 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBoshu Lei
Beyond Uncertainty: Risk-Aware Active View Acquisition for Safe Robot Navigation and 3D Scene Understanding with FisherRF
Mar 18, 2024
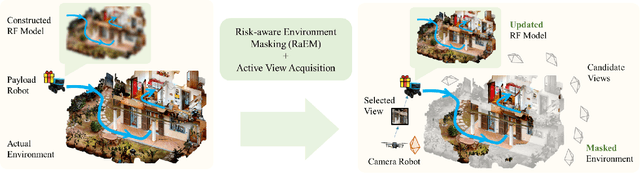
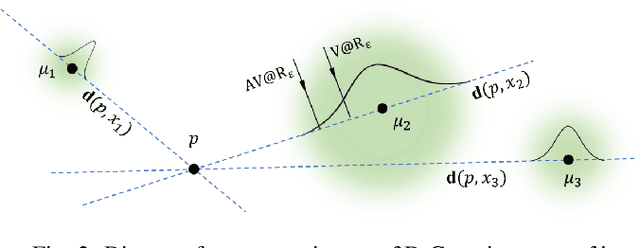
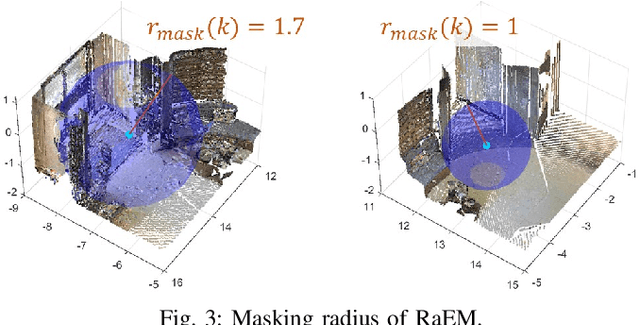
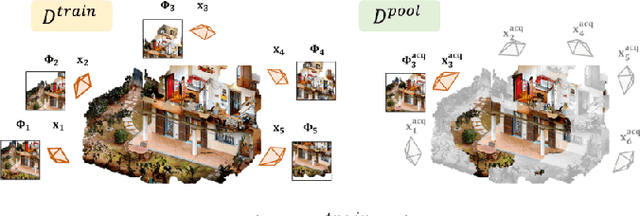
This work proposes a novel approach to bolster both the robot's risk assessment and safety measures while deepening its understanding of 3D scenes, which is achieved by leveraging Radiance Field (RF) models and 3D Gaussian Splatting. To further enhance these capabilities, we incorporate additional sampled views from the environment with the RF model. One of our key contributions is the introduction of Risk-aware Environment Masking (RaEM), which prioritizes crucial information by selecting the next-best-view that maximizes the expected information gain. This targeted approach aims to minimize uncertainties surrounding the robot's path and enhance the safety of its navigation. Our method offers a dual benefit: improved robot safety and increased efficiency in risk-aware 3D scene reconstruction and understanding. Extensive experiments in real-world scenarios demonstrate the effectiveness of our proposed approach, highlighting its potential to establish a robust and safety-focused framework for active robot exploration and 3D scene understanding.
FisherRF: Active View Selection and Uncertainty Quantification for Radiance Fields using Fisher Information
Nov 29, 2023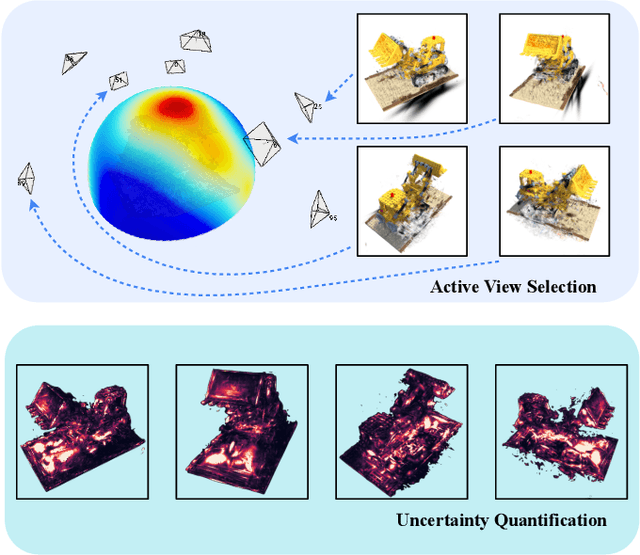
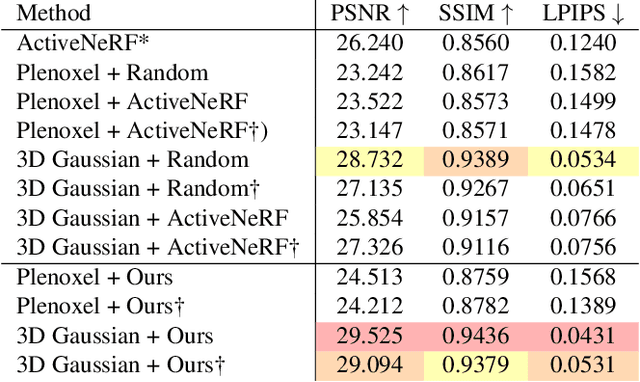

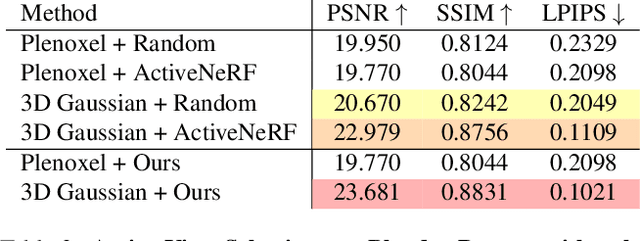
This study addresses the challenging problem of active view selection and uncertainty quantification within the domain of Radiance Fields. Neural Radiance Fields (NeRF) have greatly advanced image rendering and reconstruction, but the limited availability of 2D images poses uncertainties stemming from occlusions, depth ambiguities, and imaging errors. Efficiently selecting informative views becomes crucial, and quantifying NeRF model uncertainty presents intricate challenges. Existing approaches either