 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAykut Erdem
SonicDiffusion: Audio-Driven Image Generation and Editing with Pretrained Diffusion Models
May 01, 2024
We are witnessing a revolution in conditional image synthesis with the recent success of large scale text-to-image generation methods. This success also opens up new opportunities in controlling the generation and editing process using multi-modal input. While spatial control using cues such as depth, sketch, and other images has attracted a lot of research, we argue that another equally effective modality is audio since sound and sight are two main components of human perception. Hence, we propose a method to enable audio-conditioning in large scale image diffusion models. Our method first maps features obtained from audio clips to tokens that can be injected into the diffusion model in a fashion similar to text tokens. We introduce additional audio-image cross attention layers which we finetune while freezing the weights of the original layers of the diffusion model. In addition to audio conditioned image generation, our method can also be utilized in conjuction with diffusion based editing methods to enable audio conditioned image editing. We demonstrate our method on a wide range of audio and image datasets. We perform extensive comparisons with recent methods and show favorable performance.
Hippocrates: An Open-Source Framework for Advancing Large Language Models in Healthcare
Apr 25, 2024The integration of Large Language Models (LLMs) into healthcare promises to transform medical diagnostics, research, and patient care. Yet, the progression of medical LLMs faces obstacles such as complex training requirements, rigorous evaluation demands, and the dominance of proprietary models that restrict academic exploration. Transparent, comprehensive access to LLM resources is essential for advancing the field, fostering reproducibility, and encouraging innovation in healthcare AI. We present Hippocrates, an open-source LLM framework specifically developed for the medical domain. In stark contrast to previous efforts, it offers unrestricted access to its training datasets, codebase, checkpoints, and evaluation protocols. This open approach is designed to stimulate collaborative research, allowing the community to build upon, refine, and rigorously evaluate medical LLMs within a transparent ecosystem. Also, we introduce Hippo, a family of 7B models tailored for the medical domain, fine-tuned from Mistral and LLaMA2 through continual pre-training, instruction tuning, and reinforcement learning from human and AI feedback. Our models outperform existing open medical LLMs models by a large-margin, even surpassing models with 70B parameters. Through Hippocrates, we aspire to unlock the full potential of LLMs not just to advance medical knowledge and patient care but also to democratize the benefits of AI research in healthcare, making them available across the globe.
Sequential Compositional Generalization in Multimodal Models
Apr 18, 2024The rise of large-scale multimodal models has paved the pathway for groundbreaking advances in generative modeling and reasoning, unlocking transformative applications in a variety of complex tasks. However, a pressing question that remains is their genuine capability for stronger forms of generalization, which has been largely underexplored in the multimodal setting. Our study aims to address this by examining sequential compositional generalization using \textsc{CompAct} (\underline{Comp}ositional \underline{Act}ivities)\footnote{Project Page: \url{http://cyberiada.github.io/CompAct}}, a carefully constructed, perceptually grounded dataset set within a rich backdrop of egocentric kitchen activity videos. Each instance in our dataset is represented with a combination of raw video footage, naturally occurring sound, and crowd-sourced step-by-step descriptions. More importantly, our setup ensures that the individual concepts are consistently distributed across training and evaluation sets, while their compositions are novel in the evaluation set. We conduct a comprehensive assessment of several unimodal and multimodal models. Our findings reveal that bi-modal and tri-modal models exhibit a clear edge over their text-only counterparts. This highlights the importance of multimodality while charting a trajectory for future research in this domain.
ViLMA: A Zero-Shot Benchmark for Linguistic and Temporal Grounding in Video-Language Models
Nov 13, 2023With the ever-increasing popularity of pretrained Video-Language Models (VidLMs), there is a pressing need to develop robust evaluation methodologies that delve deeper into their visio-linguistic capabilities. To address this challenge, we present ViLMA (Video Language Model Assessment), a task-agnostic benchmark that places the assessment of fine-grained capabilities of these models on a firm footing. Task-based evaluations, while valuable, fail to capture the complexities and specific temporal aspects of moving images that VidLMs need to process. Through carefully curated counterfactuals, ViLMA offers a controlled evaluation suite that sheds light on the true potential of these models, as well as their performance gaps compared to human-level understanding. ViLMA also includes proficiency tests, which assess basic capabilities deemed essential to solving the main counterfactual tests. We show that current VidLMs' grounding abilities are no better than those of vision-language models which use static images. This is especially striking once the performance on proficiency tests is factored in. Our benchmark serves as a catalyst for future research on VidLMs, helping to highlight areas that still need to be explored.
