 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBahare Fatemi
Let Your Graph Do the Talking: Encoding Structured Data for LLMs
Feb 08, 2024
How can we best encode structured data into sequential form for use in large language models (LLMs)? In this work, we introduce a parameter-efficient method to explicitly represent structured data for LLMs. Our method, GraphToken, learns an encoding function to extend prompts with explicit structured information. Unlike other work which focuses on limited domains (e.g. knowledge graph representation), our work is the first effort focused on the general encoding of structured data to be used for various reasoning tasks. We show that explicitly representing the graph structure allows significant improvements to graph reasoning tasks. Specifically, we see across the board improvements - up to 73% points - on node, edge and, graph-level tasks from the GraphQA benchmark.
Talk like a Graph: Encoding Graphs for Large Language Models
Oct 06, 2023



Graphs are a powerful tool for representing and analyzing complex relationships in real-world applications such as social networks, recommender systems, and computational finance. Reasoning on graphs is essential for drawing inferences about the relationships between entities in a complex system, and to identify hidden patterns and trends. Despite the remarkable progress in automated reasoning with natural text, reasoning on graphs with large language models (LLMs) remains an understudied problem. In this work, we perform the first comprehensive study of encoding graph-structured data as text for consumption by LLMs. We show that LLM performance on graph reasoning tasks varies on three fundamental levels: (1) the graph encoding method, (2) the nature of the graph task itself, and (3) interestingly, the very structure of the graph considered. These novel results provide valuable insight on strategies for encoding graphs as text. Using these insights we illustrate how the correct choice of encoders can boost performance on graph reasoning tasks inside LLMs by 4.8% to 61.8%, depending on the task.
TpuGraphs: A Performance Prediction Dataset on Large Tensor Computational Graphs
Aug 25, 2023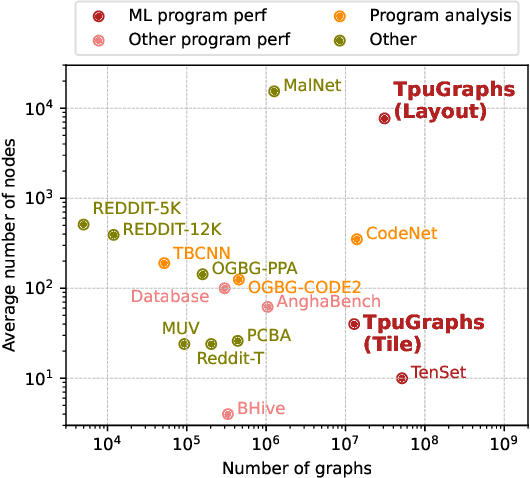

