 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAtsushi Nitanda
Convergence of mean-field Langevin dynamics: Time and space discretization, stochastic gradient, and variance reduction
Jun 12, 2023

The mean-field Langevin dynamics (MFLD) is a nonlinear generalization of the Langevin dynamics that incorporates a distribution-dependent drift, and it naturally arises from the optimization of two-layer neural networks via (noisy) gradient descent. Recent works have shown that MFLD globally minimizes an entropy-regularized convex functional in the space of measures. However, all prior analyses assumed the infinite-particle or continuous-time limit, and cannot handle stochastic gradient updates. We provide an general framework to prove a uniform-in-time propagation of chaos for MFLD that takes into account the errors due to finite-particle approximation, time-discretization, and stochastic gradient approximation. To demonstrate the wide applicability of this framework, we establish quantitative convergence rate guarantees to the regularized global optimal solution under (i) a wide range of learning problems such as neural network in the mean-field regime and MMD minimization, and (ii) different gradient estimators including SGD and SVRG. Despite the generality of our results, we achieve an improved convergence rate in both the SGD and SVRG settings when specialized to the standard Langevin dynamics.
Tight and fast generalization error bound of graph embedding in metric space
May 13, 2023Recent studies have experimentally shown that we can achieve in non-Euclidean metric space effective and efficient graph embedding, which aims to obtain the vertices' representations reflecting the graph's structure in the metric space. Specifically, graph embedding in hyperbolic space has experimentally succeeded in embedding graphs with hierarchical-tree structure, e.g., data in natural languages, social networks, and knowledge bases. However, recent theoretical analyses have shown a much higher upper bound on non-Euclidean graph embedding's generalization error than Euclidean one's, where a high generalization error indicates that the incompleteness and noise in the data can significantly damage learning performance. It implies that the existing bound cannot guarantee the success of graph embedding in non-Euclidean metric space in a practical training data size, which can prevent non-Euclidean graph embedding's application in real problems. This paper provides a novel upper bound of graph embedding's generalization error by evaluating the local Rademacher complexity of the model as a function set of the distances of representation couples. Our bound clarifies that the performance of graph embedding in non-Euclidean metric space, including hyperbolic space, is better than the existing upper bounds suggest. Specifically, our new upper bound is polynomial in the metric space's geometric radius $R$ and can be $O(\frac{1}{S})$ at the fastest, where $S$ is the training data size. Our bound is significantly tighter and faster than the existing one, which can be exponential to $R$ and $O(\frac{1}{\sqrt{S}})$ at the fastest. Specific calculations on example cases show that graph embedding in non-Euclidean metric space can outperform that in Euclidean space with much smaller training data than the existing bound has suggested.
Primal and Dual Analysis of Entropic Fictitious Play for Finite-sum Problems
Mar 06, 2023



The entropic fictitious play (EFP) is a recently proposed algorithm that minimizes the sum of a convex functional and entropy in the space of measures -- such an objective naturally arises in the optimization of a two-layer neural network in the mean-field regime. In this work, we provide a concise primal-dual analysis of EFP in the setting where the learning problem exhibits a finite-sum structure. We establish quantitative global convergence guarantees for both the continuous-time and discrete-time dynamics based on properties of a proximal Gibbs measure introduced in Nitanda et al. (2022). Furthermore, our primal-dual framework entails a memory-efficient particle-based implementation of the EFP update, and also suggests a connection to gradient boosting methods. We illustrate the efficiency of our novel implementation in experiments including neural network optimization and image synthesis.
Parameter Averaging for SGD Stabilizes the Implicit Bias towards Flat Regions
Feb 18, 2023



Stochastic gradient descent is a workhorse for training deep neural networks due to its excellent generalization performance. Several studies demonstrated this success is attributed to the implicit bias of the method that prefers a flat minimum and developed new methods based on this perspective. Recently, Izmailov et al. (2018) empirically observed that an averaged stochastic gradient descent with a large step size can bring out the implicit bias more effectively and can converge more stably to a flat minimum than the vanilla stochastic gradient descent. In our work, we theoretically justify this observation by showing that the averaging scheme improves the bias-optimization tradeoff coming from the stochastic gradient noise: a large step size amplifies the bias but makes convergence unstable, and vice versa. Specifically, we show that the averaged stochastic gradient descent can get closer to a solution of a penalized objective on the sharpness than the vanilla stochastic gradient descent using the same step size under certain conditions. In experiments, we verify our theory and show this learning scheme significantly improves performance.
Koopman-Based Bound for Generalization: New Aspect of Neural Networks Regarding Nonlinear Noise Filtering
Feb 12, 2023



