 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBin Qin
PRGC: Potential Relation and Global Correspondence Based Joint Relational Triple Extraction
Jun 18, 2021
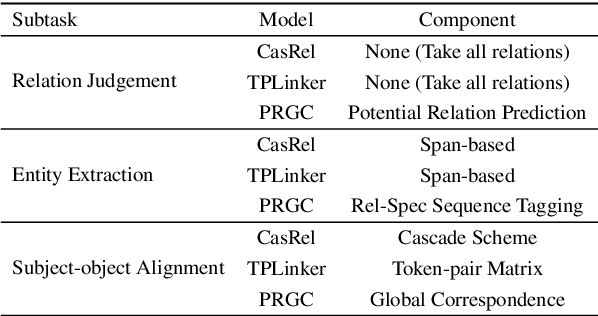
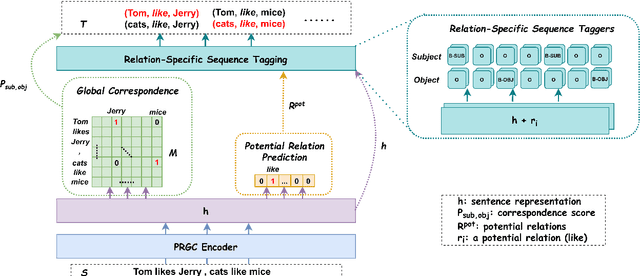
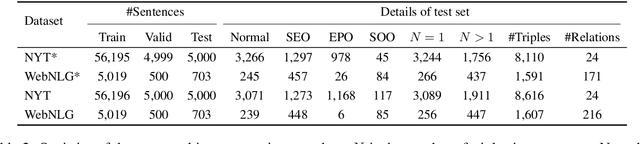
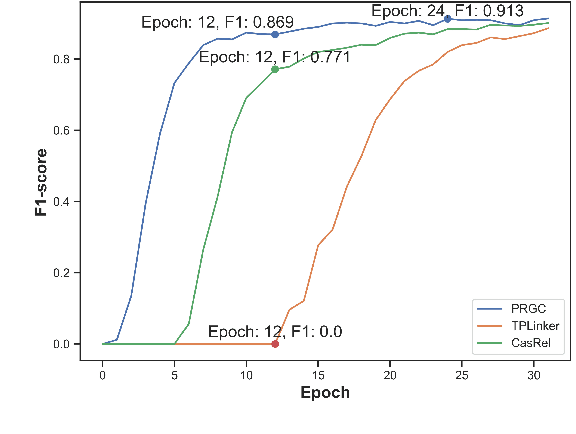
Joint extraction of entities and relations from unstructured texts is a crucial task in information extraction. Recent methods achieve considerable performance but still suffer from some inherent limitations, such as redundancy of relation prediction, poor generalization of span-based extraction and inefficiency. In this paper, we decompose this task into three subtasks, Relation Judgement, Entity Extraction and Subject-object Alignment from a novel perspective and then propose a joint relational triple extraction framework based on Potential Relation and Global Correspondence (PRGC). Specifically, we design a component to predict potential relations, which constrains the following entity extraction to the predicted relation subset rather than all relations; then a relation-specific sequence tagging component is applied to handle the overlapping problem between subjects and objects; finally, a global correspondence component is designed to align the subject and object into a triple with low-complexity. Extensive experiments show that PRGC achieves state-of-the-art performance on public benchmarks with higher efficiency and delivers consistent performance gain on complex scenarios of overlapping triples.
Partial FC: Training 10 Million Identities on a Single Machine
Oct 11, 2020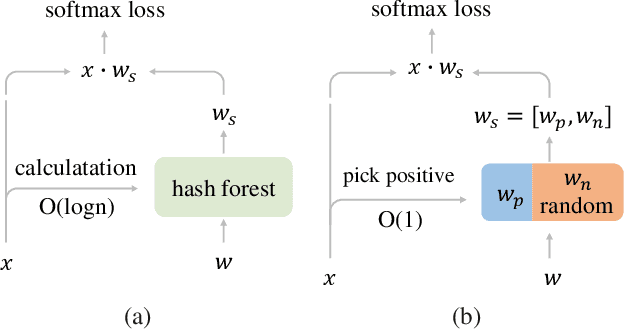
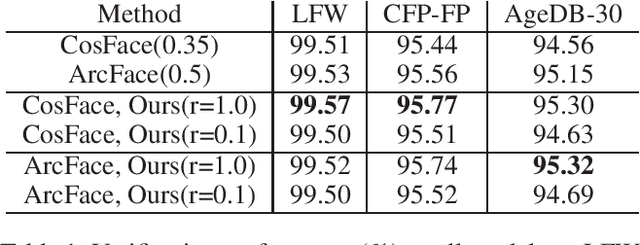
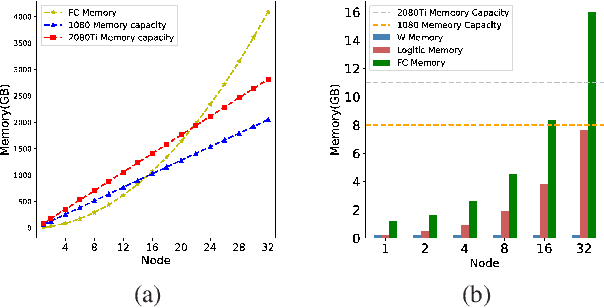
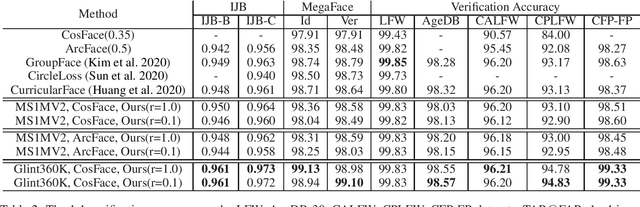
Face recognition has been an active and vital topic among computer vision community for a long time. Previous researches mainly focus on loss functions used for facial feature extraction network, among which the improvements of softmax-based loss functions greatly promote the performance of face recognition. However, the contradiction between the drastically increasing number of face identities and the shortage of GPU memories is gradually becoming irreconcilable. In this paper, we thoroughly analyze the optimization goal of softmax-based loss functions and the difficulty of training massive