 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBodo Rosenhahn
SplatPose & Detect: Pose-Agnostic 3D Anomaly Detection
Apr 10, 2024
Detecting anomalies in images has become a well-explored problem in both academia and industry. State-of-the-art algorithms are able to detect defects in increasingly difficult settings and data modalities. However, most current methods are not suited to address 3D objects captured from differing poses. While solutions using Neural Radiance Fields (NeRFs) have been proposed, they suffer from excessive computation requirements, which hinder real-world usability. For this reason, we propose the novel 3D Gaussian splatting-based framework SplatPose which, given multi-view images of a 3D object, accurately estimates the pose of unseen views in a differentiable manner, and detects anomalies in them. We achieve state-of-the-art results in both training and inference speed, and detection performance, even when using less training data than competing methods. We thoroughly evaluate our framework using the recently proposed Pose-agnostic Anomaly Detection benchmark and its multi-pose anomaly detection (MAD) data set.
Cell Tracking according to Biological Needs -- Strong Mitosis-aware Random-finite Sets Tracker with Aleatoric Uncertainty
Mar 25, 2024Cell tracking and segmentation assist biologists in extracting insights from large-scale microscopy time-lapse data. Driven by local accuracy metrics, current tracking approaches often suffer from a lack of long-term consistency. To address this issue, we introduce an uncertainty estimation technique for neural tracking-by-regression frameworks and incorporate it into our novel extended Poisson multi-Bernoulli mixture tracker. Our uncertainty estimation identifies uncertain associations within high-performing tracking-by-regression methods using problem-specific test-time augmentations. Leveraging this uncertainty, along with a novel mitosis-aware assignment problem formulation, our tracker resolves false associations and mitosis detections stemming from long-term conflicts. We evaluate our approach on nine competitive datasets and demonstrate that it outperforms the current state-of-the-art on biologically relevant metrics substantially, achieving improvements by a factor of approximately $5.75$. Furthermore, we uncover new insights into the behavior of tracking-by-regression uncertainty.
Personalized 3D Human Pose and Shape Refinement
Mar 18, 2024



Recently, regression-based methods have dominated the field of 3D human pose and shape estimation. Despite their promising results, a common issue is the misalignment between predictions and image observations, often caused by minor joint rotation errors that accumulate along the kinematic chain. To address this issue, we propose to construct dense correspondences between initial human model estimates and the corresponding images that can be used to refine the initial predictions. To this end, we utilize renderings of the 3D models to predict per-pixel 2D displacements between the synthetic renderings and the RGB images. This allows us to effectively integrate and exploit appearance information of the persons. Our per-pixel displacements can be efficiently transformed to per-visible-vertex displacements and then used for 3D model refinement by minimizing a reprojection loss. To demonstrate the effectiveness of our approach, we refine the initial 3D human mesh predictions of multiple models using different refinement procedures on 3DPW and RICH. We show that our approach not only consistently leads to better image-model alignment, but also to improved 3D accuracy.