We propose a new bound for generalization of neural networks using Koopman operators. Unlike most of the existing works, we focus on the role of the final nonlinear transformation of the networks. Our bound is described by the reciprocal of the determinant of the weight matrices and is tighter than existing norm-based bounds when the weight matrices do not have small singular values. According to existing theories about the low-rankness of the weight matrices, it may be counter-intuitive that we focus on the case where singular values of weight matrices are not small. However, motivated by the final nonlinear transformation, we can see that our result sheds light on a new perspective regarding a noise filtering property of neural networks. Since our bound comes from Koopman operators, this work also provides a connection between operator-theoretic analysis and generalization of neural networks. Numerical results support the validity of our theoretical results.
Convex Analysis of the Mean Field Langevin Dynamics
Jan 25, 2022

As an example of the nonlinear Fokker-Planck equation, the mean field Langevin dynamics attracts attention due to its connection to (noisy) gradient descent on infinitely wide neural networks in the mean field regime, and hence the convergence property of the dynamics is of great theoretical interest. In this work, we give a simple and self-contained convergence rate analysis of the mean field Langevin dynamics with respect to the (regularized) objective function in both continuous and discrete time settings. The key ingredient of our proof is a proximal Gibbs distribution $p_q$ associated with the dynamics, which, in combination of techniques in [Vempala and Wibisono (2019)], allows us to develop a convergence theory parallel to classical results in convex optimization. Furthermore, we reveal that $p_q$ connects to the duality gap in the empirical risk minimization setting, which enables efficient empirical evaluation of the algorithm convergence.
Generalization Error Bound for Hyperbolic Ordinal Embedding
May 21, 2021Hyperbolic ordinal embedding (HOE) represents entities as points in hyperbolic space so that they agree as well as possible with given constraints in the form of entity i is more similar to entity j than to entity k. It has been experimentally shown that HOE can obtain representations of hierarchical data such as a knowledge base and a citation network effectively, owing to hyperbolic space's exponential growth property. However, its theoretical analysis has been limited to ideal noiseless settings, and its generalization error in compensation for hyperbolic space's exponential representation ability has not been guaranteed. The difficulty is that existing generalization error bound derivations for ordinal embedding based on the Gramian matrix do not work in HOE, since hyperbolic space is not inner-product space. In this paper, through our novel characterization of HOE with decomposed Lorentz Gramian matrices, we provide a generalization error bound of HOE for the first time, which is at most exponential with respect to the embedding space's radius. Our comparison between the bounds of HOE and Euclidean ordinal embedding shows that HOE's generalization error is reasonable as a cost for its exponential representation ability.
BODAME: Bilevel Optimization for Defense Against Model Extraction
Mar 11, 2021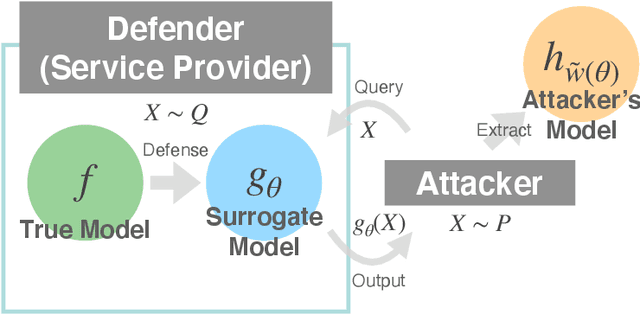

