 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWeakly-supervised forced alignment of disfluent speech using phoneme-level modeling
May 30, 2023



The study of speech disorders can benefit greatly from time-aligned data. However, audio-text mismatches in disfluent speech cause rapid performance degradation for modern speech aligners, hindering the use of automatic approaches. In this work, we propose a simple and effective modification of alignment graph construction of CTC-based models using Weighted Finite State Transducers. The proposed weakly-supervised approach alleviates the need for verbatim transcription of speech disfluencies for forced alignment. During the graph construction, we allow the modeling of common speech disfluencies, i.e. repetitions and omissions. Further, we show that by assessing the degree of audio-text mismatch through the use of Oracle Error Rate, our method can be effectively used in the wild. Our evaluation on a corrupted version of the TIMIT test set and the UCLASS dataset shows significant improvements, particularly for recall, achieving a 23-25% relative improvement over our baselines.
Efficient Audio Captioning Transformer with Patchout and Text Guidance
Apr 06, 2023

Automated audio captioning is multi-modal translation task that aim to generate textual descriptions for a given audio clip. In this paper we propose a full Transformer architecture that utilizes Patchout as proposed in [1], significantly reducing the computational complexity and avoiding overfitting. The caption generation is partly conditioned on textual AudioSet tags extracted by a pre-trained classification model which is fine-tuned to maximize the semantic similarity between AudioSet labels and ground truth captions. To mitigate the data scarcity problem of Automated Audio Captioning we introduce transfer learning from an upstream audio-related task and an enlarged in-domain dataset. Moreover, we propose a method to apply Mixup augmentation for AAC. Ablation studies are carried out to investigate how Patchout and text guidance contribute to the final performance. The results show that the proposed techniques improve the performance of our system and while reducing the computational complexity. Our proposed method received the Judges Award at the Task6A of DCASE Challenge 2022.
Designing and Evaluating Speech Emotion Recognition Systems: A reality check case study with IEMOCAP
Apr 03, 2023


There is an imminent need for guidelines and standard test sets to allow direct and fair comparisons of speech emotion recognition (SER). While resources, such as the Interactive Emotional Dyadic Motion Capture (IEMOCAP) database, have emerged as widely-adopted reference corpora for researchers to develop and test models for SER, published work reveals a wide range of assumptions and variety in its use that challenge reproducibility and generalization. Based on a critical review of the latest advances in SER using IEMOCAP as the use case, our work aims at two contributions: First, using an analysis of the recent literature, including assumptions made and metrics used therein, we provide a set of SER evaluation guidelines. Second, using recent publications with open-sourced implementations, we focus on reproducibility assessment in SER.
Sample-Efficient Unsupervised Domain Adaptation of Speech Recognition Systems A case study for Modern Greek
Dec 31, 2022



Modern speech recognition systems exhibits rapid performance degradation under domain shift. This issue is especially prevalent in data-scarce settings, such as low-resource languages, where diversity of training data is limited. In this work we propose M2DS2, a simple and sample-efficient finetuning strategy for large pretrained speech models, based on mixed source and target domain self-supervision. We find that including source domain self-supervision stabilizes training and avoids mode collapse of the latent representations. For evaluation, we collect HParl, a $120$ hour speech corpus for Greek, consisting of plenary sessions in the Greek Parliament. We merge HParl with two popular Greek corpora to create GREC-MD, a test-bed for multi-domain evaluation of Greek ASR systems. In our experiments we find that, while other Unsupervised Domain Adaptation baselines fail in this resource-constrained environment, M2DS2 yields significant improvements for cross-domain adaptation, even when a only a few hours of in-domain audio are available. When we relax the problem in a weakly supervised setting, we find that independent adaptation for audio using M2DS2 and language using simple LM augmentation techniques is particularly effective, yielding word error rates comparable to the fully supervised baselines.
Visual Speech-Aware Perceptual 3D Facial Expression Reconstruction from Videos
Jul 22, 2022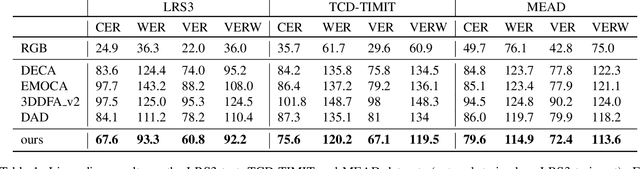