* Accepted to 2023 IEEE/CVF International Conference on Computer Vision Workshops (ICCVW)
Segment Any Object Model (SAOM): Real-to-Simulation Fine-Tuning Strategy for Multi-Class Multi-Instance Segmentation
Mar 16, 2024

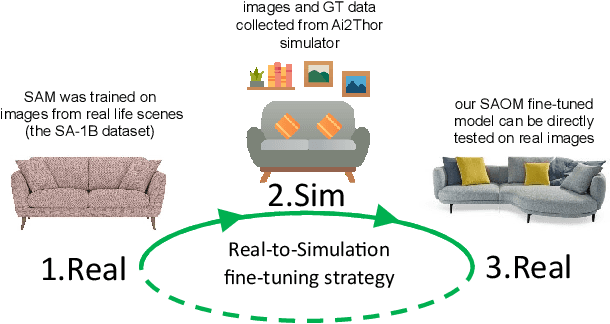
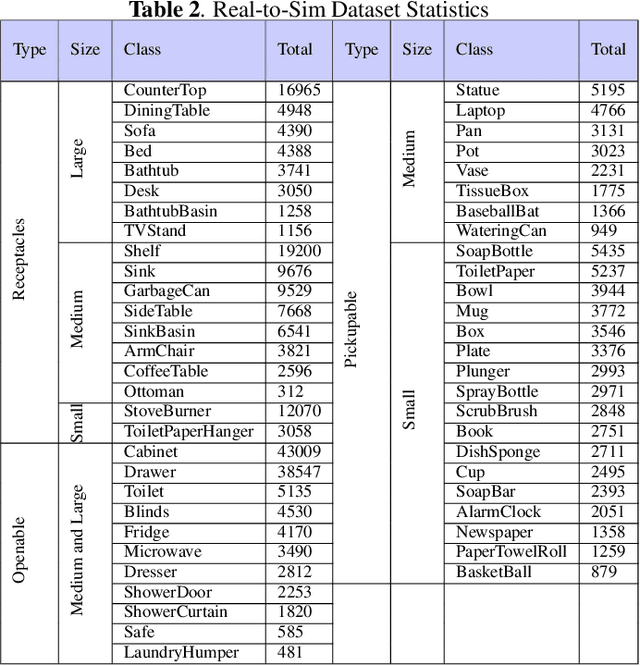
Multi-class multi-instance segmentation is the task of identifying masks for multiple object classes and multiple instances of the same class within an image. The foundational Segment Anything Model (SAM) is designed for promptable multi-class multi-instance segmentation but tends to output part or sub-part masks in the "everything" mode for various real-world applications. Whole object segmentation masks play a crucial role for indoor scene understanding, especially in robotics applications. We propose a new domain invariant Real-to-Simulation (Real-Sim) fine-tuning strategy for SAM. We use object images and ground truth data collected from Ai2Thor simulator during fine-tuning (real-to-sim). To allow our Segment Any Object Model (SAOM) to work in the "everything" mode, we propose the novel nearest neighbour assignment method, updating point embeddings for each ground-truth mask. SAOM is evaluated on our own dataset collected from Ai2Thor simulator. SAOM significantly improves on SAM, with a 28% increase in mIoU and a 25% increase in mAcc for 54 frequently-seen indoor object classes. Moreover, our Real-to-Simulation fine-tuning strategy demonstrates promising generalization performance in real environments without being trained on the real-world data (sim-to-real). The dataset and the code will be released after publication.
Robust Shape Fitting for 3D Scene Abstraction
Mar 15, 2024
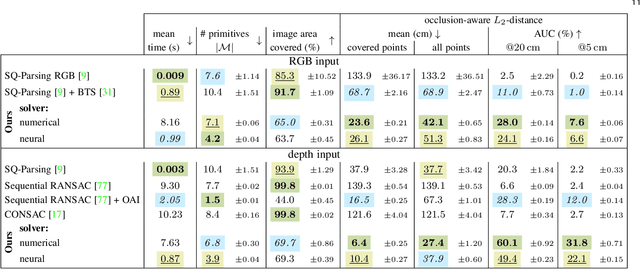
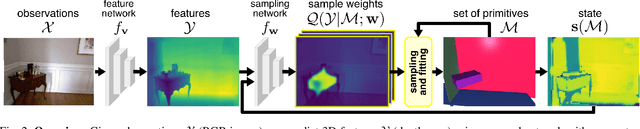

Humans perceive and construct the world as an arrangement of simple parametric models. In particular, we can often describe man-made environments using volumetric primitives such as cuboids or cylinders. Inferring these primitives is important for attaining high-level, abstract scene descriptions. Previous approaches for primitive-based abstraction estimate shape parameters directly and are only able to reproduce simple objects. In contrast, we propose a robust estimator for primitive fitting, which meaningfully abstracts complex real-world environments using cuboids. A RANSAC estimator guided by a neural network fits these primitives to a depth map. We condition the network on previously detected parts of the scene, parsing it one-by-one. To obtain cuboids from single RGB images, we additionally optimise a depth estimation CNN end-to-end. Naively minimising point-to-primitive distances leads to large or spurious cuboids occluding parts of the scene. We thus propose an improved occlusion-aware distance metric correctly handling opaque scenes. Furthermore, we present a neural network based cuboid solver which provides more parsimonious scene abstractions while also reducing inference time. The proposed algorithm does not require labour-intensive labels, such as cuboid annotations, for training. Results on the NYU Depth v2 dataset demonstrate that the proposed algorithm successfully abstracts cluttered real-world 3D scene layouts.