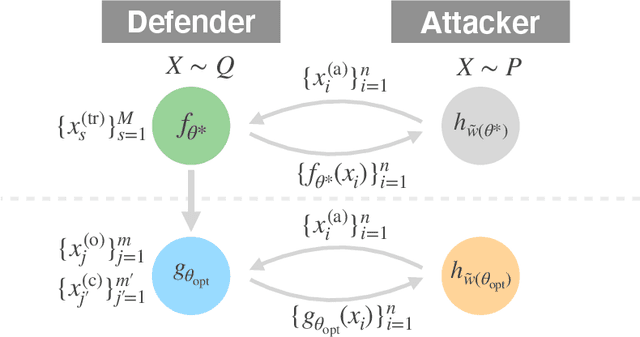
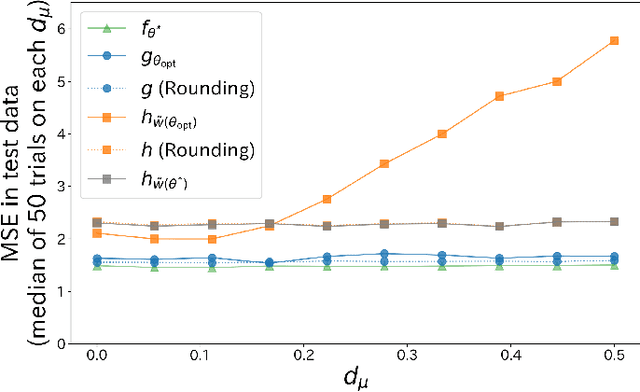
Model extraction attacks have become serious issues for service providers using machine learning. We consider an adversarial setting to prevent model extraction under the assumption that attackers will make their best guess on the service provider's model using query accesses, and propose to build a surrogate model that significantly keeps away the predictions of the attacker's model from those of the true model. We formulate the problem as a non-convex constrained bilevel optimization problem and show that for kernel models, it can be transformed into a non-convex 1-quadratically constrained quadratic program with a polynomial-time algorithm to find the global optimum. Moreover, we give a tractable transformation and an algorithm for more complicated models that are learned by using stochastic gradient descent-based algorithms. Numerical experiments show that the surrogate model performs well compared with existing defense models when the difference between the attacker's and service provider's distributions is large. We also empirically confirm the generalization ability of the surrogate model.
Particle Dual Averaging: Optimization of Mean Field Neural Networks with Global Convergence Rate Analysis
Dec 31, 2020



We propose the particle dual averaging (PDA) method, which generalizes the dual averaging method in convex optimization to the optimization over probability distributions with quantitative runtime guarantee. The algorithm consists of an inner loop and outer loop: the inner loop utilizes the Langevin algorithm to approximately solve for a stationary distribution, which is then optimized in the outer loop. The method can thus be interpreted as an extension of the Langevin algorithm to naturally handle nonlinear functional on the probability space. An important application of the proposed method is the optimization of two-layer neural network in the mean field regime, which is theoretically attractive due to the presence of nonlinear feature learning, but quantitative convergence rate can be challenging to establish. We show that neural networks in the mean field limit can be globally optimized by PDA. Furthermore, we characterize the convergence rate by leveraging convex optimization theory in finite-dimensional spaces. Our theoretical results are supported by numerical simulations on neural networks with reasonable size.
A Novel Global Spatial Attention Mechanism in Convolutional Neural Network for Medical Image Classification
Jul 31, 2020



Spatial attention has been introduced to convolutional neural networks (CNNs) for improving both their performance and interpretability in visual tasks including image classification. The essence of the spatial attention is to learn a weight map which represents the relative importance of activations within the same layer or channel. All existing attention mechanisms are local attentions in the sense that weight maps are image-specific. However, in the medical field, there are cases that all the images should share the same weight map because the set of images record the same kind of symptom related to the same object and thereby share the same structural content. In this paper, we thus propose a novel global spatial attention mechanism in CNNs mainly for medical image classification. The global weight map is instantiated by a decision boundary between important pixels and unimportant pixels. And we propose to realize the decision boundary by a binary classifier in which the intensities of all images at a pixel are the features of the pixel. The binary classification is integrated into an image classification CNN and is to be optimized together with the CNN. Experiments on two medical image datasets and one facial expression dataset showed that with the proposed attention, not only the performance of four powerful CNNs which are GoogleNet, VGG, ResNet, and DenseNet can be improved, but also meaningful attended regions can be obtained, which is beneficial for understanding the content of images of a domain.