 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBoxin Shi
SpikeNVS: Enhancing Novel View Synthesis from Blurry Images via Spike Camera
Apr 12, 2024
One of the most critical factors in achieving sharp Novel View Synthesis (NVS) using neural field methods like Neural Radiance Fields (NeRF) and 3D Gaussian Splatting (3DGS) is the quality of the training images. However, Conventional RGB cameras are susceptible to motion blur. In contrast, neuromorphic cameras like event and spike cameras inherently capture more comprehensive temporal information, which can provide a sharp representation of the scene as additional training data. Recent methods have explored the integration of event cameras to improve the quality of NVS. The event-RGB approaches have some limitations, such as high training costs and the inability to work effectively in the background. Instead, our study introduces a new method that uses the spike camera to overcome these limitations. By considering texture reconstruction from spike streams as ground truth, we design the Texture from Spike (TfS) loss. Since the spike camera relies on temporal integration instead of temporal differentiation used by event cameras, our proposed TfS loss maintains manageable training costs. It handles foreground objects with backgrounds simultaneously. We also provide a real-world dataset captured with our spike-RGB camera system to facilitate future research endeavors. We conduct extensive experiments using synthetic and real-world datasets to demonstrate that our design can enhance novel view synthesis across NeRF and 3DGS. The code and dataset will be made available for public access.
Spin-UP: Spin Light for Natural Light Uncalibrated Photometric Stereo
Apr 02, 2024Natural Light Uncalibrated Photometric Stereo (NaUPS) relieves the strict environment and light assumptions in classical Uncalibrated Photometric Stereo (UPS) methods. However, due to the intrinsic ill-posedness and high-dimensional ambiguities, addressing NaUPS is still an open question. Existing works impose strong assumptions on the environment lights and objects' material, restricting the effectiveness in more general scenarios. Alternatively, some methods leverage supervised learning with intricate models while lacking interpretability, resulting in a biased estimation. In this work, we proposed Spin Light Uncalibrated Photometric Stereo (Spin-UP), an unsupervised method to tackle NaUPS in various environment lights and objects. The proposed method uses a novel setup that captures the object's images on a rotatable platform, which mitigates NaUPS's ill-posedness by reducing unknowns and provides reliable priors to alleviate NaUPS's ambiguities. Leveraging neural inverse rendering and the proposed training strategies, Spin-UP recovers surface normals, environment light, and isotropic reflectance under complex natural light with low computational cost. Experiments have shown that Spin-UP outperforms other supervised / unsupervised NaUPS methods and achieves state-of-the-art performance on synthetic and real-world datasets. Codes and data are available at https://github.com/LMozart/CVPR2024-SpinUP.
