 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAshutosh Modi
IITK at SemEval-2024 Task 10: Who is the speaker? Improving Emotion Recognition and Flip Reasoning in Conversations via Speaker Embeddings
Apr 06, 2024
This paper presents our approach for the SemEval-2024 Task 10: Emotion Discovery and Reasoning its Flip in Conversations. For the Emotion Recognition in Conversations (ERC) task, we utilize a masked-memory network along with speaker participation. We propose a transformer-based speaker-centric model for the Emotion Flip Reasoning (EFR) task. We also introduce Probable Trigger Zone, a region of the conversation that is more likely to contain the utterances causing the emotion to flip. For sub-task 3, the proposed approach achieves a 5.9 (F1 score) improvement over the task baseline. The ablation study results highlight the significance of various design choices in the proposed method.
IITK at SemEval-2024 Task 2: Exploring the Capabilities of LLMs for Safe Biomedical Natural Language Inference for Clinical Trials
Apr 06, 2024Large Language models (LLMs) have demonstrated state-of-the-art performance in various natural language processing (NLP) tasks across multiple domains, yet they are prone to shortcut learning and factual inconsistencies. This research investigates LLMs' robustness, consistency, and faithful reasoning when performing Natural Language Inference (NLI) on breast cancer Clinical Trial Reports (CTRs) in the context of SemEval 2024 Task 2: Safe Biomedical Natural Language Inference for Clinical Trials. We examine the reasoning capabilities of LLMs and their adeptness at logical problem-solving. A comparative analysis is conducted on pre-trained language models (PLMs), GPT-3.5, and Gemini Pro under zero-shot settings using Retrieval-Augmented Generation (RAG) framework, integrating various reasoning chains. The evaluation yields an F1 score of 0.69, consistency of 0.71, and a faithfulness score of 0.90 on the test dataset.
IITK at SemEval-2024 Task 4: Hierarchical Embeddings for Detection of Persuasion Techniques in Memes
Apr 06, 2024Memes are one of the most popular types of content used in an online disinformation campaign. They are primarily effective on social media platforms since they can easily reach many users. Memes in a disinformation campaign achieve their goal of influencing the users through several rhetorical and psychological techniques, such as causal oversimplification, name-calling, and smear. The SemEval 2024 Task 4 \textit{Multilingual Detection of Persuasion Technique in Memes} on identifying such techniques in the memes is divided across three sub-tasks: ($\mathbf{1}$) Hierarchical multi-label classification using only textual content of the meme, ($\mathbf{2}$) Hierarchical multi-label classification using both, textual and visual content of the meme and ($\mathbf{3}$) Binary classification of whether the meme contains a persuasion technique or not using it's textual and visual content. This paper proposes an ensemble of Class Definition Prediction (CDP) and hyperbolic embeddings-based approaches for this task. We enhance meme classification accuracy and comprehensiveness by integrating HypEmo's hierarchical label embeddings (Chen et al., 2023) and a multi-task learning framework for emotion prediction. We achieve a hierarchical F1-score of 0.60, 0.67, and 0.48 on the respective sub-tasks.
IITK at SemEval-2024 Task 1: Contrastive Learning and Autoencoders for Semantic Textual Relatedness in Multilingual Texts
Apr 06, 2024This paper describes our system developed for the SemEval-2024 Task 1: Semantic Textual Relatedness. The challenge is focused on automatically detecting the degree of relatedness between pairs of sentences for 14 languages including both high and low-resource Asian and African languages. Our team participated in two subtasks consisting of Track A: supervised and Track B: unsupervised. This paper focuses on a BERT-based contrastive learning and similarity metric based approach primarily for the supervised track while exploring autoencoders for the unsupervised track. It also aims on the creation of a bigram relatedness corpus using negative sampling strategy, thereby producing refined word embeddings.