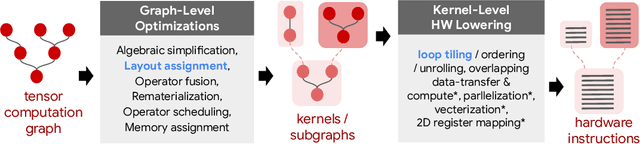
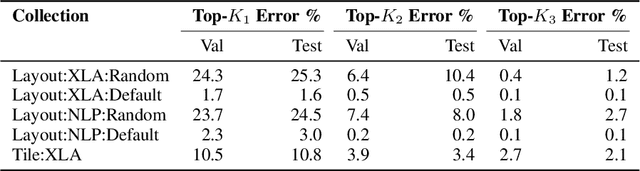
Precise hardware performance models play a crucial role in code optimizations. They can assist compilers in making heuristic decisions or aid autotuners in identifying the optimal configuration for a given program. For example, the autotuner for XLA, a machine learning compiler, discovered 10-20% speedup on state-of-the-art models serving substantial production traffic at Google. Although there exist a few datasets for program performance prediction, they target small sub-programs such as basic blocks or kernels. This paper introduces TpuGraphs, a performance prediction dataset on full tensor programs, represented as computational graphs, running on Tensor Processing Units (TPUs). Each graph in the dataset represents the main computation of a machine learning workload, e.g., a training epoch or an inference step. Each data sample contains a computational graph, a compilation configuration, and the execution time of the graph when compiled with the configuration. The graphs in the dataset are collected from open-source machine learning programs, featuring popular model architectures, e.g., ResNet, EfficientNet, Mask R-CNN, and Transformer. TpuGraphs provides 25x more graphs than the largest graph property prediction dataset (with comparable graph sizes), and 770x larger graphs on average compared to existing performance prediction datasets on machine learning programs. This graph-level prediction task on large graphs introduces new challenges in learning, ranging from scalability, training efficiency, to model quality.
UGSL: A Unified Framework for Benchmarking Graph Structure Learning
Aug 21, 2023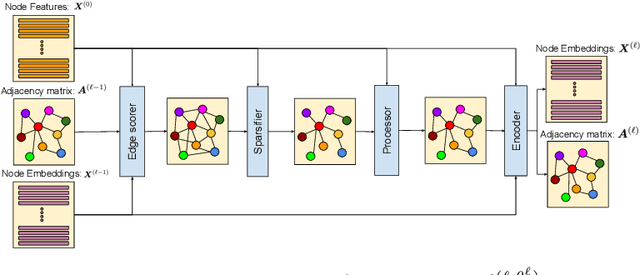