identities. We find that the importance of negative classes in softmax function in face representation learning is not as high as we previously thought. The experiment demonstrates no loss of accuracy when training with only 10\% randomly sampled classes for the softmax-based loss functions, compared with training with full classes using state-of-the-art models on mainstream benchmarks. We also implement a very efficient distributed sampling algorithm, taking into account model accuracy and training efficiency, which uses only eight NVIDIA RTX2080Ti to complete classification tasks with tens of millions of identities. The code of this paper has been made available https://github.com/deepinsight/insightface/tree/master/recognition/partial_fc.
Multi-view Clustering with the Cooperation of Visible and Hidden Views
Aug 12, 2019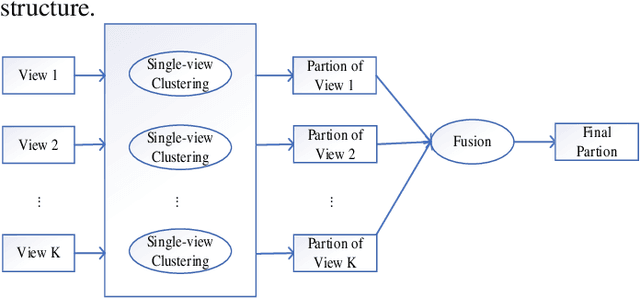
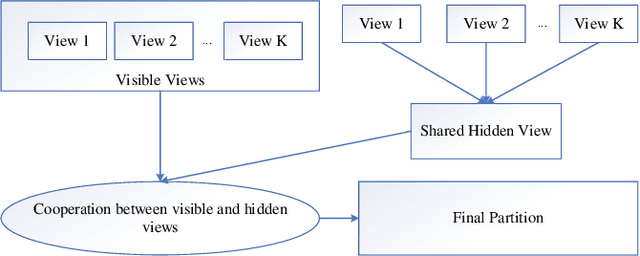
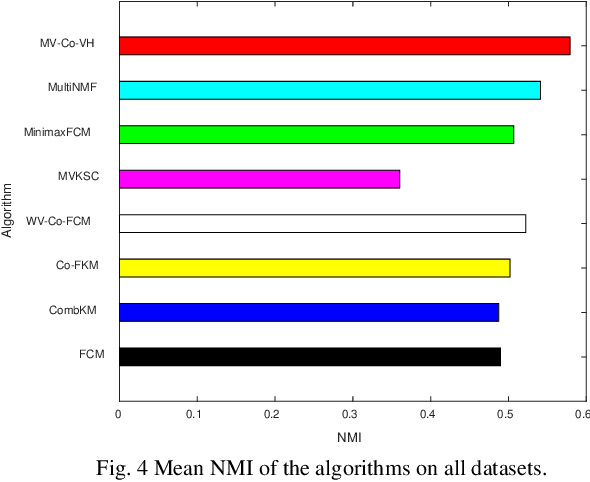
Multi-view data are becoming common in real-world modeling tasks and many multi-view data clustering algorithms have thus been proposed. The existing algorithms usually focus on the cooperation of different views in the original space but neglect the influence of the hidden information among these different visible views, or they only consider the hidden information between the views. The algorithms are therefore not efficient since the available information is not fully excavated, particularly the otherness information in different views and the consistency information between them. In practice, the otherness and consistency information in multi-view data are both very useful for effective clustering analyses. In this study, a Multi-View clustering algorithm developed with the Cooperation of Visible and Hidden views, i.e., MV-Co-VH, is proposed. The MV-Co-VH algorithm first projects the multiple views from different visible spaces to the common hidden space by using the non-negative matrix factorization (NMF) strategy to obtain the common hidden view data. Collaborative learning is then implemented in the clustering procedure based on the visible views and the shared hidden view. The results of extensive experiments on UCI multi-view datasets and real-world image multi-view datasets show that the clustering performance of the proposed algorithm is competitive with or even better than that of the existing algorithms.