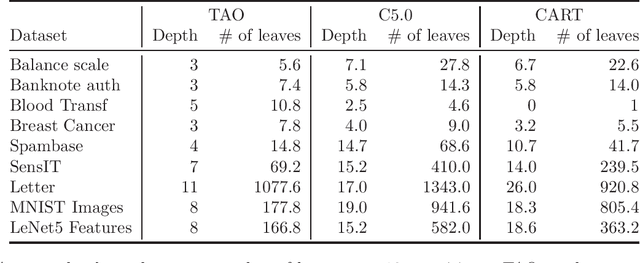
This paper presents a detailed comparison of a recently proposed algorithm for optimizing decision trees, tree alternating optimization (TAO), with other popular, established algorithms, such as CART and C5.0. We compare their performance on a number of datasets of different size, dimensionality and number of classes, across different performance factors: accuracy and tree size (in terms of the number of leaves or the depth of the tree). We find that TAO achieves higher accuracy in every single dataset, often by a large margin.