Complementing Event Streams and RGB Frames for Hand Mesh Reconstruction
Mar 12, 2024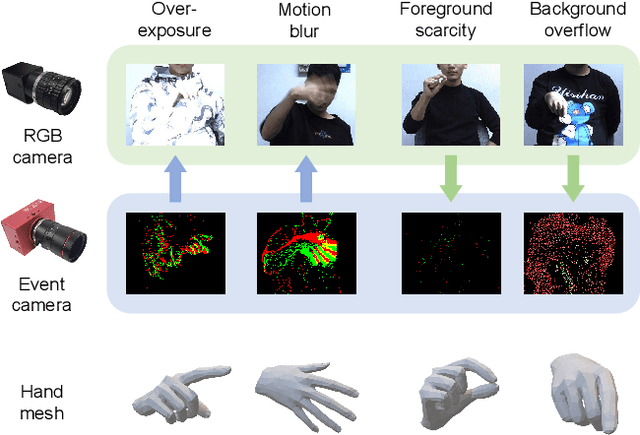
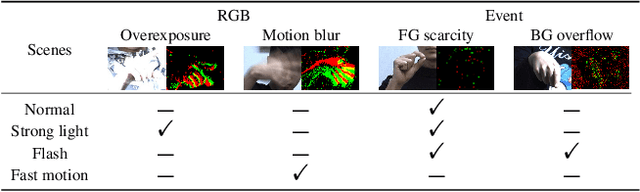
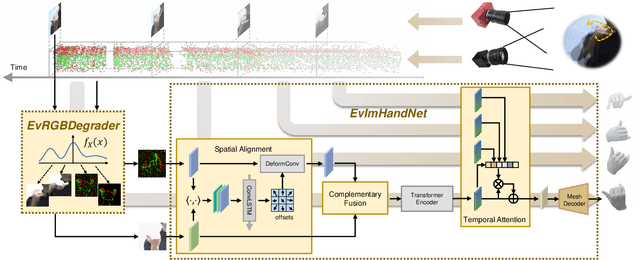
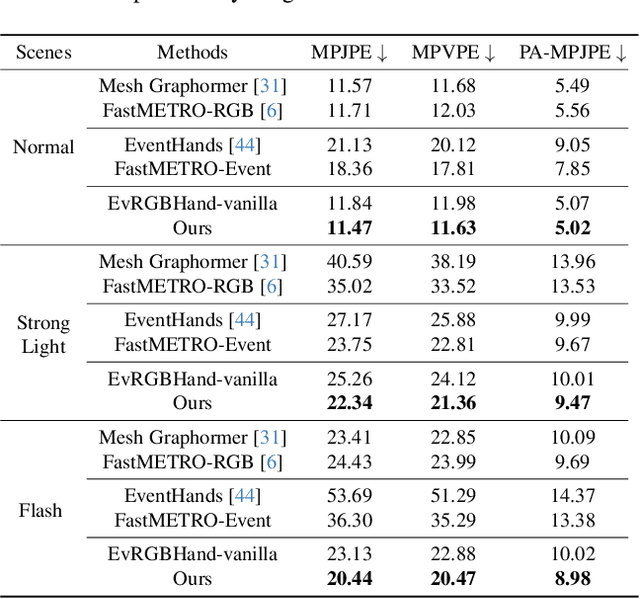
Reliable hand mesh reconstruction (HMR) from commonly-used color and depth sensors is challenging especially under scenarios with varied illuminations and fast motions. Event camera is a highly promising alternative for its high dynamic range and dense temporal resolution properties, but it lacks key texture appearance for hand mesh reconstruction. In this paper, we propose EvRGBHand -- the first approach for 3D hand mesh reconstruction with an event camera and an RGB camera compensating for each other. By fusing two modalities of data across time, space, and information dimensions,EvRGBHand can tackle overexposure and motion blur issues in RGB-based HMR and foreground scarcity and background overflow issues in event-based HMR. We further propose EvRGBDegrader, which allows our model to generalize effectively in challenging scenes, even when trained solely on standard scenes, thus reducing data acquisition costs. Experiments on real-world data demonstrate that EvRGBHand can effectively solve the challenging issues when using either type of camera alone via retaining the merits of both, and shows the potential of generalization to outdoor scenes and another type of event camera.
Colorizing Monochromatic Radiance Fields
Feb 19, 2024Though Neural Radiance Fields (NeRF) can produce colorful 3D representations of the world by using a set of 2D images, such ability becomes non-existent when only monochromatic images are provided. Since color is necessary in representing the world, reproducing color from monochromatic radiance fields becomes crucial. To achieve this goal, instead of manipulating the monochromatic radiance fields directly, we consider it as a representation-prediction task in the Lab color space. By first constructing the luminance and density representation using monochromatic images, our prediction stage can recreate color representation on the basis of an image colorization module. We then reproduce a colorful implicit model through the representation of luminance, density, and color. Extensive experiments have been conducted to validate the effectiveness of our approaches. Our project page: https://liquidammonia.github.io/color-nerf.
Language-guided Image Reflection Separation
Feb 19, 2024This paper studies the problem of language-guided reflection separation, which aims at addressing the ill-posed reflection separation problem by introducing language descriptions to provide layer content. We propose a unified framework to solve this problem, which leverages the cross-attention mechanism with contrastive learning strategies to construct the correspondence between language descriptions and image layers. A gated network design and a randomized training strategy are employed to tackle the recognizable layer ambiguity. The effectiveness of the proposed method is validated by the significant performance advantage over existing reflection separation methods on both quantitative and qualitative comparisons.
