 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBoyang Zhang
CompdVision: Combining Near-Field 3D Visual and Tactile Sensing Using a Compact Compound-Eye Imaging System
Dec 12, 2023
As automation technologies advance, the need for compact and multi-modal sensors in robotic applications is growing. To address this demand, we introduce CompdVision, a novel sensor that combines near-field 3D visual and tactile sensing. This sensor, with dimensions of 22$\times$14$\times$14 mm, leverages the compound eye imaging system to achieve a compact form factor without compromising its dual modalities. CompdVision utilizes two types of vision units to meet diverse sensing requirements. Stereo units with far-focus lenses can see through the transparent elastomer, facilitating depth estimation beyond the contact surface, while tactile units with near-focus lenses track the movement of markers embedded in the elastomer to obtain contact deformation. Experimental results validate the sensor's superior performance in 3D visual and tactile sensing. The sensor demonstrates effective depth estimation within a 70mm range from its surface. Additionally, it registers high accuracy in tangential and normal force measurements. The dual modalities and compact design make the sensor a versatile tool for complex robotic tasks.
SecurityNet: Assessing Machine Learning Vulnerabilities on Public Models
Oct 19, 2023While advanced machine learning (ML) models are deployed in numerous real-world applications, previous works demonstrate these models have security and privacy vulnerabilities. Various empirical research has been done in this field. However, most of the experiments are performed on target ML models trained by the security researchers themselves. Due to the high computational resource requirement for training advanced models with complex architectures, researchers generally choose to train a few target models using relatively simple architectures on typical experiment datasets. We argue that to understand ML models' vulnerabilities comprehensively, experiments should be performed on a large set of models trained with various purposes (not just the purpose of evaluating ML attacks and defenses). To this end, we propose using publicly available models with weights from the Internet (public models) for evaluating attacks and defenses on ML models. We establish a database, namely SecurityNet, containing 910 annotated image classification models. We then analyze the effectiveness of several representative attacks/defenses, including model stealing attacks, membership inference attacks, and backdoor detection on these public models. Our evaluation empirically shows the performance of these attacks/defenses can vary significantly on public models compared to self-trained models. We share SecurityNet with the research community. and advocate researchers to perform experiments on public models to better demonstrate their proposed methods' effectiveness in the future.
A Plot is Worth a Thousand Words: Model Information Stealing Attacks via Scientific Plots
Feb 23, 2023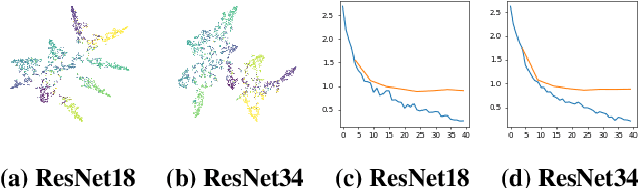



Building advanced machine learning (ML) models requires expert knowledge and many trials to discover the best architecture and hyperparameter settings. Previous work demonstrates that model information can be leveraged to assist other attacks, such as membership inference, generating adversarial examples. Therefore, such information, e.g., hyperparameters, should be kept confidential. It is well known that an adversary can leverage a target ML model's output to steal the model's information. In this paper, we discover a new side channel for model information stealing attacks, i.e., models' scientific plots which are extensively used to demonstrate model performance and are easily accessible. Our attack is simple and straightforward. We leverage the shadow model training techniques to generate training data for the attack model which is essentially an image classifier. Extensive evaluation on three benchmark datasets shows that our proposed attack can effectively infer the architecture/hyperparameters of image classifiers based on convolutional neural network (CNN) given the scientific plot generated from it. We also reveal that the attack's success is mainly caused by the shape of the scientific plots, and further demonstrate that the attacks are robust in various scenarios. Given the simplicity and effectiveness of the attack method, our study indicates scientific plots indeed constitute a valid side channel for model information stealing attacks. To mitigate the attacks, we propose several defense mechanisms that can reduce the original attacks' accuracy while maintaining the plot utility. However, such defenses can still be bypassed by adaptive attacks.
Spatio-temporal Tendency Reasoning for Human Body Pose and Shape Estimation from Videos
Oct 10, 2022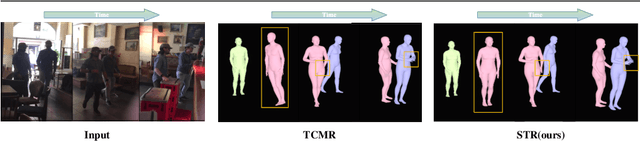
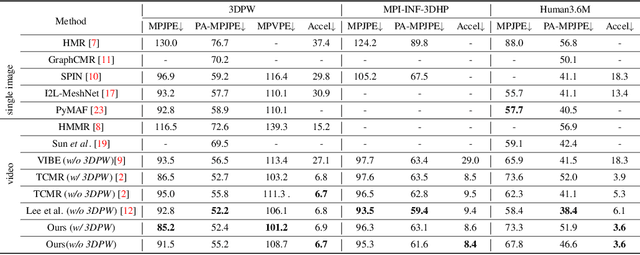
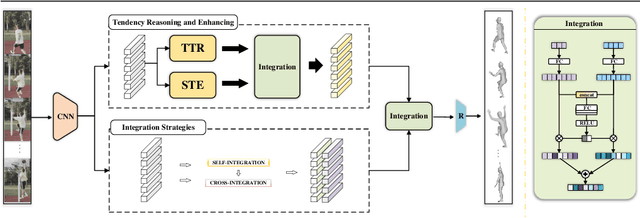

In this paper, we present a spatio-temporal tendency reasoning (STR) network for recovering human body pose and shape from videos. Previous approaches have focused on how to extend 3D human datasets and temporal-based learning to promote accuracy and temporal smoothing. Different from them, our STR aims to learn accurate and natural motion sequences in an unconstrained environment through temporal and spatial tendency and to fully excavate the spatio-temporal features of existing video data. To this end, our STR learns the representation of features in the temporal and spatial dimensions respectively, to concentrate on a more robust representation of spatio-temporal features. More specifically, for efficient temporal modeling, we first propose a temporal tendency reasoning (TTR) module. TTR constructs a time-dimensional hierarchical residual connection representation within a video sequence to effectively reason temporal sequences' tendencies and retain effective dissemination of human information. Meanwhile, for enhancing the spatial representation, we design a spatial tendency enhancing (STE) module to further learns to excite spatially time-frequency domain sensitive features in human motion information representations. Finally, we introduce integration strategies to integrate and refine the spatio-temporal feature representations. Extensive experimental findings on large-scale publically available datasets reveal that our STR remains competitive with the state-of-the-art on three datasets. Our code are available at https://github.com/Changboyang/STR.git.