Mastering Zero-Shot Interactions in Cooperative and Competitive Simultaneous Games
Feb 05, 2024The combination of self-play and planning has achieved great successes in sequential games, for instance in Chess and Go. However, adapting algorithms such as AlphaZero to simultaneous games poses a new challenge. In these games, missing information about concurrent actions of other agents is a limiting factor as they may select different Nash equilibria or do not play optimally at all. Thus, it is vital to model the behavior of the other agents when interacting with them in simultaneous games. To this end, we propose Albatross: AlphaZero for Learning Bounded-rational Agents and Temperature-based Response Optimization using Simulated Self-play. Albatross learns to play the novel equilibrium concept of a Smooth Best Response Logit Equilibrium (SBRLE), which enables cooperation and competition with agents of any playing strength. We perform an extensive evaluation of Albatross on a set of cooperative and competitive simultaneous perfect-information games. In contrast to AlphaZero, Albatross is able to exploit weak agents in the competitive game of Battlesnake. Additionally, it yields an improvement of 37.6% compared to previous state of the art in the cooperative Overcooked benchmark.
Quantum Normalizing Flows for Anomaly Detection
Feb 05, 2024A Normalizing Flow computes a bijective mapping from an arbitrary distribution to a predefined (e.g. normal) distribution. Such a flow can be used to address different tasks, e.g. anomaly detection, once such a mapping has been learned. In this work we introduce Normalizing Flows for Quantum architectures, describe how to model and optimize such a flow and evaluate our method on example datasets. Our proposed models show competitive performance for anomaly detection compared to classical methods, e.g. based on isolation forests, the local outlier factor (LOF) or single-class SVMs, while being fully executable on a quantum computer.
PARSAC: Accelerating Robust Multi-Model Fitting with Parallel Sample Consensus
Jan 26, 2024We present a real-time method for robust estimation of multiple instances of geometric models from noisy data. Geometric models such as vanishing points, planar homographies or fundamental matrices are essential for 3D scene analysis. Previous approaches discover distinct model instances in an iterative manner, thus limiting their potential for speedup via parallel computation. In contrast, our method detects all model instances independently and in parallel. A neural network segments the input data into clusters representing potential model instances by predicting multiple sets of sample and inlier weights. Using the predicted weights, we determine the model parameters for each potential instance separately in a RANSAC-like fashion. We train the neural network via task-specific loss functions, i.e. we do not require a ground-truth segmentation of the input data. As suitable training data for homography and fundamental matrix fitting is scarce, we additionally present two new synthetic datasets. We demonstrate state-of-the-art performance on these as well as multiple established datasets, with inference times as small as five milliseconds per image.