depend on model architecture or are based on assumptions regarding density distributions that are not generally applicable. By leveraging Fisher Information, we efficiently quantify observed information within Radiance Fields without ground truth data. This can be used for the next best view selection and pixel-wise uncertainty quantification. Our method overcomes existing limitations on model architecture and effectiveness, achieving state-of-the-art results in both view selection and uncertainty quantification, demonstrating its potential to advance the field of Radiance Fields. Our method with the 3D Gaussian Splatting backend could perform view selections at 70 fps.
Multi-Risk-RRT: An Efficient Motion Planning Algorithm for Robotic Autonomous Luggage Trolley Collection at Airports
Sep 20, 2023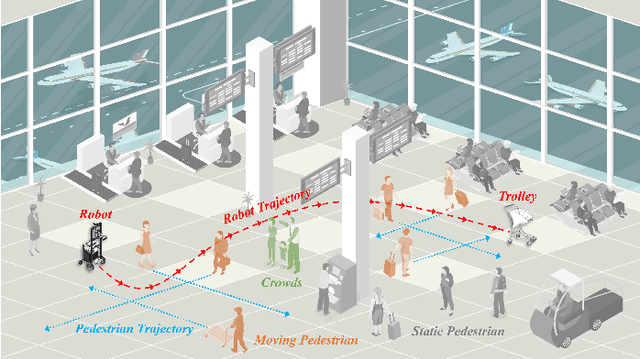


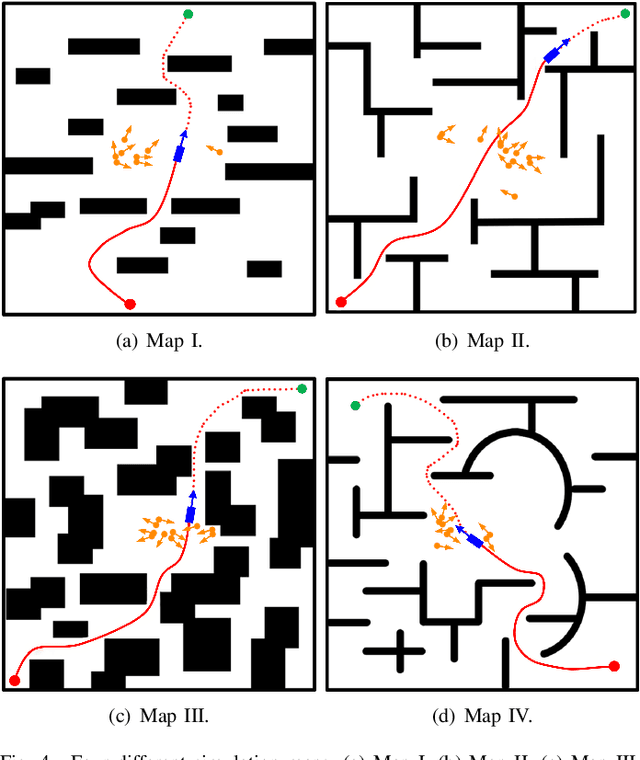
Robots have become increasingly prevalent in dynamic and crowded environments such as airports and shopping malls. In these scenarios, the critical challenges for robot navigation are reliability and timely arrival at predetermined destinations. While existing risk-based motion planning algorithms effectively reduce collision risks with static and dynamic obstacles, there is still a need for significant performance improvements. Specifically, the dynamic environments demand more rapid responses and robust planning. To address this gap, we introduce a novel risk-based multi-directional sampling algorithm, Multi-directional Risk-based Rapidly-exploring Random Tree (Multi-Risk-RRT). Unlike traditional algorithms that solely rely on a rooted tree or double trees for state space exploration, our approach incorporates multiple sub-trees. Each sub-tree independently explores its surrounding environment. At the same time, the primary rooted tree collects the heuristic information from these sub-trees, facilitating rapid progress toward the goal state. Our evaluations, including simulation and real-world environmental studies, demonstrate that Multi-Risk-RRT outperforms existing unidirectional and bi-directional risk-based algorithms in planning efficiency and robustness.
