 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBen Recht
On the Detection of Mixture Distributions with applications to the Most Biased Coin Problem
Mar 25, 2016

This paper studies the trade-off between two different kinds of pure exploration: breadth versus depth. The most biased coin problem asks how many total coin flips are required to identify a "heavy" coin from an infinite bag containing both "heavy" coins with mean $\theta_1 \in (0,1)$, and "light" coins with mean $\theta_0 \in (0,\theta_1)$, where heavy coins are drawn from the bag with probability $\alpha \in (0,1/2)$. The key difficulty of this problem lies in distinguishing whether the two kinds of coins have very similar means, or whether heavy coins are just extremely rare. This problem has applications in crowdsourcing, anomaly detection, and radio spectrum search. Chandrasekaran et. al. (2014) recently introduced a solution to this problem but it required perfect knowledge of $\theta_0,\theta_1,\alpha$. In contrast, we derive algorithms that are adaptive to partial or absent knowledge of the problem parameters. Moreover, our techniques generalize beyond coins to more general instances of infinitely many armed bandit problems. We also prove lower bounds that show our algorithm's upper bounds are tight up to $\log$ factors, and on the way characterize the sample complexity of differentiating between a single parametric distribution and a mixture of two such distributions. As a result, these bounds have surprising implications both for solutions to the most biased coin problem and for anomaly detection when only partial information about the parameters is known.
Near-Optimal Bounds for Binary Embeddings of Arbitrary Sets
Dec 14, 2015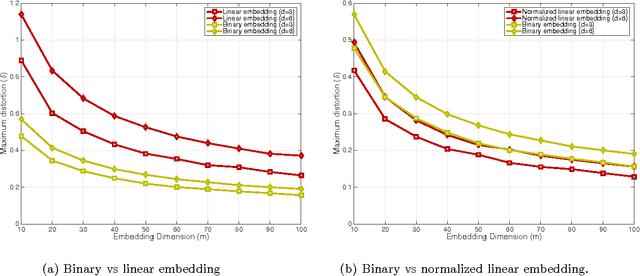
We study embedding a subset $K$ of the unit sphere to the Hamming cube $\{-1,+1\}^m$. We characterize the tradeoff between distortion and sample complexity $m$ in terms of the Gaussian width $\omega(K)$ of the set. For subspaces and several structured sets we show that Gaussian maps provide the optimal tradeoff $m\sim \delta^{-2}\omega^2(K)$, in particular for $\delta$ distortion one needs $m\approx\delta^{-2}{d}$ where $d$ is the subspace dimension. For general sets, we provide sharp characterizations which reduces to $m\approx{\delta^{-4}}{\omega^2(K)}$ after simplification. We provide improved results for local embedding of points that are in close proximity of each other which is related to locality sensitive hashing. We also discuss faster binary embedding where one takes advantage of an initial sketching procedure based on Fast Johnson-Lindenstauss Transform. Finally, we list several numerical observations and discuss open problems.
Fast methods for denoising matrix completion formulations, with applications to robust seismic data interpolation
Mar 05, 2014

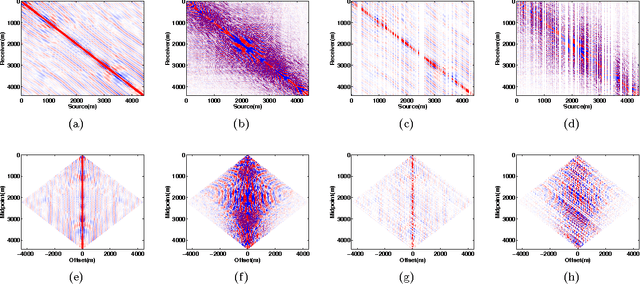
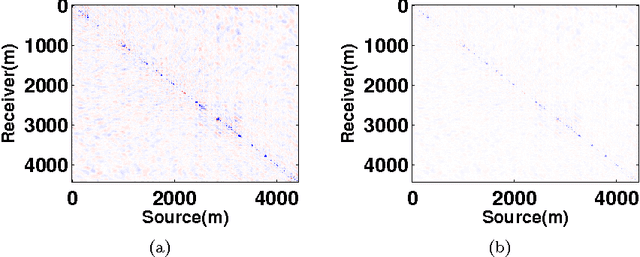
Recent SVD-free matrix factorization formulations have enabled rank minimization for systems with millions of rows and columns, paving the way for matrix completion in extremely large-scale applications, such as seismic data interpolation. In this paper, we consider matrix completion formulations designed to hit a target data-fitting error level provided by the user, and propose an algorithm called LR-BPDN that is able to exploit factorized formulations to solve the corresponding optimization problem. Since practitioners typically have strong prior knowledge about target error level, this innovation makes it easy to apply the algorithm in practice, leaving only the factor rank to be determined. Within the established framework, we propose two extensions that are highly relevant to solving practical challenges of data interpolation. First, we propose a weighted extension that allows known subspace information to improve the results of matrix completion formulations. We show how this weighting can be used in the context of frequency continuation, an essential aspect to seismic data interpolation. Second, we propose matrix completion formulations that are robust to large measurement errors in the available data. We illustrate the advantages of LR-BPDN on the collaborative filtering problem using the MovieLens 1M, 10M, and Netflix 100M datasets. Then, we use the new method, along with its robust and subspace re-weighted extensions, to obtain high-quality reconstructions for large scale seismic interpolation problems with real data, even in the presence of data contamination.