EtiCor: Corpus for Analyzing LLMs for Etiquettes
Oct 29, 2023Etiquettes are an essential ingredient of day-to-day interactions among people. Moreover, etiquettes are region-specific, and etiquettes in one region might contradict those in other regions. In this paper, we propose EtiCor, an Etiquettes Corpus, having texts about social norms from five different regions across the globe. The corpus provides a test bed for evaluating LLMs for knowledge and understanding of region-specific etiquettes. Additionally, we propose the task of Etiquette Sensitivity. We experiment with state-of-the-art LLMs (Delphi, Falcon40B, and GPT-3.5). Initial results indicate that LLMs, mostly fail to understand etiquettes from regions from non-Western world.
ISLTranslate: Dataset for Translating Indian Sign Language
Jul 11, 2023
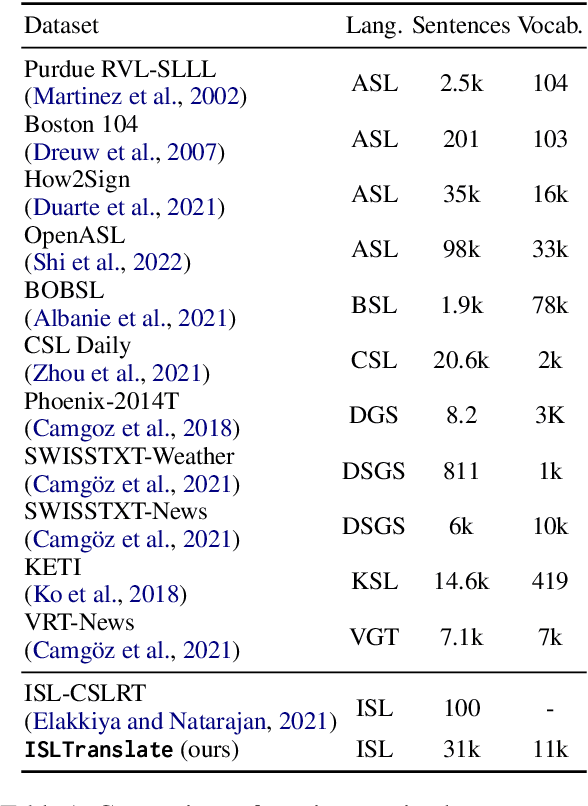


Sign languages are the primary means of communication for many hard-of-hearing people worldwide. Recently, to bridge the communication gap between the hard-of-hearing community and the rest of the population, several sign language translation datasets have been proposed to enable the development of statistical sign language translation systems. However, there is a dearth of sign language resources for the Indian sign language. This resource paper introduces ISLTranslate, a translation dataset for continuous Indian Sign Language (ISL) consisting of 31k ISL-English sentence/phrase pairs. To the best of our knowledge, it is the largest translation dataset for continuous Indian Sign Language. We provide a detailed analysis of the dataset. To validate the performance of existing end-to-end Sign language to spoken language translation systems, we benchmark the created dataset with a transformer-based model for ISL translation.
