 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBao Duong
Robust Estimation of Causal Heteroscedastic Noise Models
Dec 15, 2023
Distinguishing the cause and effect from bivariate observational data is the foundational problem that finds applications in many scientific disciplines. One solution to this problem is assuming that cause and effect are generated from a structural causal model, enabling identification of the causal direction after estimating the model in each direction. The heteroscedastic noise model is a type of structural causal model where the cause can contribute to both the mean and variance of the noise. Current methods for estimating heteroscedastic noise models choose the Gaussian likelihood as the optimization objective which can be suboptimal and unstable when the data has a non-Gaussian distribution. To address this limitation, we propose a novel approach to estimating this model with Student's $t$-distribution, which is known for its robustness in accounting for sampling variability with smaller sample sizes and extreme values without significantly altering the overall distribution shape. This adaptability is beneficial for capturing the parameters of the noise distribution in heteroscedastic noise models. Our empirical evaluations demonstrate that our estimators are more robust and achieve better overall performance across synthetic and real benchmarks.
Domain Generalisation via Risk Distribution Matching
Oct 28, 2023We propose a novel approach for domain generalisation (DG) leveraging risk distributions to characterise domains, thereby achieving domain invariance. In our findings, risk distributions effectively highlight differences between training domains and reveal their inherent complexities. In testing, we may observe similar, or potentially intensifying in magnitude, divergences between risk distributions. Hence, we propose a compelling proposition: Minimising the divergences between risk distributions across training domains leads to robust invariance for DG. The key rationale behind this concept is that a model, trained on domain-invariant or stable features, may consistently produce similar risk distributions across various domains. Building upon this idea, we propose Risk Distribution Matching (RDM). Using the maximum mean discrepancy (MMD) distance, RDM aims to minimise the variance of risk distributions across training domains. However, when the number of domains increases, the direct optimisation of variance leads to linear growth in MMD computations, resulting in inefficiency. Instead, we propose an approximation that requires only one MMD computation, by aligning just two distributions: that of the worst-case domain and the aggregated distribution from all domains. Notably, this method empirically outperforms optimising distributional variance while being computationally more efficient. Unlike conventional DG matching algorithms, RDM stands out for its enhanced efficacy by concentrating on scalar risk distributions, sidestepping the pitfalls of high-dimensional challenges seen in feature or gradient matching. Our extensive experiments on standard benchmark datasets demonstrate that RDM shows superior generalisation capability over state-of-the-art DG methods.
Differentiable Bayesian Structure Learning with Acyclicity Assurance
Sep 06, 2023Score-based approaches in the structure learning task are thriving because of their scalability. Continuous relaxation has been the key reason for this advancement. Despite achieving promising outcomes, most of these methods are still struggling to ensure that the graphs generated from the latent space are acyclic by minimizing a defined score. There has also been another trend of permutation-based approaches, which concern the search for the topological ordering of the variables in the directed acyclic graph in order to limit the search space of the graph. In this study, we propose an alternative approach for strictly constraining the acyclicty of the graphs with an integration of the knowledge from the topological orderings. Our approach can reduce inference complexity while ensuring the structures of the generated graphs to be acyclic. Our empirical experiments with simulated and real-world data show that our approach can outperform related Bayesian score-based approaches.