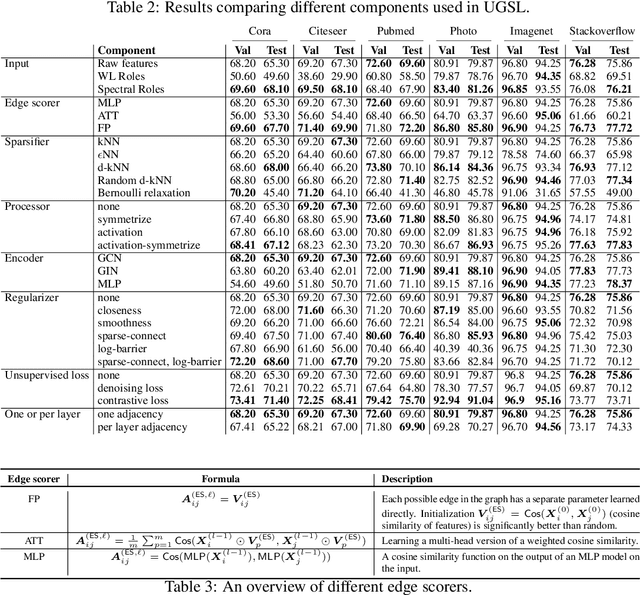
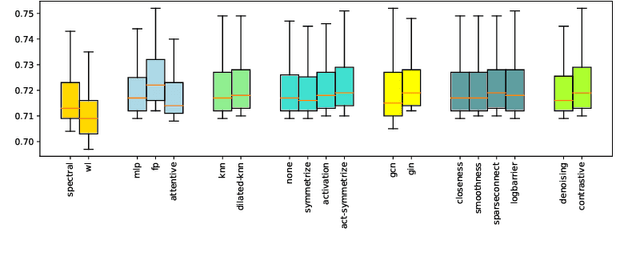
Graph neural networks (GNNs) demonstrate outstanding performance in a broad range of applications. While the majority of GNN applications assume that a graph structure is given, some recent methods substantially expanded the applicability of GNNs by showing that they may be effective even when no graph structure is explicitly provided. The GNN parameters and a graph structure are jointly learned. Previous studies adopt different experimentation setups, making it difficult to compare their merits. In this paper, we propose a benchmarking strategy for graph structure learning using a unified framework. Our framework, called Unified Graph Structure Learning (UGSL), reformulates existing models into a single model. We implement a wide range of existing models in our framework and conduct extensive analyses of the effectiveness of different components in the framework. Our results provide a clear and concise understanding of the different methods in this area as well as their strengths and weaknesses. The benchmark code is available at https://github.com/google-research/google-research/tree/master/ugsl.
Learning to Substitute Ingredients in Recipes
Feb 15, 2023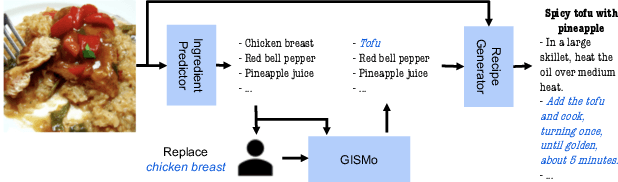
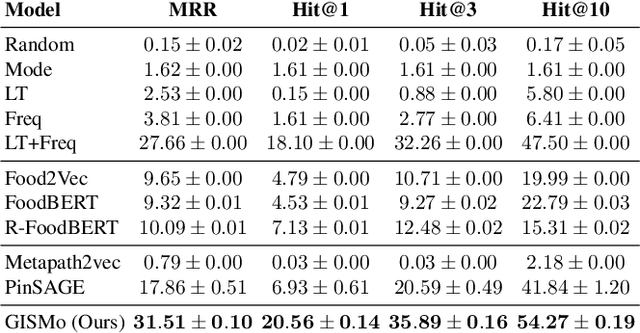
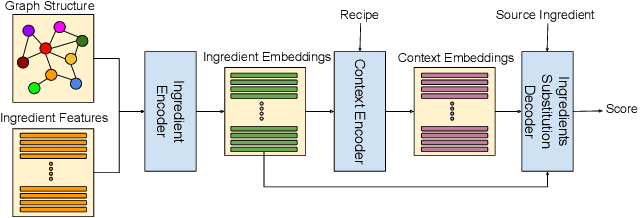
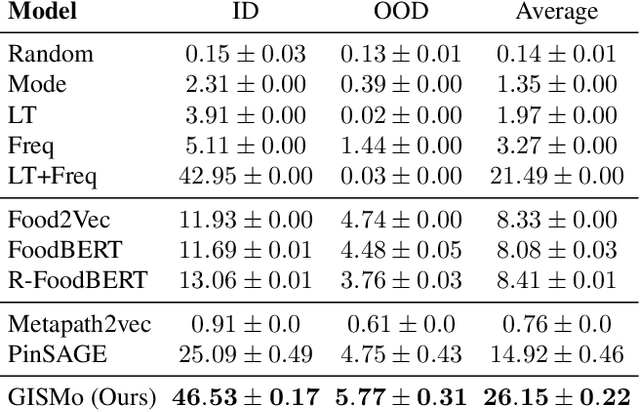
Recipe personalization through ingredient substitution has the potential to help people meet their dietary needs and preferences, avoid potential allergens, and ease culinary exploration in everyone's kitchen. To address ingredient substitution, we build a benchmark, composed of a dataset of substitution pairs with standardized splits, evaluation metrics, and baselines. We further introduce Graph-based Ingredient Substitution Module (GISMo), a novel model that leverages the context of a recipe as well as generic ingredient relational information encoded within a graph to rank plausible substitutions. We show through comprehensive experimental validation that GISMo surpasses the best performing baseline by a large margin in terms of mean reciprocal rank. Finally, we highlight the benefits of GISMo by integrating it in an improved image-to-recipe generation pipeline, enabling recipe personalization through user intervention. Quantitative and qualitative results show the efficacy of our proposed system, paving the road towards truly personalized cooking and tasting experiences.
Using Graph Algorithms to Pretrain Graph Completion Transformers
Oct 14, 2022