U-CREAT: Unsupervised Case Retrieval using Events extrAcTion
Jul 11, 2023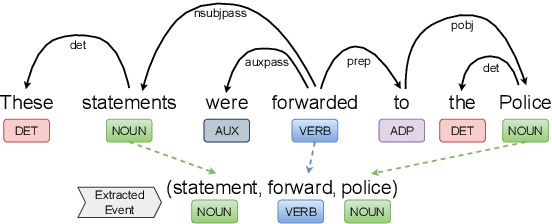
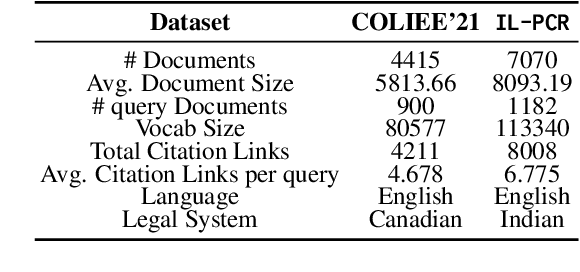
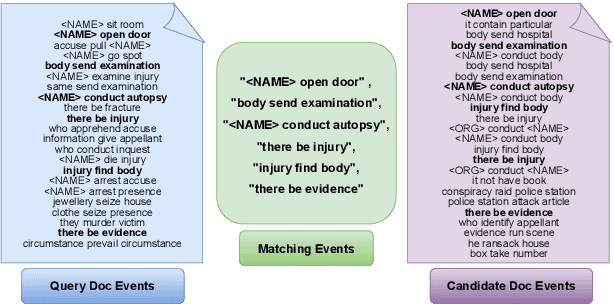
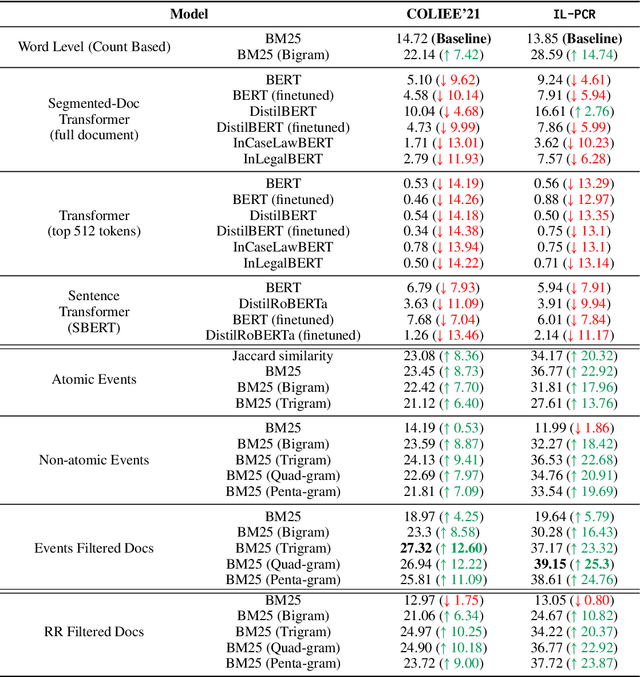
The task of Prior Case Retrieval (PCR) in the legal domain is about automatically citing relevant (based on facts and precedence) prior legal cases in a given query case. To further promote research in PCR, in this paper, we propose a new large benchmark (in English) for the PCR task: IL-PCR (Indian Legal Prior Case Retrieval) corpus. Given the complex nature of case relevance and the long size of legal documents, BM25 remains a strong baseline for ranking the cited prior documents. In this work, we explore the role of events in legal case retrieval and propose an unsupervised retrieval method-based pipeline U-CREAT (Unsupervised Case Retrieval using Events Extraction). We find that the proposed unsupervised retrieval method significantly increases performance compared to BM25 and makes retrieval faster by a considerable margin, making it applicable to real-time case retrieval systems. Our proposed system is generic, we show that it generalizes across two different legal systems (Indian and Canadian), and it shows state-of-the-art performance on the benchmarks for both the legal systems (IL-PCR and COLIEE corpora).