EvPlug: Learn a Plug-and-Play Module for Event and Image Fusion
Dec 28, 2023Event cameras and RGB cameras exhibit complementary characteristics in imaging: the former possesses high dynamic range (HDR) and high temporal resolution, while the latter provides rich texture and color information. This makes the integration of event cameras into middle- and high-level RGB-based vision tasks highly promising. However, challenges arise in multi-modal fusion, data annotation, and model architecture design. In this paper, we propose EvPlug, which learns a plug-and-play event and image fusion module from the supervision of the existing RGB-based model. The learned fusion module integrates event streams with image features in the form of a plug-in, endowing the RGB-based model to be robust to HDR and fast motion scenes while enabling high temporal resolution inference. Our method only requires unlabeled event-image pairs (no pixel-wise alignment required) and does not alter the structure or weights of the RGB-based model. We demonstrate the superiority of EvPlug in several vision tasks such as object detection, semantic segmentation, and 3D hand pose estimation
Pano-NeRF: Synthesizing High Dynamic Range Novel Views with Geometry from Sparse Low Dynamic Range Panoramic Images
Dec 26, 2023Panoramic imaging research on geometry recovery and High Dynamic Range (HDR) reconstruction becomes a trend with the development of Extended Reality (XR). Neural Radiance Fields (NeRF) provide a promising scene representation for both tasks without requiring extensive prior data. However, in the case of inputting sparse Low Dynamic Range (LDR) panoramic images, NeRF often degrades with under-constrained geometry and is unable to reconstruct HDR radiance from LDR inputs. We observe that the radiance from each pixel in panoramic images can be modeled as both a signal to convey scene lighting information and a light source to illuminate other pixels. Hence, we propose the irradiance fields from sparse LDR panoramic images, which increases the observation counts for faithful geometry recovery and leverages the irradiance-radiance attenuation for HDR reconstruction. Extensive experiments demonstrate that the irradiance fields outperform state-of-the-art methods on both geometry recovery and HDR reconstruction and validate their effectiveness. Furthermore, we show a promising byproduct of spatially-varying lighting estimation. The code is available at https://github.com/Lu-Zhan/Pano-NeRF.
EventAid: Benchmarking Event-aided Image/Video Enhancement Algorithms with Real-captured Hybrid Dataset
Dec 13, 2023Event cameras are emerging imaging technology that offers advantages over conventional frame-based imaging sensors in dynamic range and sensing speed. Complementing the rich texture and color perception of traditional image frames, the hybrid camera system of event and frame-based cameras enables high-performance imaging. With the assistance of event cameras, high-quality image/video enhancement methods make it possible to break the limits of traditional frame-based cameras, especially exposure time, resolution, dynamic range, and frame rate limits. This paper focuses on five event-aided image and video enhancement tasks (i.e., event-based video reconstruction, event-aided high frame rate video reconstruction, image deblurring, image super-resolution, and high dynamic range image reconstruction), provides an analysis of the effects of different event properties, a real-captured and ground truth labeled benchmark dataset, a unified benchmarking of state-of-the-art methods, and an evaluation for two mainstream event simulators. In detail, this paper collects a real-captured evaluation dataset EventAid for five event-aided image/video enhancement tasks, by using "Event-RGB" multi-camera hybrid system, taking into account scene diversity and spatiotemporal synchronization. We further perform quantitative and visual comparisons for state-of-the-art algorithms, provide a controlled experiment to analyze the performance limit of event-aided image deblurring methods, and discuss open problems to inspire future research.
