 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBharat Singh
LD-ZNet: A Latent Diffusion Approach for Text-Based Image Segmentation
Mar 22, 2023
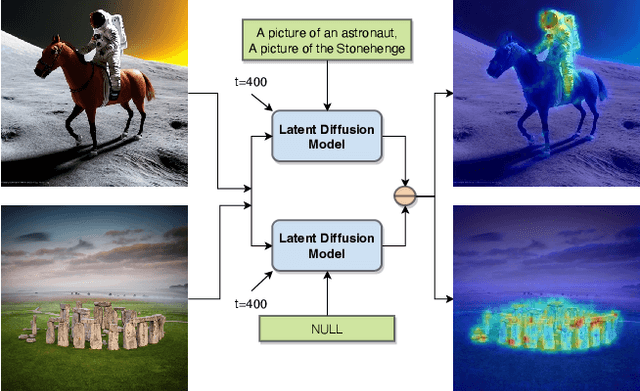
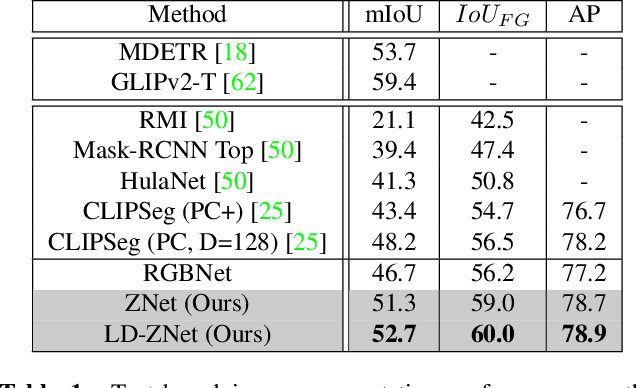
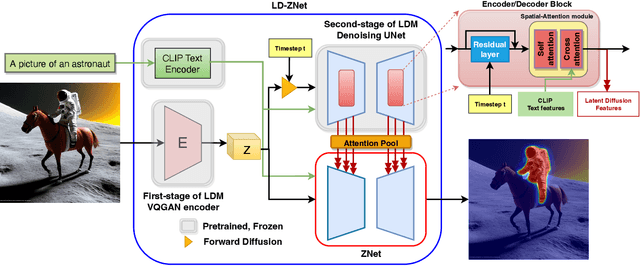
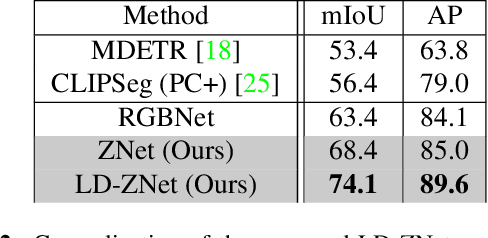
We present a technique for segmenting real and AI-generated images using latent diffusion models (LDMs) trained on internet-scale datasets. First, we show that the latent space of LDMs (z-space) is a better input representation compared to other feature representations like RGB images or CLIP encodings for text-based image segmentation. By training the segmentation models on the latent z-space, which creates a compressed representation across several domains like different forms of art, cartoons, illustrations, and photographs, we are also able to bridge the domain gap between real and AI-generated images. We show that the internal features of LDMs contain rich semantic information and present a technique in the form of LD-ZNet to further boost the performance of text-based segmentation. Overall, we show up to 6% improvement over standard baselines for text-to-image segmentation on natural images. For AI-generated imagery, we show close to 20% improvement compared to state-of-the-art techniques.
Scale Normalized Image Pyramids with AutoFocus for Object Detection
Feb 10, 2021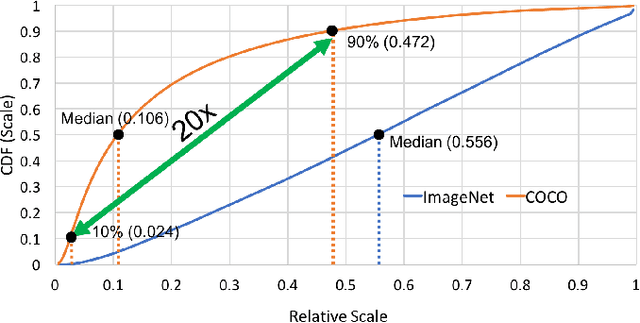