Heteroscedastic Causal Structure Learning
Jul 16, 2023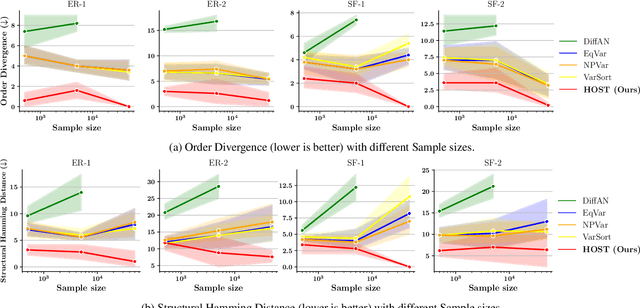
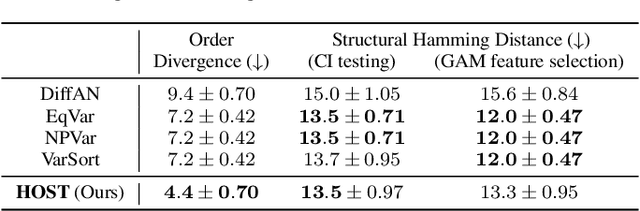
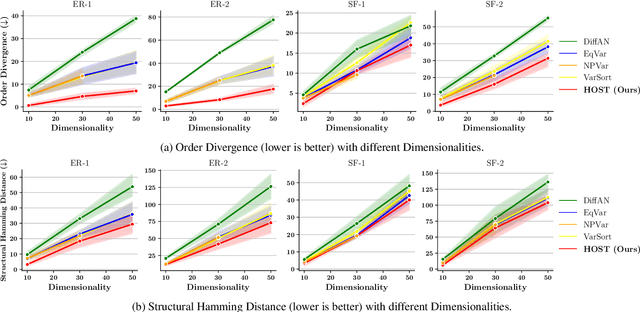
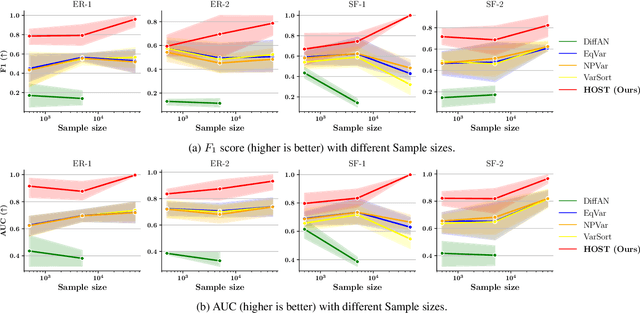
Heretofore, learning the directed acyclic graphs (DAGs) that encode the cause-effect relationships embedded in observational data is a computationally challenging problem. A recent trend of studies has shown that it is possible to recover the DAGs with polynomial time complexity under the equal variances assumption. However, this prohibits the heteroscedasticity of the noise, which allows for more flexible modeling capabilities, but at the same time is substantially more challenging to handle. In this study, we tackle the heteroscedastic causal structure learning problem under Gaussian noises. By exploiting the normality of the causal mechanisms, we can recover a valid causal ordering, which can uniquely identify the causal DAG using a series of conditional independence tests. The result is HOST (Heteroscedastic causal STructure learning), a simple yet effective causal structure learning algorithm that scales polynomially in both sample size and dimensionality. In addition, via extensive empirical evaluations on a wide range of both controlled and real datasets, we show that the proposed HOST method is competitive with state-of-the-art approaches in both the causal order learning and structure learning problems.
Front-door Adjustment via Style Transfer for Out-of-distribution Generalisation
Dec 06, 2022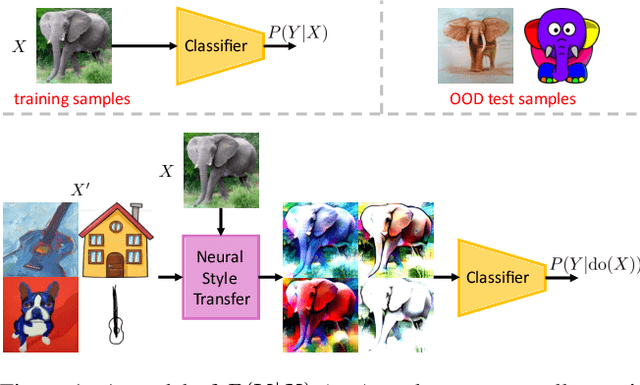
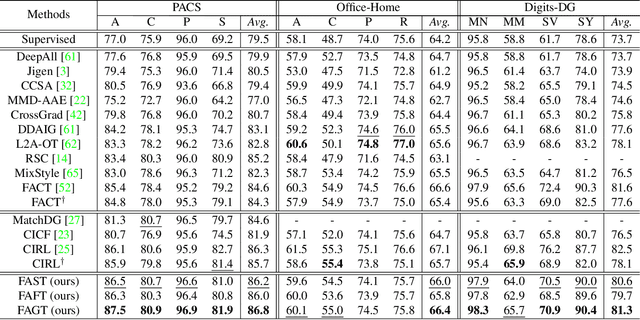
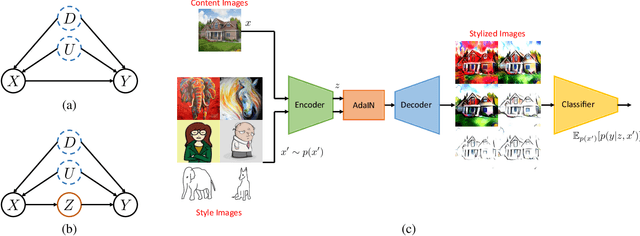
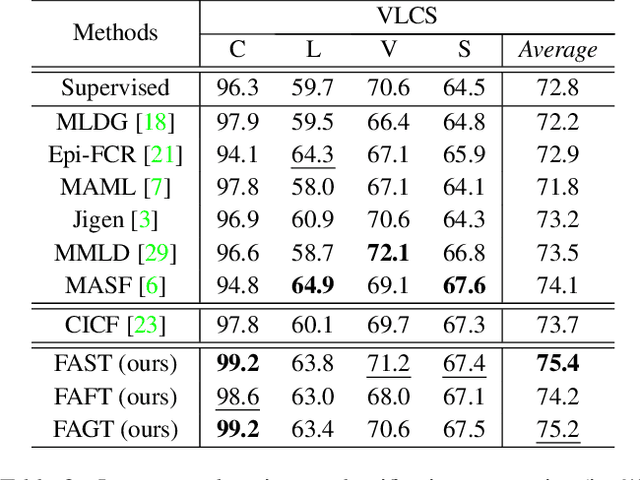
