 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAshia C. Wilson
Algorithms that Approximate Data Removal: New Results and Limitations
Sep 25, 2022
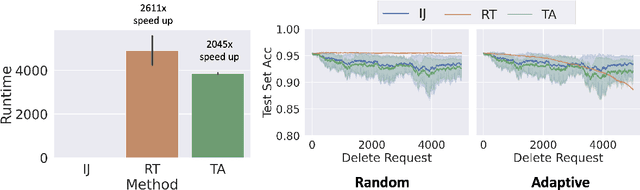
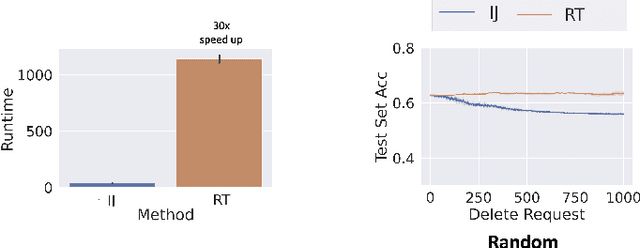
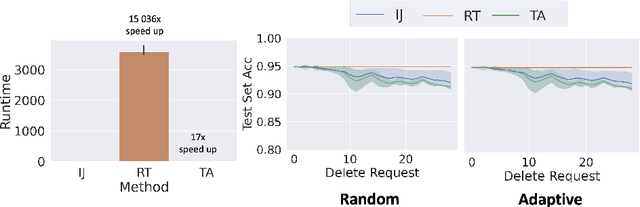
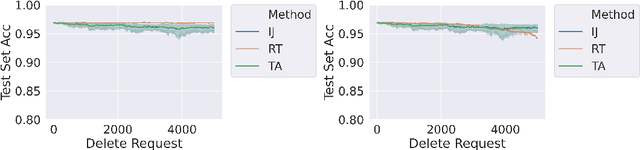
We study the problem of deleting user data from machine learning models trained using empirical risk minimization. Our focus is on learning algorithms which return the empirical risk minimizer and approximate unlearning algorithms that comply with deletion requests that come streaming minibatches. Leveraging the infintesimal jacknife, we develop an online unlearning algorithm that is both computationally and memory efficient. Unlike prior memory efficient unlearning algorithms, we target models that minimize objectives with non-smooth regularizers, such as the commonly used $\ell_1$, elastic net, or nuclear norm penalties. We also provide generalization, deletion capacity, and unlearning guarantees that are consistent with state of the art methods. Across a variety of benchmark datasets, our algorithm empirically improves upon the runtime of prior methods while maintaining the same memory requirements and test accuracy. Finally, we open a new direction of inquiry by proving that all approximate unlearning algorithms introduced so far fail to unlearn in problem settings where common hyperparameter tuning methods, such as cross-validation, have been used to select models.
The Marginal Value of Adaptive Gradient Methods in Machine Learning
May 22, 2018


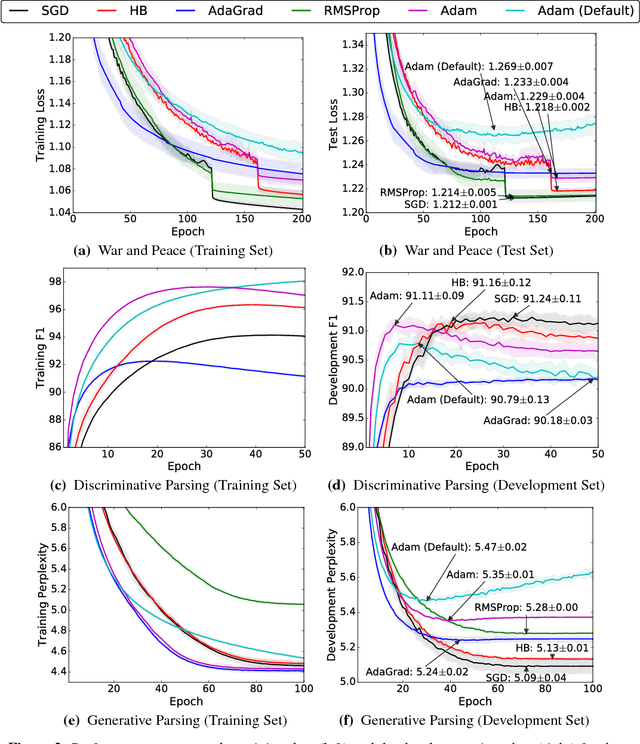
Adaptive optimization methods, which perform local optimization with a metric constructed from the history of iterates, are becoming increasingly popular for training deep neural networks. Examples include AdaGrad, RMSProp, and Adam. We show that for simple overparameterized problems, adaptive methods often find drastically different solutions than gradient descent (GD) or stochastic gradient descent (SGD). We construct an illustrative binary classification problem where the data is linearly separable, GD and SGD achieve zero test error, and AdaGrad, Adam, and RMSProp attain test errors arbitrarily close to half. We additionally study the empirical generalization capability of adaptive methods on several state-of-the-art deep learning models. We observe that the solutions found by adaptive methods generalize worse (often significantly worse) than SGD, even when these solutions have better training performance. These results suggest that practitioners should reconsider the use of adaptive methods to train neural networks.