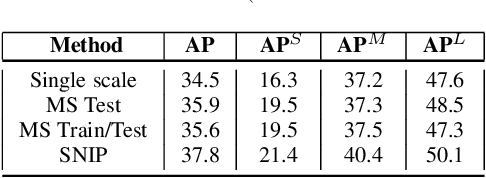
We present an efficient foveal framework to perform object detection. A scale normalized image pyramid (SNIP) is generated that, like human vision, only attends to objects within a fixed size range at different scales. Such a restriction of objects' size during training affords better learning of object-sensitive filters, and therefore, results in better accuracy. However, the use of an image pyramid increases the computational cost. Hence, we propose an efficient spatial sub-sampling scheme which only operates on fixed-size sub-regions likely to contain objects (as object locations are known during training). The resulting approach, referred to as Scale Normalized Image Pyramid with Efficient Resampling or SNIPER, yields up to 3 times speed-up during training. Unfortunately, as object locations are unknown during inference, the entire image pyramid still needs processing. To this end, we adopt a coarse-to-fine approach, and predict the locations and extent of object-like regions which will be processed in successive scales of the image pyramid. Intuitively, it's akin to our active human-vision that first skims over the field-of-view to spot interesting regions for further processing and only recognizes objects at the right resolution. The resulting algorithm is referred to as AutoFocus and results in a 2.5-5 times speed-up during inference when used with SNIP.
ASAP-NMS: Accelerating Non-Maximum Suppression Using Spatially Aware Priors
Aug 21, 2020



The widely adopted sequential variant of Non Maximum Suppression (or Greedy-NMS) is a crucial module for object-detection pipelines. Unfortunately, for the region proposal stage of two/multi-stage detectors, NMS is turning out to be a latency bottleneck due to its sequential nature. In this article, we carefully profile Greedy-NMS iterations to find that a major chunk of computation is wasted in comparing proposals that are already far-away and have a small chance of suppressing each other. We address this issue by comparing only those proposals that are generated from nearby anchors. The translation-invariant property of the anchor lattice affords generation of a lookup table, which provides an efficient access to nearby proposals, during NMS. This leads to an Accelerated NMS algorithm which leverages Spatially Aware Priors, or ASAP-NMS, and improves the latency of the NMS step from 13.6ms to 1.2 ms on a CPU without sacrificing the accuracy of a state-of-the-art two-stage detector on COCO and VOC datasets. Importantly, ASAP-NMS is agnostic to image resolution and can be used as a simple drop-in module during inference. Using ASAP-NMS at run-time only, we obtain an mAP of 44.2\%@25Hz on the COCO dataset with a V100 GPU.
RSO: A Gradient Free Sampling Based Approach For Training Deep Neural Networks
May 12, 2020



We propose RSO (random search optimization), a gradient free Markov Chain Monte Carlo search based approach for training deep neural networks. To this end, RSO adds a perturbation to a weight in a deep neural network and tests if it reduces the loss on a mini-batch. If this reduces the loss, the weight is updated, otherwise the existing weight is retained. Surprisingly, we find that repeating this process a few times for each weight is sufficient to train a deep neural network. The number of weight updates for RSO is an order of magnitude lesser when compared to backpropagation with SGD. RSO can make aggressive weight updates in each step as there is no concept of learning rate. The weight update step for individual layers is also not coupled with the magnitude of the loss. RSO is evaluated on classification tasks on MNIST and CIFAR-10 datasets with deep neural networks of 6 to 10 layers where it achieves an accuracy of 99.1% and 81.8% respectively. We also find that after updating the weights just 5 times, the algorithm obtains a classification accuracy of 98% on MNIST.
Recognizing Instagram Filtered Images with Feature De-stylization
Dec 30, 2019



Deep neural networks have been shown to suffer from poor generalization when small perturbations are added (like Gaussian noise), yet little work has been done to evaluate their robustness to more natural image transformations like photo filters. This paper presents a study on how popular pretrained models are affected by commonly used Instagram filters. To this end, we introduce ImageNet-Instagram, a filtered version of ImageNet, where 20 popular Instagram filters are applied to each image in ImageNet. Our analysis suggests that simple structure preserving filters which only alter the global appearance of an image can lead to large differences in the convolutional feature space. To improve generalization, we introduce a lightweight de-stylization module that predicts parameters used for scaling and shifting feature maps to "undo" the changes incurred by filters, inverting the process of style transfer tasks. We further demonstrate the module can be readily plugged into modern CNN architectures together with skip connections. We conduct extensive studies on ImageNet-Instagram, and show quantitatively and qualitatively, that the proposed module, among other things, can effectively improve generalization by simply learning normalization parameters without retraining the entire network, thus recovering the alterations in the feature space caused by the filters.
Automatic Long-Term Deception Detection in Group Interaction Videos
May 15, 2019



Most work on automated deception detection (ADD) in video has two restrictions: (i) it focuses on a video of one person, and (ii) it focuses on a single act of deception in a one or two minute video. In this paper, we propose a new ADD framework which captures long term deception in a group setting. We study deception in the well-known Resistance game (like Mafia and Werewolf) which consists of 5-8 players of whom 2-3 are spies. Spies are deceptive throughout the game (typically 30-65 minutes) to keep their identity hidden. We develop an ensemble predictive model to identify spies in Resistance videos. We show that features from low-level and high-level video analysis are insufficient, but when combined with a new class of features that we call LiarRank, produce the best results. We achieve AUCs of over 0.70 in a fully automated setting. Our demo can be found at http://home.cs.dartmouth.edu/~mbolonkin/scan/demo/
An Analysis of Pre-Training on Object Detection
Apr 11, 2019



