 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBowen Liu
Diffusion-Aided Joint Source Channel Coding For High Realism Wireless Image Transmission
Apr 27, 2024
Deep learning-based joint source-channel coding (deep JSCC) has been demonstrated as an effective approach for wireless image transmission. Nevertheless, current research has concentrated on minimizing a standard distortion metric such as Mean Squared Error (MSE), which does not necessarily improve the perceptual quality. To address this issue, we propose DiffJSCC, a novel framework that leverages pre-trained text-to-image diffusion models to enhance the realism of images transmitted over the channel. The proposed DiffJSCC utilizes prior deep JSCC frameworks to deliver an initial reconstructed image at the receiver. Then, the spatial and textual features are extracted from the initial reconstruction, which, together with the channel state information (e.g., signal-to-noise ratio, SNR), are passed to a control module to fine-tune the pre-trained Stable Diffusion model. Extensive experiments on the Kodak dataset reveal that our method significantly surpasses both conventional methods and prior deep JSCC approaches on perceptual metrics such as LPIPS and FID scores, especially with poor channel conditions and limited bandwidth. Notably, DiffJSCC can achieve highly realistic reconstructions for 768x512 pixel Kodak images with only 3072 symbols (<0.008 symbols per pixel) under 1dB SNR. Our code will be released in https://github.com/mingyuyng/DiffJSCC.
VisionCLIP: An Med-AIGC based Ethical Language-Image Foundation Model for Generalizable Retina Image Analysis
Mar 16, 2024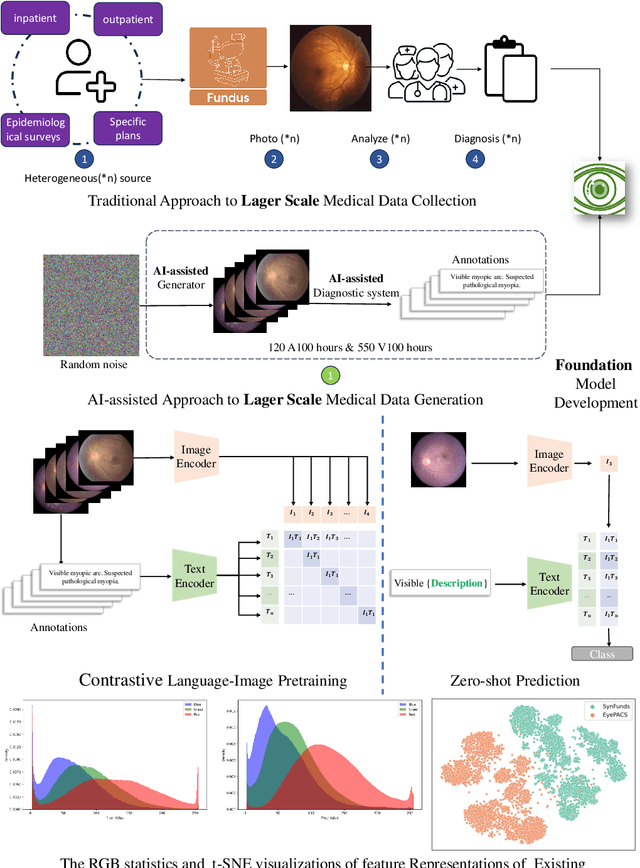
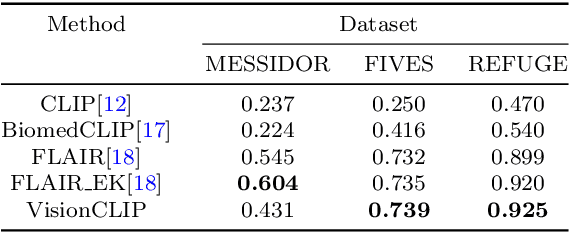
Generalist foundation model has ushered in newfound capabilities in medical domain. However, the contradiction between the growing demand for high-quality annotated data with patient privacy continues to intensify. The utilization of medical artificial intelligence generated content (Med-AIGC) as an inexhaustible resource repository arises as a potential solution to address the aforementioned challenge. Here we harness 1 million open-source synthetic fundus images paired with natural language descriptions, to curate an ethical language-image foundation model for retina image analysis named VisionCLIP. VisionCLIP achieves competitive performance on three external datasets compared with the existing method pre-trained on real-world data in a zero-shot fashion. The employment of artificially synthetic images alongside corresponding textual data for training enables the medical foundation model to successfully assimilate knowledge of disease symptomatology, thereby circumventing potential breaches of patient confidentiality.
Category-Agnostic Pose Estimation for Point Clouds
Mar 12, 2024