Harnessing Dataset Cartography for Improved Compositional Generalization in Transformers
Oct 18, 2023Neural networks have revolutionized language modeling and excelled in various downstream tasks. However, the extent to which these models achieve compositional generalization comparable to human cognitive abilities remains a topic of debate. While existing approaches in the field have mainly focused on novel architectures and alternative learning paradigms, we introduce a pioneering method harnessing the power of dataset cartography (Swayamdipta et al., 2020). By strategically identifying a subset of compositional generalization data using this approach, we achieve a remarkable improvement in model accuracy, yielding enhancements of up to 10% on CFQ and COGS datasets. Notably, our technique incorporates dataset cartography as a curriculum learning criterion, eliminating the need for hyperparameter tuning while consistently achieving superior performance. Our findings highlight the untapped potential of dataset cartography in unleashing the full capabilities of compositional generalization within Transformer models. Our code is available at https://github.com/cyberiada/cartography-for-compositionality.
Hyperspectral Image Denoising via Self-Modulating Convolutional Neural Networks
Sep 15, 2023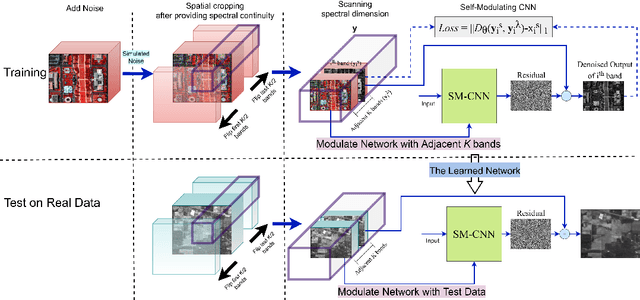

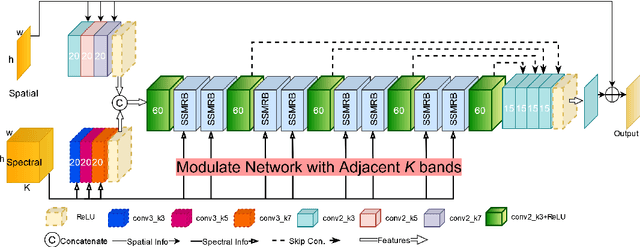
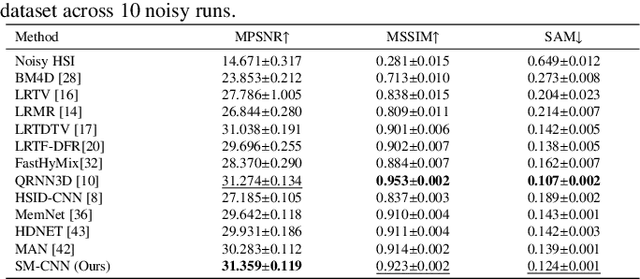
Compared to natural images, hyperspectral images (HSIs) consist of a large number of bands, with each band capturing different spectral information from a certain wavelength, even some beyond the visible spectrum. These characteristics of HSIs make them highly effective for remote sensing applications. That said, the existing hyperspectral imaging devices introduce severe degradation in HSIs. Hence, hyperspectral image denoising has attracted lots of attention by the community lately. While recent deep HSI denoising methods have provided effective solutions, their performance under real-life complex noise remains suboptimal, as they lack adaptability to new data. To overcome these limitations, in our work, we introduce a self-modulating convolutional neural network which we refer to as SM-CNN, which utilizes correlated spectral and spatial information. At the core of the model lies a novel block, which we call spectral self-modulating residual block (SSMRB), that allows the network to transform the features in an adaptive manner based on the adjacent spectral data, enhancing the network's ability to handle complex noise. In particular, the introduction of SSMRB transforms our denoising network into a dynamic network that adapts its predicted features while denoising every input HSI with respect to its spatio-spectral characteristics. Experimental analysis on both synthetic and real data shows that the proposed SM-CNN outperforms other state-of-the-art HSI denoising methods both quantitatively and qualitatively on public benchmark datasets.