The recent state of the art on monocular 3D face reconstruction from image data has made some impressive advancements, thanks to the advent of Deep Learning. However, it has mostly focused on input coming from a single RGB image, overlooking the following important factors: a) Nowadays, the vast majority of facial image data of interest do not originate from single images but rather from videos, which contain rich dynamic information. b) Furthermore, these videos typically capture individuals in some form of verbal communication (public talks, teleconferences, audiovisual human-computer interactions, interviews, monologues/dialogues in movies, etc). When existing 3D face reconstruction methods are applied in such videos, the artifacts in the reconstruction of the shape and motion of the mouth area are often severe, since they do not match well with the speech audio. To overcome the aforementioned limitations, we present the first method for visual speech-aware perceptual reconstruction of 3D mouth expressions. We do this by proposing a "lipread" loss, which guides the fitting process so that the elicited perception from the 3D reconstructed talking head resembles that of the original video footage. We demonstrate that, interestingly, the lipread loss is better suited for 3D reconstruction of mouth movements compared to traditional landmark losses, and even direct 3D supervision. Furthermore, the devised method does not rely on any text transcriptions or corresponding audio, rendering it ideal for training in unlabeled datasets. We verify the efficiency of our method through exhaustive objective evaluations on three large-scale datasets, as well as subjective evaluation with two web-based user studies.
Regotron: Regularizing the Tacotron2 architecture via monotonic alignment loss
Apr 28, 2022



Recent deep learning Text-to-Speech (TTS) systems have achieved impressive performance by generating speech close to human parity. However, they suffer from training stability issues as well as incorrect alignment of the intermediate acoustic representation with the input text sequence. In this work, we introduce Regotron, a regularized version of Tacotron2 which aims to alleviate the training issues and at the same time produce monotonic alignments. Our method augments the vanilla Tacotron2 objective function with an additional term, which penalizes non-monotonic alignments in the location-sensitive attention mechanism. By properly adjusting this regularization term we show that the loss curves become smoother, and at the same time Regotron consistently produces monotonic alignments in unseen examples even at an early stage (13\% of the total number of epochs) of its training process, whereas the fully converged Tacotron2 fails to do so. Moreover, our proposed regularization method has no additional computational overhead, while reducing common TTS mistakes and achieving slighlty improved speech naturalness according to subjective mean opinion scores (MOS) collected from 50 evaluators.
Zero-Shot Cross-lingual Aphasia Detection using Automatic Speech Recognition
Apr 01, 2022



Aphasia is a common speech and language disorder, typically caused by a brain injury or a stroke, that affects millions of people worldwide. Detecting and assessing Aphasia in patients is a difficult, time-consuming process, and numerous attempts to automate it have been made, the most successful using machine learning models trained on aphasic speech data. Like in many medical applications, aphasic speech data is scarce and the problem is exacerbated in so-called "low resource" languages, which are, for this task, most languages excluding English. We attempt to leverage available data in English and achieve zero-shot aphasia detection in low-resource languages such as Greek and French, by using language-agnostic linguistic features. Current cross-lingual aphasia detection approaches rely on manually extracted transcripts. We propose an end-to-end pipeline using pre-trained Automatic Speech Recognition (ASR) models that share cross-lingual speech representations and are fine-tuned for our desired low-resource languages. To further boost our ASR model's performance, we also combine it with a language model. We show that our ASR-based end-to-end pipeline offers comparable results to previous setups using human-annotated transcripts.
EmpBot: A T5-based Empathetic Chatbot focusing on Sentiments
Oct 30, 2021



In this paper, we introduce EmpBot: an end-to-end empathetic chatbot. Empathetic conversational agents should not only understand what is being discussed, but also acknowledge the implied feelings of the conversation partner and respond appropriately. To this end, we propose a method based on a transformer pretrained language model (T5). Specifically, during finetuning we propose to use three objectives: response language modeling, sentiment understanding, and empathy forcing. The first objective is crucial for generating relevant and coherent responses, while the next ones are significant for acknowledging the sentimental state of the conversational partner and for favoring empathetic responses. We evaluate our model on the EmpatheticDialogues dataset using both automated metrics and human evaluation. The inclusion of the sentiment understanding and empathy forcing auxiliary losses favor empathetic responses, as human evaluation results indicate, comparing with the current state-of-the-art.
AudioVisual Speech Synthesis: A brief literature review
Feb 18, 2021This brief literature review studies the problem of audiovisual speech synthesis, which is the problem of generating an animated talking head given a text as input. Due to the high complexity of this problem, we approach it as the composition of two problems. Specifically, that of Text-to-Speech (TTS) synthesis as well as the voice-driven talking head animation. For TTS, we present models that are used to map text to intermediate acoustic representations, e.g. mel-spectrograms, as well as models that generate voice signals conditioned on these intermediate representations, i.e vocoders. For the talking-head animation problem, we categorize approaches based on whether they produce human faces or anthropomorphic figures. An attempt is also made to discuss the importance of the choice of facial models in the second case. Throughout the review, we briefly describe the most important work in audiovisual speech synthesis, trying to highlight the advantages and disadvantages of the various approaches.