Surface Geometry Processing: An Efficient Normal-based Detail Representation
Jul 16, 2023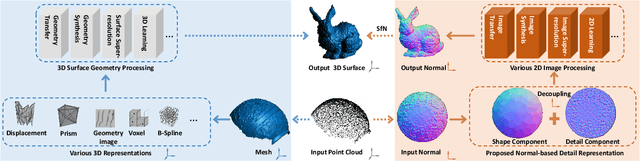
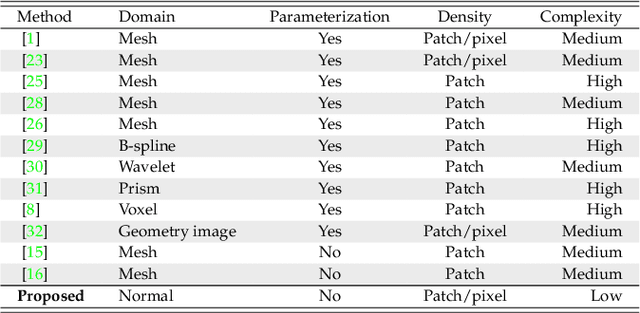
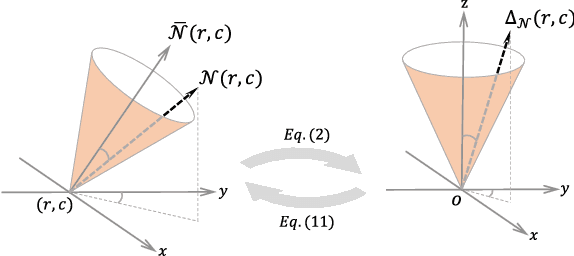
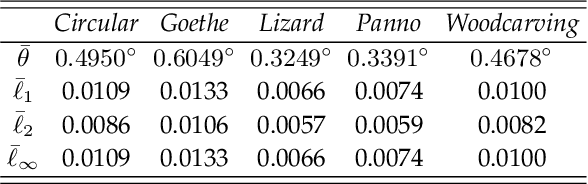
With the rapid development of high-resolution 3D vision applications, the traditional way of manipulating surface detail requires considerable memory and computing time. To address these problems, we introduce an efficient surface detail processing framework in 2D normal domain, which extracts new normal feature representations as the carrier of micro geometry structures that are illustrated both theoretically and empirically in this article. Compared with the existing state of the arts, we verify and demonstrate that the proposed normal-based representation has three important properties, including detail separability, detail transferability and detail idempotence. Finally, three new schemes are further designed for geometric surface detail processing applications, including geometric texture synthesis, geometry detail transfer, and 3D surface super-resolution. Theoretical analysis and experimental results on the latest benchmark dataset verify the effectiveness and versatility of our normal-based representation, which accepts 30 times of the input surface vertices but at the same time only takes 6.5% memory cost and 14.0% running time in comparison with existing competing algorithms.
* 16 pages, 22 figures
L-CAD: Language-based Colorization with Any-level Descriptions
May 26, 2023
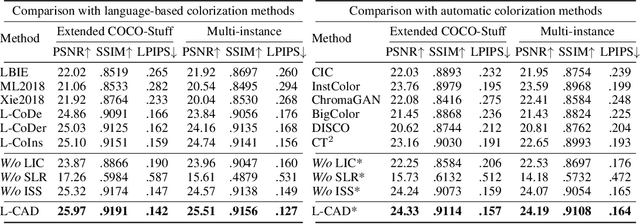
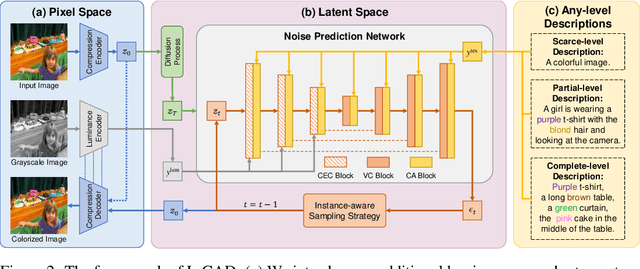
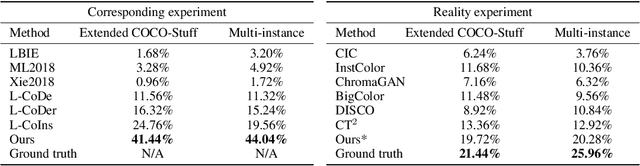
Language-based colorization produces plausible and visually pleasing colors under the guidance of user-friendly natural language descriptions. Previous methods implicitly assume that users provide comprehensive color descriptions for most of the objects in the image, which leads to suboptimal performance. In this paper, we propose a unified model to perform language-based colorization with any-level descriptions. We leverage the pretrained cross-modality generative model for its robust language understanding and rich color priors to handle the inherent ambiguity of any-level descriptions. We further design modules to align with input conditions to preserve local spatial structures and prevent the ghosting effect. With the proposed novel sampling strategy, our model achieves instance-aware colorization in diverse and complex scenarios. Extensive experimental results demonstrate our advantages of effectively handling any-level descriptions and outperforming both language-based and automatic colorization methods. The code and pretrained models are available at: https://github.com/changzheng123/L-CAD.