 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBabak Shakibi
Predicting Parameters in Deep Learning
Oct 27, 2014


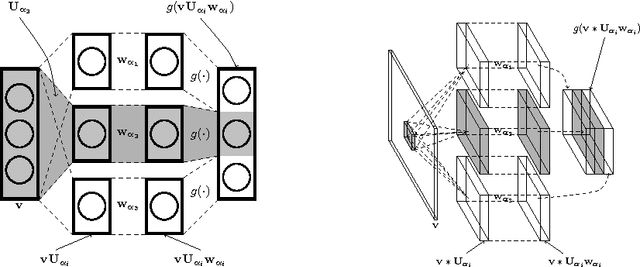
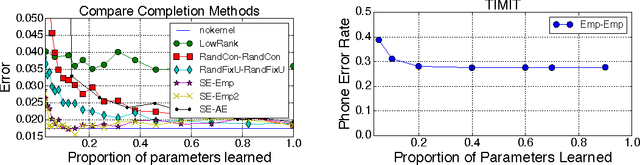
We demonstrate that there is significant redundancy in the parameterization of several deep learning models. Given only a few weight values for each feature it is possible to accurately predict the remaining values. Moreover, we show that not only can the parameter values be predicted, but many of them need not be learned at all. We train several different architectures by learning only a small number of weights and predicting the rest. In the best case we are able to predict more than 95% of the weights of a network without any drop in accuracy.
Bayesian Multi-Scale Optimistic Optimization
Feb 27, 2014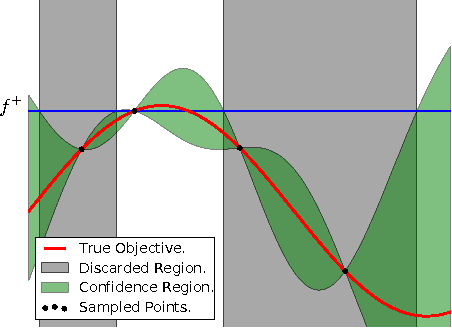


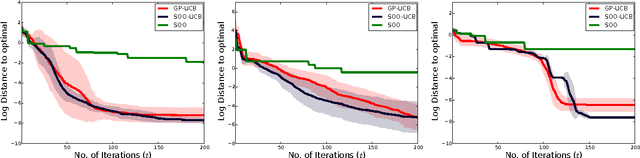
Bayesian optimization is a powerful global optimization technique for expensive black-box functions. One of its shortcomings is that it requires auxiliary optimization of an acquisition function at each iteration. This auxiliary optimization can be costly and very hard to carry out in practice. Moreover, it creates serious theoretical concerns, as most of the convergence results assume that the exact optimum of the acquisition function can be found. In this paper, we introduce a new technique for efficient global optimization that combines Gaussian process confidence bounds and treed simultaneous optimistic optimization to eliminate the need for auxiliary optimization of acquisition functions. The experiments with global optimization benchmarks and a novel application to automatic information extraction demonstrate that the resulting technique is more efficient than the two approaches from which it draws inspiration. Unlike most theoretical analyses of Bayesian optimization with Gaussian processes, our finite-time convergence rate proofs do not require exact optimization of an acquisition function. That is, our approach eliminates the unsatisfactory assumption that a difficult, potentially NP-hard, problem has to be solved in order to obtain vanishing regret rates.