We provide a detailed analysis of convolutional neural networks which are pre-trained on the task of object detection. To this end, we train detectors on large datasets like OpenImagesV4, ImageNet Localization and COCO. We analyze how well their features generalize to tasks like image classification, semantic segmentation and object detection on small datasets like PASCAL-VOC, Caltech-256, SUN-397, Flowers-102 etc. Some important conclusions from our analysis are --- 1) Pre-training on large detection datasets is crucial for fine-tuning on small detection datasets, especially when precise localization is needed. For example, we obtain 81.1% mAP on the PASCAL-VOC dataset at 0.7 IoU after pre-training on OpenImagesV4, which is 7.6% better than the recently proposed DeformableConvNetsV2 which uses ImageNet pre-training. 2) Detection pre-training also benefits other localization tasks like semantic segmentation but adversely affects image classification. 3) Features for images (like avg. pooled Conv5) which are similar in the object detection feature space are likely to be similar in the image classification feature space but the converse is not true. 4) Visualization of features reveals that detection neurons have activations over an entire object, while activations for classification networks typically focus on parts. Therefore, detection networks are poor at classification when multiple instances are present in an image or when an instance only covers a small fraction of an image.
TAN: Temporal Aggregation Network for Dense Multi-label Action Recognition
Dec 14, 2018


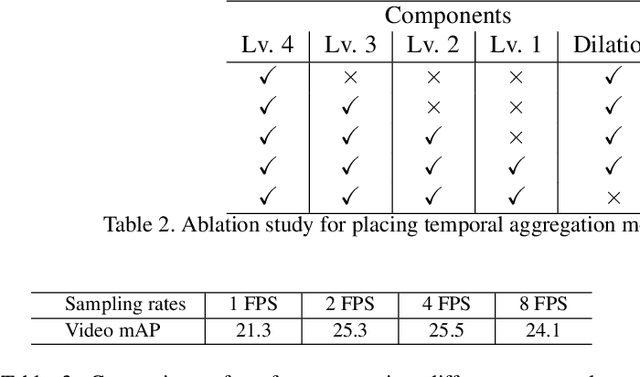
We present Temporal Aggregation Network (TAN) which decomposes 3D convolutions into spatial and temporal aggregation blocks. By stacking spatial and temporal convolutions repeatedly, TAN forms a deep hierarchical representation for capturing spatio-temporal information in videos. Since we do not apply 3D convolutions in each layer but only apply temporal aggregation blocks once after each spatial downsampling layer in the network, we significantly reduce the model complexity. The use of dilated convolutions at different resolutions of the network helps in aggregating multi-scale spatio-temporal information efficiently. Experiments show that our model is well suited for dense multi-label action recognition, which is a challenging sub-topic of action recognition that requires predicting multiple action labels in each frame. We outperform state-of-the-art methods by 5% and 3% on the Charades and Multi-THUMOS dataset respectively.
FA-RPN: Floating Region Proposals for Face Detection
Dec 13, 2018



We propose a novel approach for generating region proposals for performing face-detection. Instead of classifying anchor boxes using features from a pixel in the convolutional feature map, we adopt a pooling-based approach for generating region proposals. However, pooling hundreds of thousands of anchors which are evaluated for generating proposals becomes a computational bottleneck during inference. To this end, an efficient anchor placement strategy for reducing the number of anchor-boxes is proposed. We then show that proposals generated by our network (Floating Anchor Region Proposal Network, FA-RPN) are better than RPN for generating region proposals for face detection. We discuss several beneficial features of FA-RPN proposals like iterative refinement, placement of fractional anchors and changing anchors which can be enabled without making any changes to the trained model. Our face detector based on FA-RPN obtains 89.4% mAP with a ResNet-50 backbone on the WIDER dataset.
AutoFocus: Efficient Multi-Scale Inference
Dec 04, 2018



This paper describes AutoFocus, an efficient multi-scale inference algorithm for deep-learning based object detectors. Instead of processing an entire image pyramid, AutoFocus adopts a coarse to fine approach and only processes regions which are likely to contain small objects at finer scales. This is achieved by predicting category agnostic segmentation maps for small objects at coarser scales, called FocusPixels. FocusPixels can be predicted with high recall, and in many cases, they only cover a small fraction of the entire image. To make efficient use of FocusPixels, an algorithm is proposed which generates compact rectangular FocusChips which enclose FocusPixels. The detector is only applied inside FocusChips, which reduces computation while processing finer scales. Different types of error can arise when detections from FocusChips of multiple scales are combined, hence techniques to correct them are proposed. AutoFocus obtains an mAP of 47.9% (68.3% at 50% overlap) on the COCO test-dev set while processing 6.4 images per second on a Titan X (Pascal) GPU. This is 2.5X faster than our multi-scale baseline detector and matches its mAP. The number of pixels processed in the pyramid can be reduced by 5X with a 1% drop in mAP. AutoFocus obtains more than 10% mAP gain compared to RetinaNet but runs at the same speed with the same ResNet-101 backbone.