 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBianca Lamm
Are Vision Language Models Texture or Shape Biased and Can We Steer Them?
Mar 14, 2024
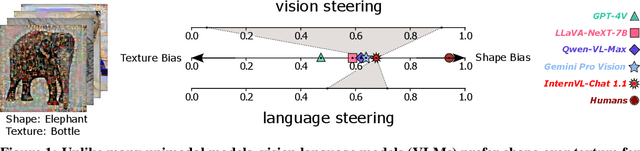
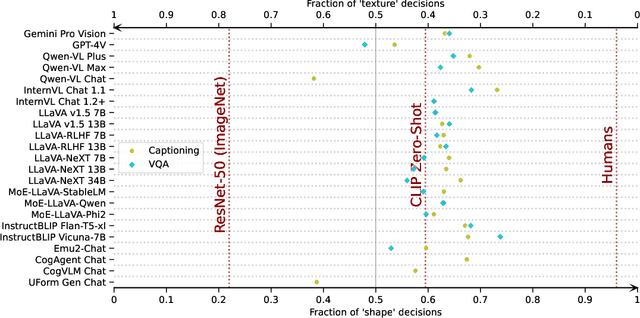
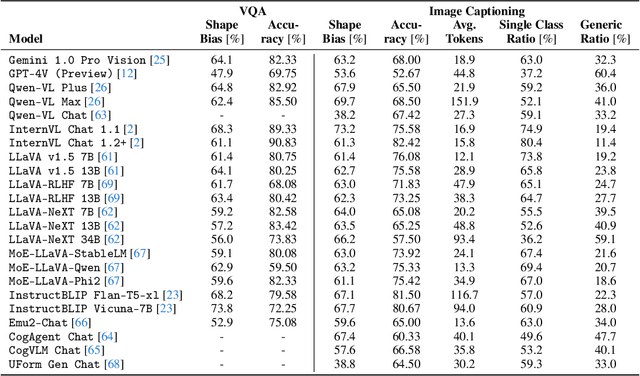
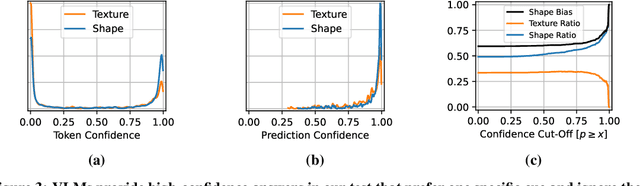
Vision language models (VLMs) have drastically changed the computer vision model landscape in only a few years, opening an exciting array of new applications from zero-shot image classification, over to image captioning, and visual question answering. Unlike pure vision models, they offer an intuitive way to access visual content through language prompting. The wide applicability of such models encourages us to ask whether they also align with human vision - specifically, how far they adopt human-induced visual biases through multimodal fusion, or whether they simply inherit biases from pure vision models. One important visual bias is the texture vs. shape bias, or the dominance of local over global information. In this paper, we study this bias in a wide range of popular VLMs. Interestingly, we find that VLMs are often more shape-biased than their vision encoders, indicating that visual biases are modulated to some extent through text in multimodal models. If text does indeed influence visual biases, this suggests that we may be able to steer visual biases not just through visual input but also through language: a hypothesis that we confirm through extensive experiments. For instance, we are able to steer shape bias from as low as 49% to as high as 72% through prompting alone. For now, the strong human bias towards shape (96%) remains out of reach for all tested VLMs.
Retail-786k: a Large-Scale Dataset for Visual Entity Matching
Sep 29, 2023



Entity Matching (EM) defines the task of learning to group objects by transferring semantic concepts from example groups (=entities) to unseen data. Despite the general availability of image data in the context of many EM-problems, most currently available EM-algorithms solely rely on (textual) meta data. In this paper, we introduce the first publicly available large-scale dataset for "visual entity matching", based on a production level use case in the retail domain. Using scanned advertisement leaflets, collected over several years from different European retailers, we provide a total of ~786k manually annotated, high resolution product images containing ~18k different individual retail products which are grouped into ~3k entities. The annotation of these product entities is based on a price comparison task, where each entity forms an equivalence class of comparable products. Following on a first baseline evaluation, we show that the proposed "visual entity matching" constitutes a novel learning problem which can not sufficiently be solved using standard image based classification and retrieval algorithms. Instead, novel approaches which allow to transfer example based visual equivalent classes to new data are needed to address the proposed problem. The aim of this paper is to provide a benchmark for such algorithms. Information about the dataset, evaluation code and download instructions are provided under https://www.retail-786k.org/.
Fine-Grained Product Classification on Leaflet Advertisements
May 05, 2023



In this paper, we describe a first publicly available fine-grained product recognition dataset based on leaflet images. Using advertisement leaflets, collected over several years from different European retailers, we provide a total of 41.6k manually annotated product images in 832 classes. Further, we investigate three different approaches for this fine-grained product classification task, Classification by Image, by Text, as well as by Image and Text. The approach "Classification by Text" uses the text extracted directly from the leaflet product images. We show, that the combination of image and text as input improves the classification of visual difficult to distinguish products. The final model leads to an accuracy of 96.4% with a Top-3 score of 99.2%. We release our code at https://github.com/ladwigd/Leaflet-Product-Classification.