Recent work on Graph Neural Networks has demonstrated that self-supervised pretraining can further enhance performance on downstream graph, link, and node classification tasks. However, the efficacy of pretraining tasks has not been fully investigated for downstream large knowledge graph completion tasks. Using a contextualized knowledge graph embedding approach, we investigate five different pretraining signals, constructed using several graph algorithms and no external data, as well as their combination. We leverage the versatility of our Transformer-based model to explore graph structure generation pretraining tasks, typically inapplicable to most graph embedding methods. We further propose a new path-finding algorithm guided by information gain and find that it is the best-performing pretraining task across three downstream knowledge graph completion datasets. In a multitask setting that combines all pretraining tasks, our method surpasses some of the latest and strong performing knowledge graph embedding methods on all metrics for FB15K-237, on MRR and Hit@1 for WN18RR and on MRR and hit@10 for JF17K (a knowledge hypergraph dataset).
Knowledge Hypergraph Embedding Meets Relational Algebra
Feb 18, 2021



Embedding-based methods for reasoning in knowledge hypergraphs learn a representation for each entity and relation. Current methods do not capture the procedural rules underlying the relations in the graph. We propose a simple embedding-based model called ReAlE that performs link prediction in knowledge hypergraphs (generalized knowledge graphs) and can represent high-level abstractions in terms of relational algebra operations. We show theoretically that ReAlE is fully expressive and provide proofs and empirical evidence that it can represent a large subset of the primitive relational algebra operations, namely renaming, projection, set union, selection, and set difference. We also verify experimentally that ReAlE outperforms state-of-the-art models in knowledge hypergraph completion, and in representing each of these primitive relational algebra operations. For the latter experiment, we generate a synthetic knowledge hypergraph, for which we design an algorithm based on the Erdos-R'enyi model for generating random graphs.
SLAPS: Self-Supervision Improves Structure Learning for Graph Neural Networks
Feb 09, 2021



Graph neural networks (GNNs) work well when the graph structure is provided. However, this structure may not always be available in real-world applications. One solution to this problem is to infer a task-specific latent structure and then apply a GNN to the inferred graph. Unfortunately, the space of possible graph structures grows super-exponentially with the number of nodes and so the task-specific supervision may be insufficient for learning both the structure and the GNN parameters. In this work, we propose the Simultaneous Learning of Adjacency and GNN Parameters with Self-supervision, or SLAPS, a method that provides more supervision for inferring a graph structure through self-supervision. A comprehensive experimental study demonstrates that SLAPS scales to large graphs with hundreds of thousands of nodes and outperforms several models that have been proposed to learn a task-specific graph structure on established benchmarks.
Knowledge Hypergraphs: Extending Knowledge Graphs Beyond Binary Relations
Jun 01, 2019



Knowledge graphs store facts using relations between pairs of entities. In this work, we address the question of link prediction in knowledge bases where each relation is defined on any number of entities. We represent facts in a knowledge hypergraph: a knowledge graph where relations are defined on two or more entities. While there exist techniques (such as reification) that convert the non-binary relations of a knowledge hypergraph into binary ones, current embedding-based methods for knowledge graph completion do not work well out of the box for knowledge graphs obtained through these techniques. Thus we introduce HypE, a convolution-based embedding method for knowledge hypergraph completion. We also develop public benchmarks and baselines for our task and show experimentally that HypE is more effective than proposed baselines and existing methods.
Improved Knowledge Graph Embedding using Background Taxonomic Information
Dec 07, 2018



Knowledge graphs are used to represent relational information in terms of triples. To enable learning about domains, embedding models, such as tensor factorization models, can be used to make predictions of new triples. Often there is background taxonomic information (in terms of subclasses and subproperties) that should also be taken into account. We show that existing fully expressive (a.k.a. universal) models cannot provably respect subclass and subproperty information. We show that minimal modifications to an existing knowledge graph completion method enables injection of taxonomic information. Moreover, we prove that our model is fully expressive, assuming a lower-bound on the size of the embeddings. Experimental results on public knowledge graphs show that despite its simplicity our approach is surprisingly effective.