Out-of-distribution (OOD) generalisation aims to build a model that can well generalise its learnt knowledge from source domains to an unseen target domain. However, current image classification models often perform poorly in the OOD setting due to statistically spurious correlations learning from model training. From causality-based perspective, we formulate the data generation process in OOD image classification using a causal graph. On this graph, we show that prediction P(Y|X) of a label Y given an image X in statistical learning is formed by both causal effect P(Y|do(X)) and spurious effects caused by confounding features (e.g., background). Since the spurious features are domain-variant, the prediction P(Y|X) becomes unstable on unseen domains. In this paper, we propose to mitigate the spurious effect of confounders using front-door adjustment. In our method, the mediator variable is hypothesized as semantic features that are essential to determine a label for an image. Inspired by capability of style transfer in image generation, we interpret the combination of the mediator variable with different generated images in the front-door formula and propose novel algorithms to estimate it. Extensive experimental results on widely used benchmark datasets verify the effectiveness of our method.
Diffeomorphic Information Neural Estimation
Nov 20, 2022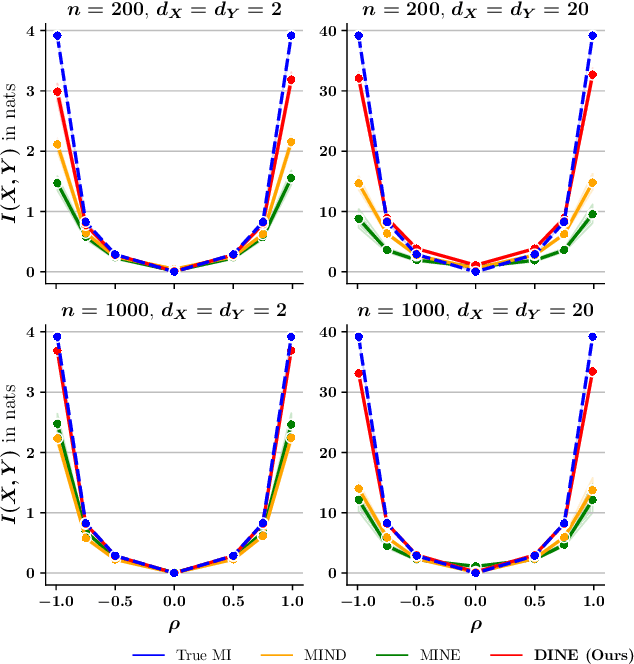
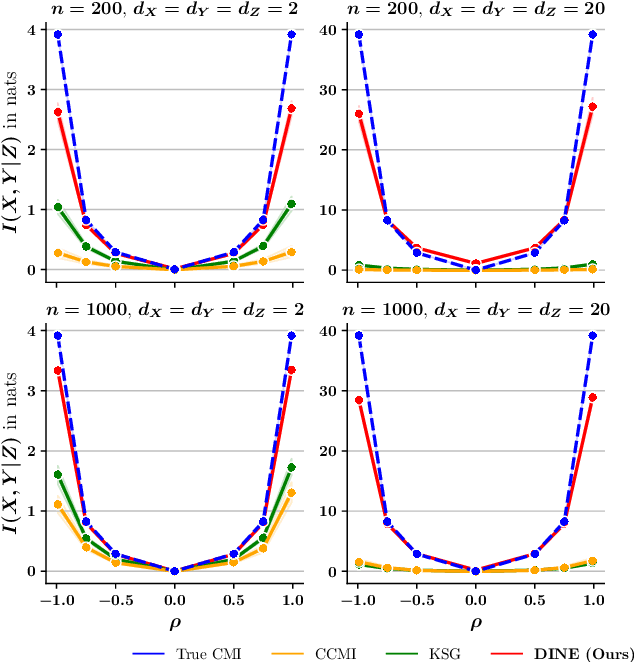
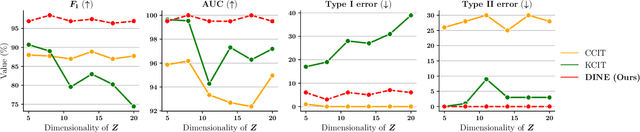
Mutual Information (MI) and Conditional Mutual Information (CMI) are multi-purpose tools from information theory that are able to naturally measure the statistical dependencies between random variables, thus they are usually of central interest in several statistical and machine learning tasks, such as conditional