ScriptWorld: Text Based Environment For Learning Procedural Knowledge
Jul 08, 2023
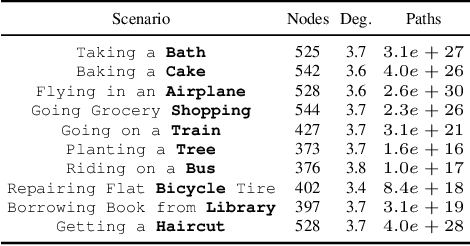
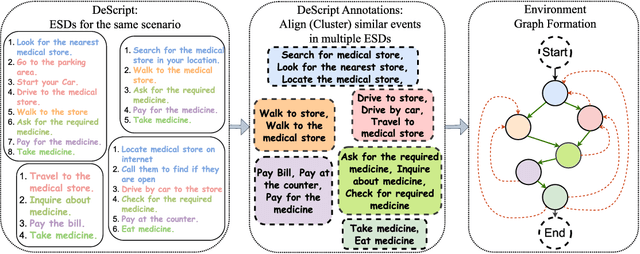

Text-based games provide a framework for developing natural language understanding and commonsense knowledge about the world in reinforcement learning based agents. Existing text-based environments often rely on fictional situations and characters to create a gaming framework and are far from real-world scenarios. In this paper, we introduce ScriptWorld: a text-based environment for teaching agents about real-world daily chores and hence imparting commonsense knowledge. To the best of our knowledge, it is the first interactive text-based gaming framework that consists of daily real-world human activities designed using scripts dataset. We provide gaming environments for 10 daily activities and perform a detailed analysis of the proposed environment. We develop RL-based baseline models/agents to play the games in Scriptworld. To understand the role of language models in such environments, we leverage features obtained from pre-trained language models in the RL agents. Our experiments show that prior knowledge obtained from a pre-trained language model helps to solve real-world text-based gaming environments. We release the environment via Github: https://github.com/Exploration-Lab/ScriptWorld
SemEval 2023 Task 6: LegalEval - Understanding Legal Texts
May 01, 2023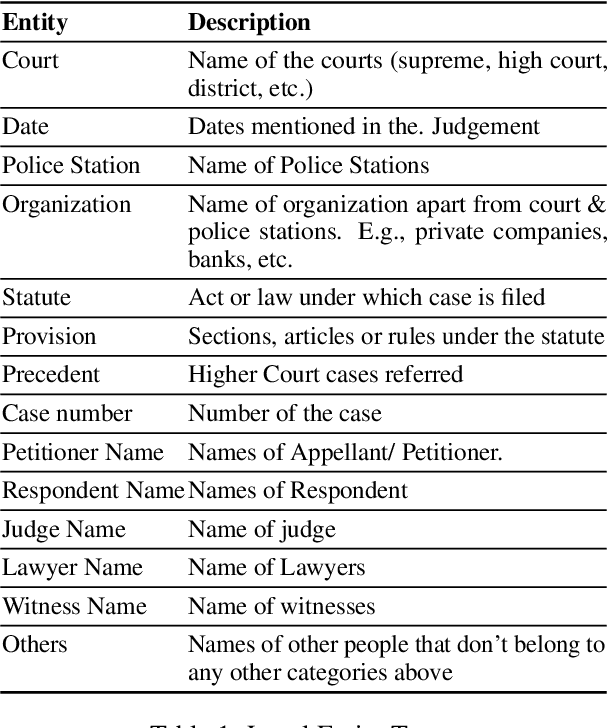


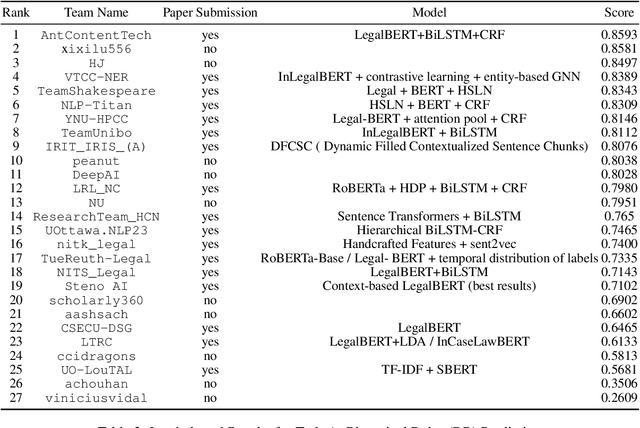
In populous countries, pending legal cases have been growing exponentially. There is a need for developing NLP-based techniques for processing and automatically understanding legal documents. To promote research in the area of Legal NLP we organized the shared task LegalEval - Understanding Legal Texts at SemEval 2023. LegalEval task has three sub-tasks: Task-A (Rhetorical Roles Labeling) is about automatically structuring legal documents into semantically coherent units, Task-B (Legal Named Entity Recognition) deals with identifying relevant entities in a legal document and Task-C (Court Judgement Prediction with Explanation) explores the possibility of automatically predicting the outcome of a legal case along with providing an explanation for the prediction. In total 26 teams (approx. 100 participants spread across the world) submitted systems paper. In each of the sub-tasks, the proposed systems outperformed the baselines; however, there is a lot of scope for improvement. This paper describes the tasks, and analyzes techniques proposed by various teams.