Spherical Vision Transformer for 360-degree Video Saliency Prediction
Aug 24, 2023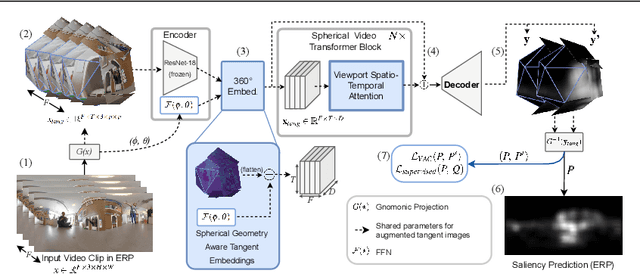
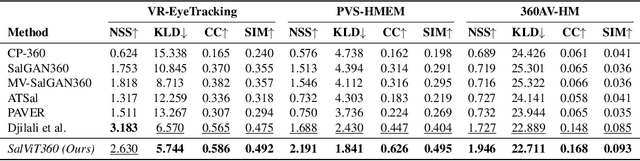

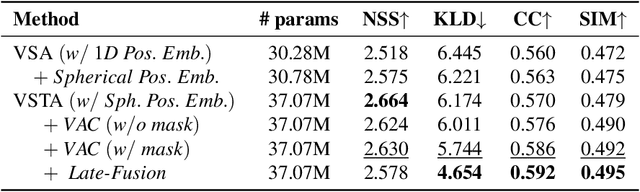
The growing interest in omnidirectional videos (ODVs) that capture the full field-of-view (FOV) has gained 360-degree saliency prediction importance in computer vision. However, predicting where humans look in 360-degree scenes presents unique challenges, including spherical distortion, high resolution, and limited labelled data. We propose a novel vision-transformer-based model for omnidirectional videos named SalViT360 that leverages tangent image representations. We introduce a spherical geometry-aware spatiotemporal self-attention mechanism that is capable of effective omnidirectional video understanding. Furthermore, we present a consistency-based unsupervised regularization term for projection-based 360-degree dense-prediction models to reduce artefacts in the predictions that occur after inverse projection. Our approach is the first to employ tangent images for omnidirectional saliency prediction, and our experimental results on three ODV saliency datasets demonstrate its effectiveness compared to the state-of-the-art.
CLIP-Guided StyleGAN Inversion for Text-Driven Real Image Editing
Jul 18, 2023
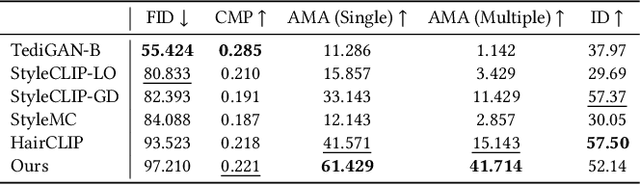

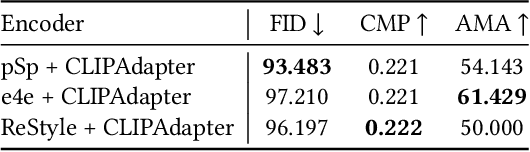
Researchers have recently begun exploring the use of StyleGAN-based models for real image editing. One particularly interesting application is using natural language descriptions to guide the editing process. Existing approaches for editing images using language either resort to instance-level latent code optimization or map predefined text prompts to some editing directions in the latent space. However, these approaches have inherent limitations. The former is not very efficient, while the latter often struggles to effectively handle multi-attribute changes. To address these weaknesses, we present CLIPInverter, a new text-driven image editing approach that is able to efficiently and reliably perform multi-attribute changes. The core of our method is the use of novel, lightweight text-conditioned adapter layers integrated into pretrained GAN-inversion networks. We demonstrate that by conditioning the initial inversion step on the CLIP embedding of the target description, we are able to obtain more successful edit directions. Additionally, we use a CLIP-guided refinement step to make corrections in the resulting residual latent codes, which further improves the alignment with the text prompt. Our method outperforms competing approaches in terms of manipulation accuracy and photo-realism on various domains including human faces, cats, and birds, as shown by our qualitative and quantitative results.