independence testing and representation learning. However, estimating CMI, or even MI, is infamously challenging due the intractable formulation. In this study, we introduce DINE (Diffeomorphic Information Neural Estimator)-a novel approach for estimating CMI of continuous random variables, inspired by the invariance of CMI over diffeomorphic maps. We show that the variables of interest can be replaced with appropriate surrogates that follow simpler distributions, allowing the CMI to be efficiently evaluated via analytical solutions. Additionally, we demonstrate the quality of the proposed estimator in comparison with state-of-the-arts in three important tasks, including estimating MI, CMI, as well as its application in conditional independence testing. The empirical evaluations show that DINE consistently outperforms competitors in all tasks and is able to adapt very well to complex and high-dimensional relationships.
Conditional Independence Testing via Latent Representation Learning
Sep 04, 2022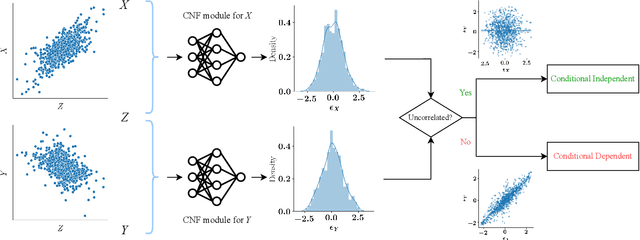
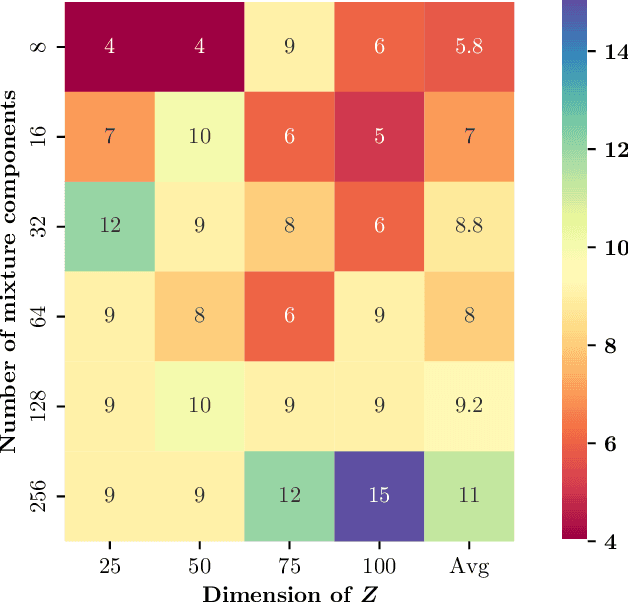
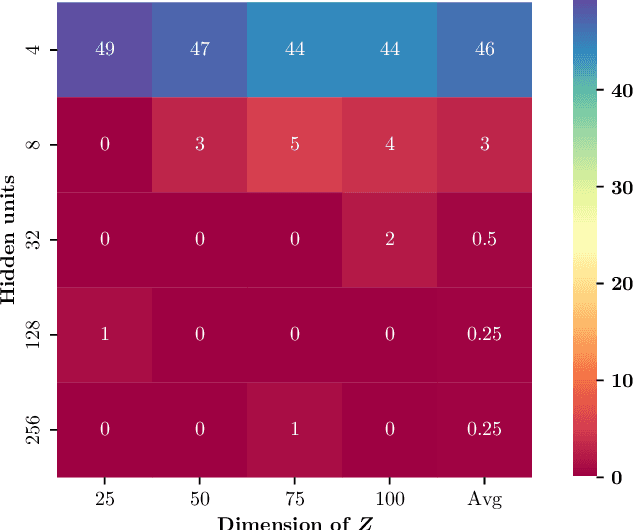
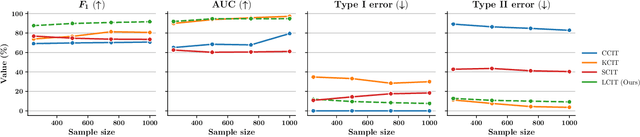
Detecting conditional independencies plays a key role in several statistical and machine learning tasks, especially in causal discovery algorithms. In this study, we introduce LCIT (Latent representation based Conditional Independence Test)-a novel non-parametric method for conditional independence testing based on representation learning. Our main contribution involves proposing a generative framework in which to test for the independence between X and Y given Z, we first learn to infer the latent representations of target variables X and Y that contain no information