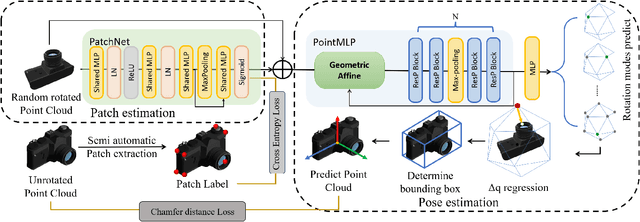
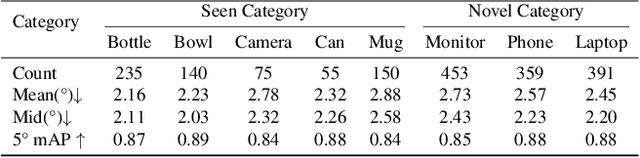
The goal of object pose estimation is to visually determine the pose of a specific object in the RGB-D input. Unfortunately, when faced with new categories, both instance-based and category-based methods are unable to deal with unseen objects of unseen categories, which is a challenge for pose estimation. To address this issue, this paper proposes a method to introduce geometric features for pose estimation of point clouds without requiring category information. The method is based only on the patch feature of the point cloud, a geometric feature with rotation invariance. After training without category information, our method achieves as good results as other category-based methods. Our method successfully achieved pose annotation of no category information instances on the CAMERA25 dataset and ModelNet40 dataset.
Quantum-Inspired Machine Learning for Molecular Docking
Jan 22, 2024Molecular docking is an important tool for structure-based drug design, accelerating the efficiency of drug development. Complex and dynamic binding processes between proteins and small molecules require searching and sampling over a wide spatial range. Traditional docking by searching for possible binding sites and conformations is computationally complex and results poorly under blind docking. Quantum-inspired algorithms combining quantum properties and annealing show great advantages in solving combinatorial optimization problems. Inspired by this, we achieve an improved in blind docking by using quantum-inspired combined with gradients learned by deep learning in the encoded molecular space. Numerical simulation shows that our method outperforms traditional docking algorithms and deep learning-based algorithms over 10\%. Compared to the current state-of-the-art deep learning-based docking algorithm DiffDock, the success rate of Top-1 (RMSD<2) achieves an improvement from 33\% to 35\% in our same setup. In particular, a 6\% improvement is realized in the high-precision region(RMSD<1) on molecules data unseen in DiffDock, which demonstrates the well-generalized of our method.
VCISR: Blind Single Image Super-Resolution with Video Compression Synthetic Data
Nov 02, 2023

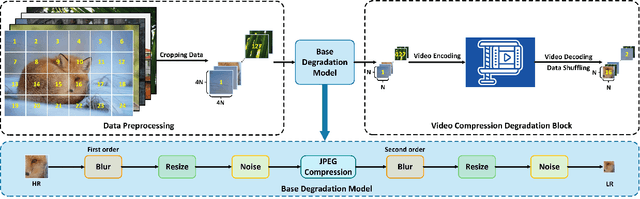

In the blind single image super-resolution (SISR) task, existing works have been successful in restoring image-level unknown degradations. However, when a single video frame becomes the input, these works usually fail to address degradations caused by video compression, such as mosquito noise, ringing, blockiness, and staircase noise. In this work, we for the first time, present a video compression-based degradation model to synthesize low-resolution image data in the blind SISR task. Our proposed image synthesizing method is widely applicable to existing image datasets, so that a single degraded image can contain distortions caused by the lossy video compression algorithms. This overcomes the leak of feature diversity in video data and thus retains the training efficiency. By introducing video coding artifacts to SISR degradation models, neural networks can super-resolve images with the ability to restore video compression degradations, and achieve better results on restoring generic distortions caused by image compression as well. Our proposed approach achieves superior performance in SOTA no-reference Image Quality Assessment, and shows better visual quality on various datasets. In addition, we evaluate the SISR neural network trained with our degradation model on video super-resolution (VSR) datasets. Compared to architectures specifically designed for the VSR purpose, our method exhibits similar or better performance, evidencing that the presented strategy on infusing video-based degradation is generalizable to address more complicated compression artifacts even without temporal cues.
TrTr: A Versatile Pre-Trained Large Traffic Model based on Transformer for Capturing Trajectory Diversity in Vehicle Population
Sep 22, 2023Understanding trajectory diversity is a fundamental aspect of addressing practical traffic tasks. However, capturing the diversity of trajectories presents challenges, particularly with traditional machine learning and recurrent neural networks due to the requirement of large-scale parameters. The emerging Transformer technology, renowned for its parallel computation capabilities enabling the utilization of models with hundreds of millions of parameters, offers a promising solution. In this study, we apply the Transformer architecture to traffic tasks, aiming to learn the diversity of trajectories within vehicle populations. We analyze the Transformer's attention mechanism and its adaptability to the goals of traffic tasks, and subsequently, design specific pre-training tasks. To achieve this, we create a data structure tailored to the attention mechanism and introduce a set of noises that correspond to spatio-temporal demands, which are incorporated into the structured data during the pre-training process. The designed pre-training model demonstrates excellent performance in capturing the spatial distribution of the vehicle population, with no instances of vehicle overlap and an RMSE of 0.6059 when compared to the ground truth values. In the context of time series prediction, approximately 95% of the predicted trajectories' speeds closely align with the true speeds, within a deviation of 7.5144m/s. Furthermore, in the stability test, the model exhibits robustness by continuously predicting a time series ten times longer than the input sequence, delivering smooth trajectories and showcasing diverse driving behaviors. The pre-trained model also provides a good basis for downstream fine-tuning tasks. The number of parameters of our model is over 50 million.
MMVC: Learned Multi-Mode Video Compression with Block-based Prediction Mode Selection and Density-Adaptive Entropy Coding
Apr 05, 2023