Q-SENN: Quantized Self-Explaining Neural Networks
Dec 21, 2023Explanations in Computer Vision are often desired, but most Deep Neural Networks can only provide saliency maps with questionable faithfulness. Self-Explaining Neural Networks (SENN) extract interpretable concepts with fidelity, diversity, and grounding to combine them linearly for decision-making. While they can explain what was recognized, initial realizations lack accuracy and general applicability. We propose the Quantized-Self-Explaining Neural Network Q-SENN. Q-SENN satisfies or exceeds the desiderata of SENN while being applicable to more complex datasets and maintaining most or all of the accuracy of an uninterpretable baseline model, out-performing previous work in all considered metrics. Q-SENN describes the relationship between every class and feature as either positive, negative or neutral instead of an arbitrary number of possible relations, enforcing more binary human-friendly features. Since every class is assigned just 5 interpretable features on average, Q-SENN shows convincing local and global interpretability. Additionally, we propose a feature alignment method, capable of aligning learned features with human language-based concepts without additional supervision. Thus, what is learned can be more easily verbalized. The code is published: https://github.com/ThomasNorr/Q-SENN
The voraus-AD Dataset for Anomaly Detection in Robot Applications
Nov 08, 2023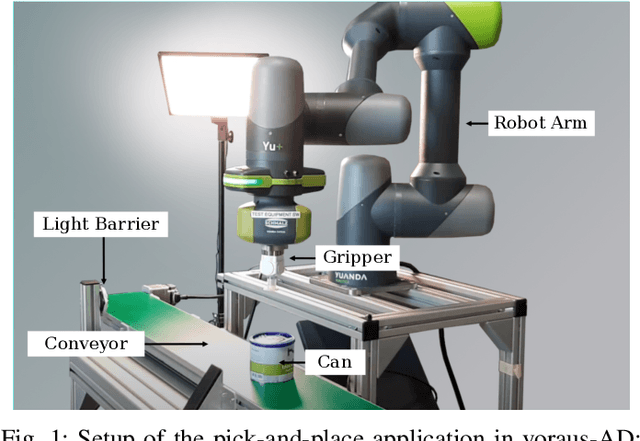
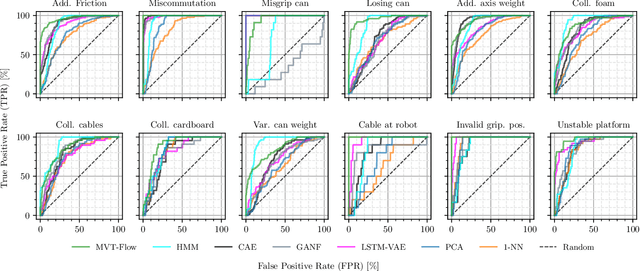
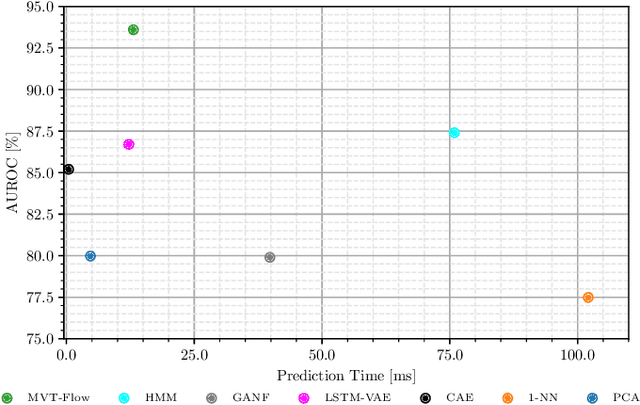
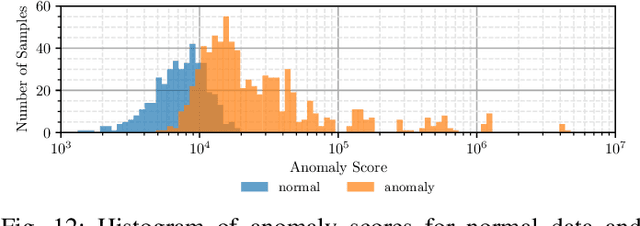
During the operation of industrial robots, unusual events may endanger the safety of humans and the quality of production. When collecting data to detect such cases, it is not ensured that data from all potentially occurring errors is included as unforeseeable events may happen over time. Therefore, anomaly detection (AD) delivers a practical solution, using only normal data to learn to detect unusual events. We introduce a dataset that allows training and benchmarking of anomaly detection methods for robotic applications based on machine data which will be made publicly available to the research community. As a typical robot task the dataset includes a pick-and-place application which involves movement, actions of the end effector and interactions with the objects of the environment. Since several of the contained anomalies are not task-specific but general, evaluations on our dataset are transferable to other robotics applications as well. Additionally, we present MVT-Flow (multivariate time-series flow) as a new baseline method for anomaly detection: It relies on deep-learning-based density estimation with normalizing flows, tailored to the data domain by taking its structure into account for the architecture. Our evaluation shows that MVT-Flow outperforms baselines from previous work by a large margin of 6.2% in area under ROC.