SuperGF: Unifying Local and Global Features for Visual Localization
Dec 23, 2022
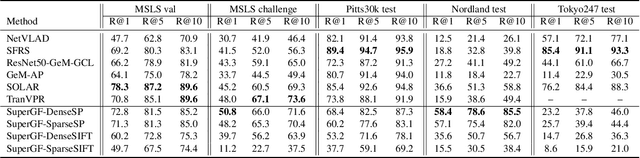
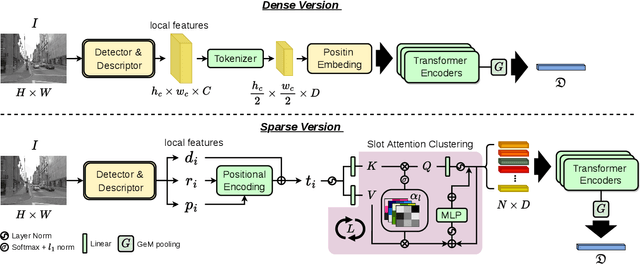
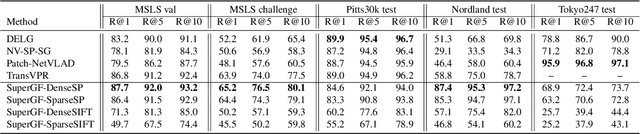
Advanced visual localization techniques encompass image retrieval challenges and 6 Degree-of-Freedom (DoF) camera pose estimation, such as hierarchical localization. Thus, they must extract global and local features from input images. Previous methods have achieved this through resource-intensive or accuracy-reducing means, such as combinatorial pipelines or multi-task distillation. In this study, we present a novel method called SuperGF, which effectively unifies local and global features for visual localization, leading to a higher trade-off between localization accuracy and computational efficiency. Specifically, SuperGF is a transformer-based aggregation model that operates directly on image-matching-specific local features and generates global features for retrieval. We conduct experimental evaluations of our method in terms of both accuracy and efficiency, demonstrating its advantages over other methods. We also provide implementations of SuperGF using various types of local features, including dense and sparse learning-based or hand-crafted descriptors.
GRM: Gradient Rectification Module for Visual Place Retrieval
Apr 23, 2022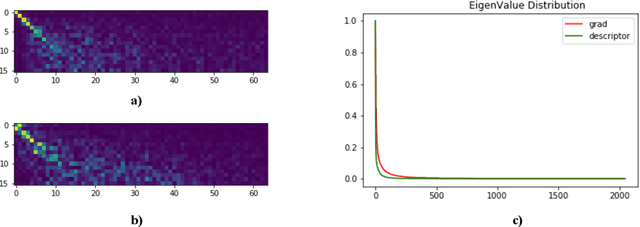
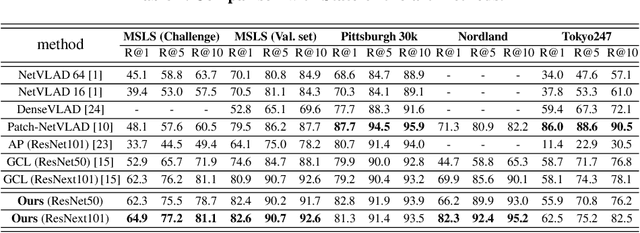
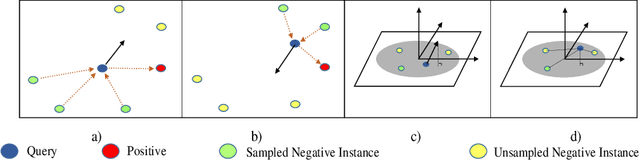
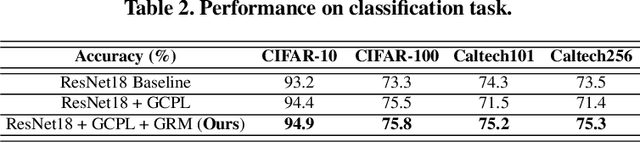
Visual place retrieval aims to search images in the database that depict similar places as the query image. However, global descriptors encoded by the network usually fall into a low dimensional principal space, which is harmful to the retrieval performance. We first analyze the cause of this phenomenon, pointing out that it is due to degraded distribution of the gradients of descriptors. Then, a new module called Gradient Rectification Module(GRM) is proposed to alleviate this issue. It can be appended after the final pooling layer. This module can rectify the gradients to the complement space of the principal space. Therefore, the network is encouraged to generate descriptors more uniformly in the whole space. At last, we conduct experiments on multiple datasets and generalize our method to classification task under prototype learning framework.