HyperE2VID: Improving Event-Based Video Reconstruction via Hypernetworks
May 10, 2023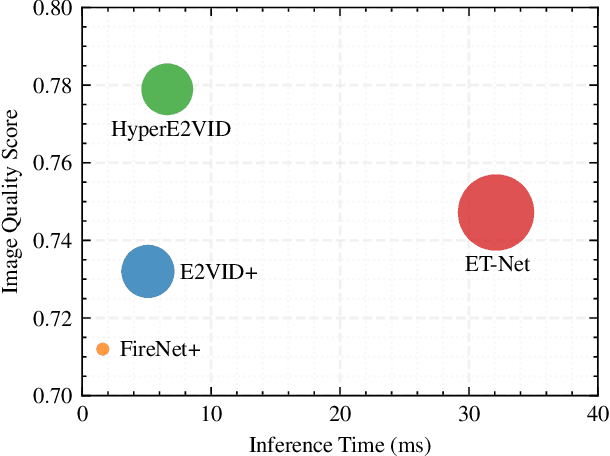
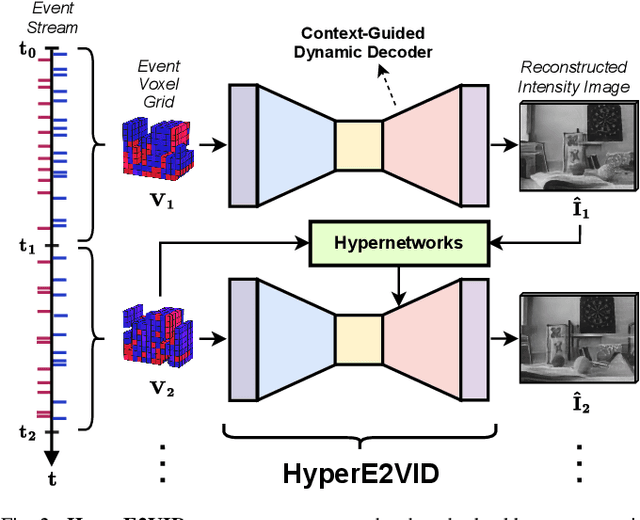
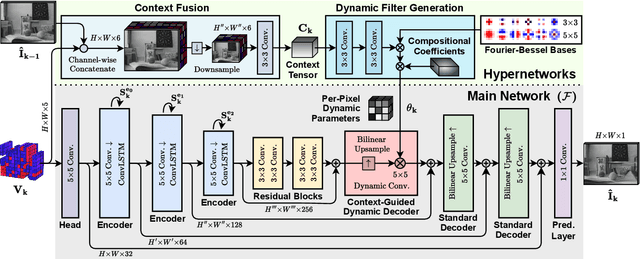
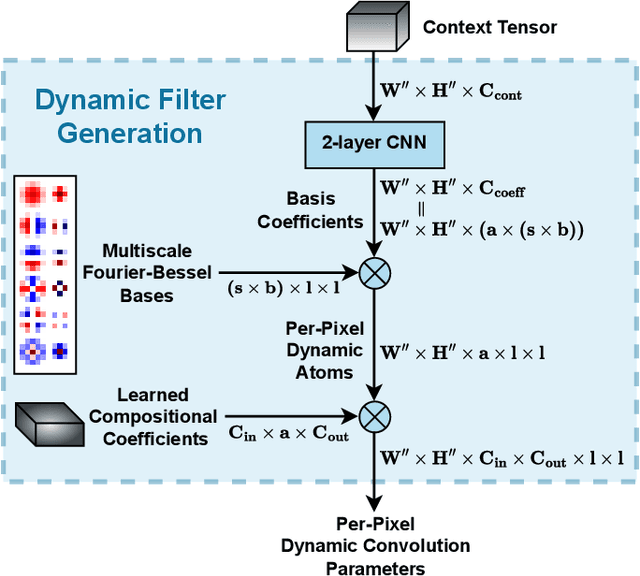
Event-based cameras are becoming increasingly popular for their ability to capture high-speed motion with low latency and high dynamic range. However, generating videos from events remains challenging due to the highly sparse and varying nature of event data. To address this, in this study, we propose HyperE2VID, a dynamic neural network architecture for event-based video reconstruction. Our approach uses hypernetworks and dynamic convolutions to generate per-pixel adaptive filters guided by a context fusion module that combines information from event voxel grids and previously reconstructed intensity images. We also employ a curriculum learning strategy to train the network more robustly. Experimental results demonstrate that HyperE2VID achieves better reconstruction quality with fewer parameters and faster inference time than the state-of-the-art methods.
EVREAL: Towards a Comprehensive Benchmark and Analysis Suite for Event-based Video Reconstruction
Apr 30, 2023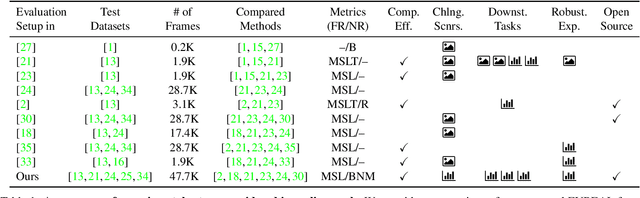
Event cameras are a new type of vision sensor that incorporates asynchronous and independent pixels, offering advantages over traditional frame-based cameras such as high dynamic range and minimal motion blur. However, their output is not easily understandable by humans, making the reconstruction of intensity images from event streams a fundamental task in event-based vision. While recent deep learning-based methods have shown promise in video reconstruction from events, this problem is not completely solved yet. To facilitate comparison between different approaches, standardized evaluation protocols and diverse test datasets are essential. This paper proposes a unified evaluation methodology and introduces an open-source framework called EVREAL to comprehensively benchmark and analyze various event-based video reconstruction methods from the literature. Using EVREAL, we give a detailed analysis of the state-of-the-art methods for event-based video reconstruction, and provide valuable insights into the performance of these methods under varying settings, challenging scenarios, and downstream tasks.