Generalized Product-of-Experts for Learning Multimodal Representations in Noisy Environments
Nov 07, 2022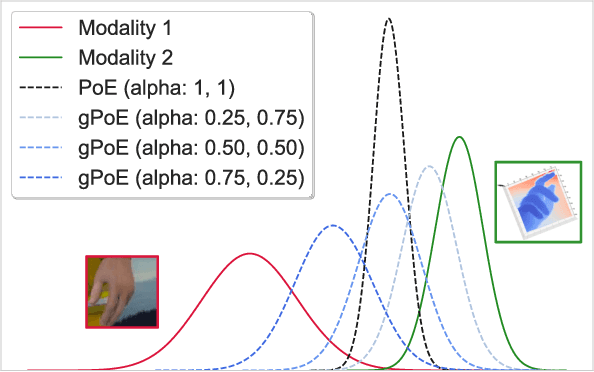
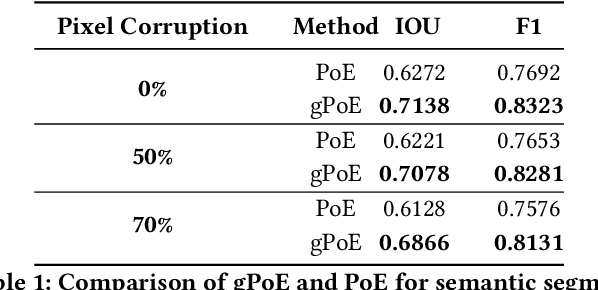
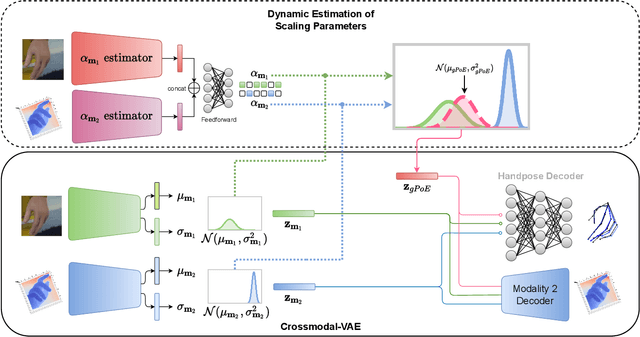
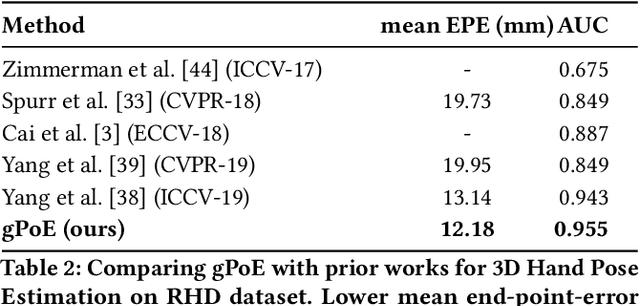
A real-world application or setting involves interaction between different modalities (e.g., video, speech, text). In order to process the multimodal information automatically and use it for an end application, Multimodal Representation Learning (MRL) has emerged as an active area of research in recent times. MRL involves learning reliable and robust representations of information from heterogeneous sources and fusing them. However, in practice, the data acquired from different sources are typically noisy. In some extreme cases, a noise of large magnitude can completely alter the semantics of the data leading to inconsistencies in the parallel multimodal data. In this paper, we propose a novel method for multimodal representation learning in a noisy environment via the generalized product of experts technique. In the proposed method, we train a separate network for each modality to assess the credibility of information coming from that modality, and subsequently, the contribution from each modality is dynamically varied while estimating the joint distribution. We evaluate our method on two challenging benchmarks from two diverse domains: multimodal 3D hand-pose estimation and multimodal surgical video segmentation. We attain state-of-the-art performance on both benchmarks. Our extensive quantitative and qualitative evaluations show the advantages of our method compared to previous approaches.