A Variational Perspective on Accelerated Methods in Optimization
Mar 14, 2016Accelerated gradient methods play a central role in optimization, achieving optimal rates in many settings. While many generalizations and extensions of Nesterov's original acceleration method have been proposed, it is not yet clear what is the natural scope of the acceleration concept. In this paper, we study accelerated methods from a continuous-time perspective. We show that there is a Lagrangian functional that we call the \emph{Bregman Lagrangian} which generates a large class of accelerated methods in continuous time, including (but not limited to) accelerated gradient descent, its non-Euclidean extension, and accelerated higher-order gradient methods. We show that the continuous-time limit of all of these methods correspond to traveling the same curve in spacetime at different speeds. From this perspective, Nesterov's technique and many of its generalizations can be viewed as a systematic way to go from the continuous-time curves generated by the Bregman Lagrangian to a family of discrete-time accelerated algorithms.
Streaming Variational Bayes
Nov 20, 2013

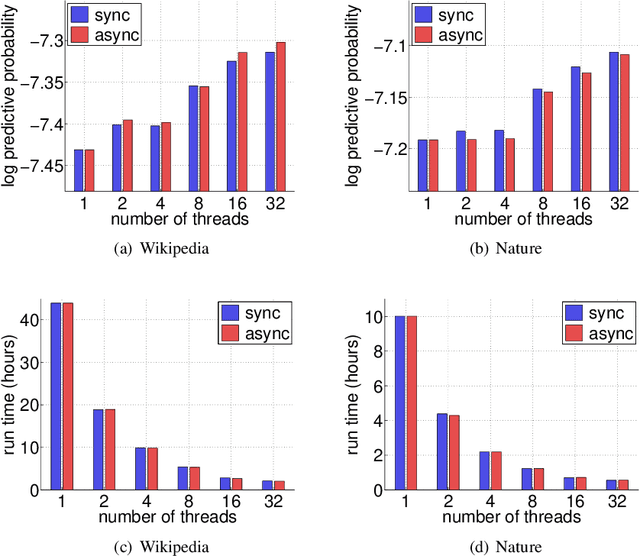
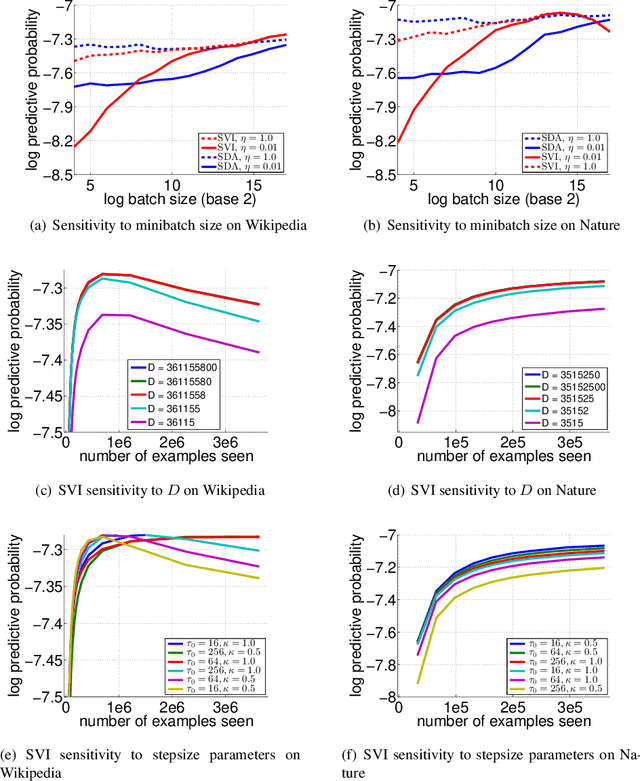
We present SDA-Bayes, a framework for (S)treaming, (D)istributed, (A)synchronous computation of a Bayesian posterior. The framework makes streaming updates to the estimated posterior according to a user-specified approximation batch primitive. We demonstrate the usefulness of our framework, with variational Bayes (VB) as the primitive, by fitting the latent Dirichlet allocation model to two large-scale document collections. We demonstrate the advantages of our algorithm over stochastic variational inference (SVI) by comparing the two after a single pass through a known amount of data---a case where SVI may be applied---and in the streaming setting, where SVI does not apply.