about the conditioning variable Z. The latent variables are then investigated for any significant remaining dependencies, which can be performed using the conventional partial correlation test. The empirical evaluations show that LCIT outperforms several state-of-the-art baselines consistently under different evaluation metrics, and is able to adapt really well to both non-linear and high-dimensional settings on a diverse collection of synthetic and real data sets.
Efficient Classification with Counterfactual Reasoning and Active Learning
Jul 25, 2022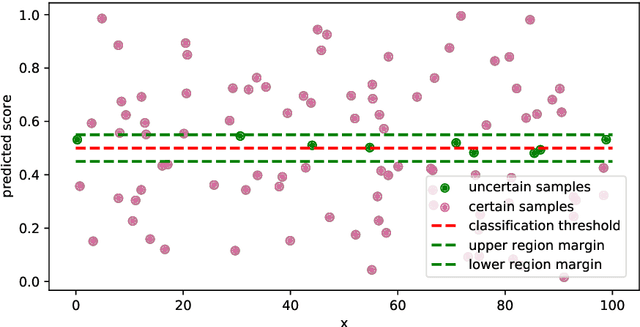
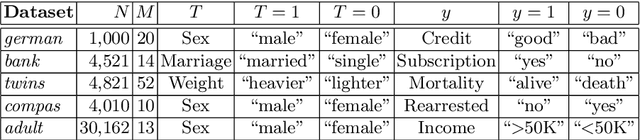
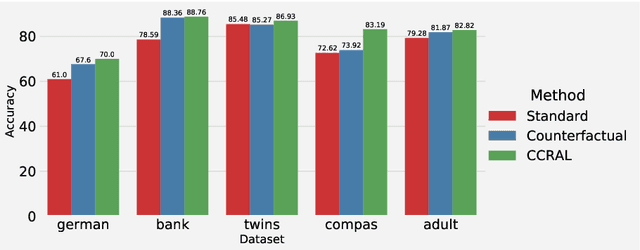
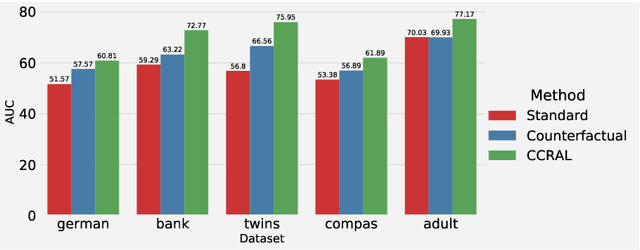
Data augmentation is one of the most successful techniques to improve the classification accuracy of machine learning models in computer vision. However, applying data augmentation to tabular data is a challenging problem since it is hard to generate synthetic samples with labels. In this paper, we propose an efficient classifier with a novel data augmentation technique for tabular data. Our method called CCRAL combines causal reasoning to learn counterfactual samples for the original training samples and active learning to select useful counterfactual samples based on a region of uncertainty. By doing this, our method can maximize our model's generalization on the unseen testing data. We validate our method analytically, and compare with the standard baselines. Our experimental results highlight that CCRAL achieves significantly better performance than those of the baselines across several real-world tabular datasets in terms of accuracy and AUC. Data and source code are available at: https://github.com/nphdang/CCRAL.