Learning-based video compression has been extensively studied over the past years, but it still has limitations in adapting to various motion patterns and entropy models. In this paper, we propose multi-mode video compression (MMVC), a block wise mode ensemble deep video compression framework that selects the optimal mode for feature domain prediction adapting to different motion patterns. Proposed multi-modes include ConvLSTM-based feature domain prediction, optical flow conditioned feature domain prediction, and feature propagation to address a wide range of cases from static scenes without apparent motions to dynamic scenes with a moving camera. We partition the feature space into blocks for temporal prediction in spatial block-based representations. For entropy coding, we consider both dense and sparse post-quantization residual blocks, and apply optional run-length coding to sparse residuals to improve the compression rate. In this sense, our method uses a dual-mode entropy coding scheme guided by a binary density map, which offers significant rate reduction surpassing the extra cost of transmitting the binary selection map. We validate our scheme with some of the most popular benchmarking datasets. Compared with state-of-the-art video compression schemes and standard codecs, our method yields better or competitive results measured with PSNR and MS-SSIM.
Unified Signal Compression Using a GAN with Iterative Latent Representation Optimization
Sep 23, 2021



We propose a unified signal compression framework that uses a generative adversarial network (GAN) to compress heterogeneous signals. The compressed signal is represented as a latent vector and fed into a generator network that is trained to produce high quality realistic signals that minimize a target objective function. To efficiently quantize the compressed signal, non-uniformly quantized optimal latent vectors are identified by iterative back-propagation with alternating direction method of multipliers (ADMM) optimization performed for each iteration. The performance of the proposed signal compression method is assessed using multiple metrics including PSNR and MS-SSIM for image compression and also PESR, Kaldi, LSTM, and MLP performance for speech compression. Test results show that the proposed work outperforms recent state-of-the-art hand-crafted and deep learning-based signal compression methods.
Capture Uncertainties in Deep Neural Networks for Safe Operation of Autonomous Driving Vehicles
Aug 11, 2021Uncertainties in Deep Neural Network (DNN)-based perception and vehicle's motion pose challenges to the development of safe autonomous driving vehicles. In this paper, we propose a safe motion planning framework featuring the quantification and propagation of DNN-based perception uncertainties and motion uncertainties. Contributions of this work are twofold: (1) A Bayesian Deep Neural network model which detects 3D objects and quantitatively captures the associated aleatoric and epistemic uncertainties of DNNs; (2) An uncertainty-aware motion planning algorithm (PU-RRT) that accounts for uncertainties in object detection and ego-vehicle's motion. The proposed approaches are validated via simulated complex scenarios built in CARLA. Experimental results show that the proposed motion planning scheme can cope with uncertainties of DNN-based perception and vehicle motion, and improve the operational safety of autonomous vehicles while still achieving desirable efficiency.
Uncertainty-aware Joint Salient Object and Camouflaged Object Detection
Apr 06, 2021



Visual salient object detection (SOD) aims at finding the salient object(s) that attract human attention, while camouflaged object detection (COD) on the contrary intends to discover the camouflaged object(s) that hidden in the surrounding. In this paper, we propose a paradigm of leveraging the contradictory information to enhance the detection ability of both salient object detection and camouflaged object detection. We start by exploiting the easy positive samples in the COD dataset to serve as hard positive samples in the SOD task to improve the robustness of the SOD model. Then, we introduce a similarity measure module to explicitly model the contradicting attributes of these two tasks. Furthermore, considering the uncertainty of labeling in both tasks' datasets, we propose an adversarial learning network to achieve both higher order similarity measure and network confidence estimation. Experimental results on benchmark datasets demonstrate that our solution leads to state-of-the-art (SOTA) performance for both tasks.