 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBrendan van Rooyen
Learning from Binary Labels with Instance-Dependent Corruption
May 04, 2016
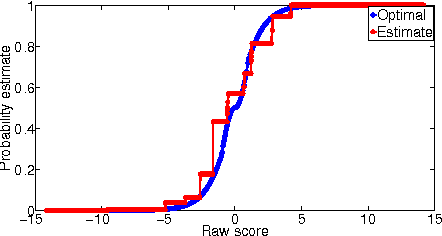

Suppose we have a sample of instances paired with binary labels corrupted by arbitrary instance- and label-dependent noise. With sufficiently many such samples, can we optimally classify and rank instances with respect to the noise-free distribution? We provide a theoretical analysis of this question, with three main contributions. First, we prove that for instance-dependent noise, any algorithm that is consistent for classification on the noisy distribution is also consistent on the clean distribution. Second, we prove that for a broad class of instance- and label-dependent noise, a similar consistency result holds for the area under the ROC curve. Third, for the latter noise model, when the noise-free class-probability function belongs to the generalised linear model family, we show that the Isotron can efficiently and provably learn from the corrupted sample.
An Average Classification Algorithm
Dec 15, 2015
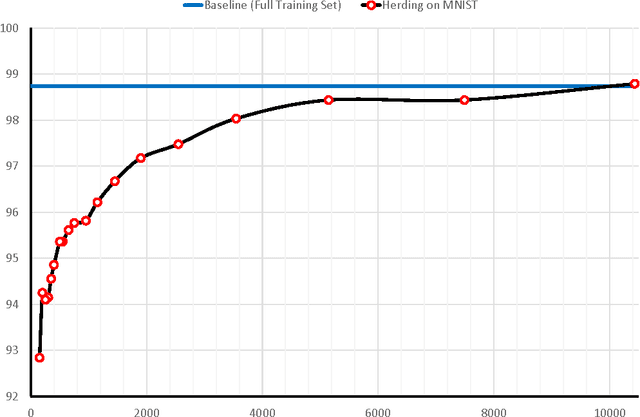
Many classification algorithms produce a classifier that is a weighted average of kernel evaluations. When working with a high or infinite dimensional kernel, it is imperative for speed of evaluation and storage issues that as few training samples as possible are used in the kernel expansion. Popular existing approaches focus on altering standard learning algorithms, such as the Support Vector Machine, to induce sparsity, as well as post-hoc procedures for sparse approximations. Here we adopt the latter approach. We begin with a very simple classifier, given by the kernel mean $$ f(x) = \frac{1}{n} \sum\limits_{i=i}^{n} y_i K(x_i,x) $$ We then find a sparse approximation to this kernel mean via herding. The result is an accurate, easily parallelized algorithm for learning classifiers.
Learning in the Presence of Corruption
Jul 04, 2015
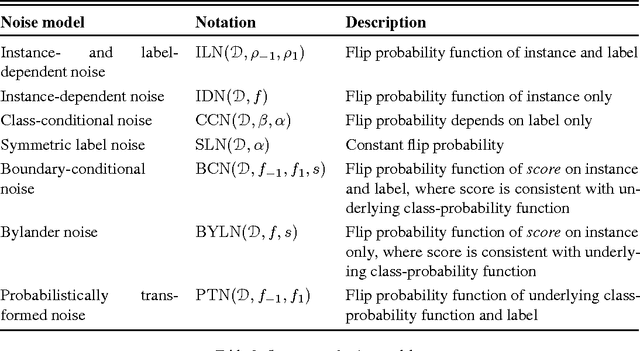
In supervised learning one wishes to identify a pattern present in a joint distribution $P$, of instances, label pairs, by providing a function $f$ from instances to labels that has low risk $\mathbb{E}_{P}\ell(y,f(x))$. To do so, the learner is given access to $n$ iid samples drawn from $P$. In many real world problems clean samples are not available. Rather, the learner is given access to samples from a corrupted distribution $\tilde{P}$ from which to learn, while the goal of predicting the clean pattern remains. There are many different types of corruption one can consider, and as of yet there is no general means to compare the relative ease of learning under these different corruption processes. In this paper we develop a general framework for tackling such problems as well as introducing upper and lower bounds on the risk for learning in the presence of corruption. Our ultimate goal is to be able to make informed economic decisions in regards to the acquisition of data sets. For a certain subclass of corruption processes (those that are \emph{reconstructible}) we achieve this goal in a particular sense. Our lower bounds are in terms of the coefficient of ergodicity, a simple to calculate property of stochastic matrices. Our upper bounds proceed via a generalization of the method of unbiased estimators appearing in recent work of Natarajan et al and implicit in the earlier work of Kearns.
Learning with Symmetric Label Noise: The Importance of Being Unhinged
May 28, 2015
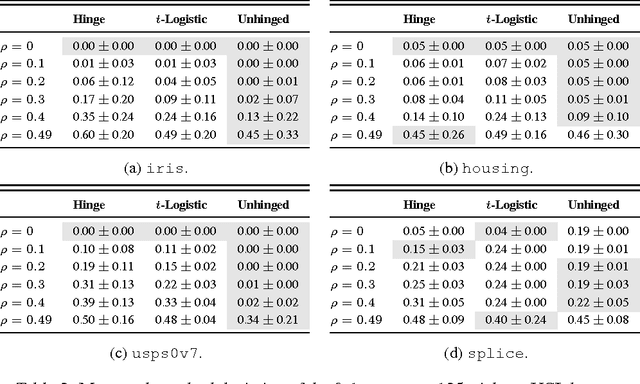
Convex potential minimisation is the de facto approach to binary classification. However, Long and Servedio [2010] proved that under symmetric label noise (SLN), minimisation of any convex potential over a linear function class can result in classification performance equivalent to random guessing. This ostensibly shows that convex losses are not SLN-robust. In this paper, we propose a convex, classification-calibrated loss and prove that it is SLN-robust. The loss avoids the Long and Servedio [2010] result by virtue of being negatively unbounded. The loss is a modification of the hinge loss, where one does not clamp at zero; hence, we call it the unhinged loss. We show that the optimal unhinged solution is equivalent to that of a strongly regularised SVM, and is the limiting solution for any convex potential; this implies that strong l2 regularisation makes most standard learners SLN-robust. Experiments confirm the SLN-robustness of the unhinged loss.
A Theory of Feature Learning
Apr 01, 2015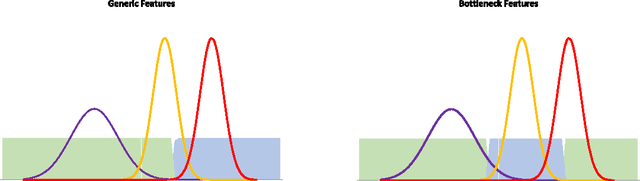
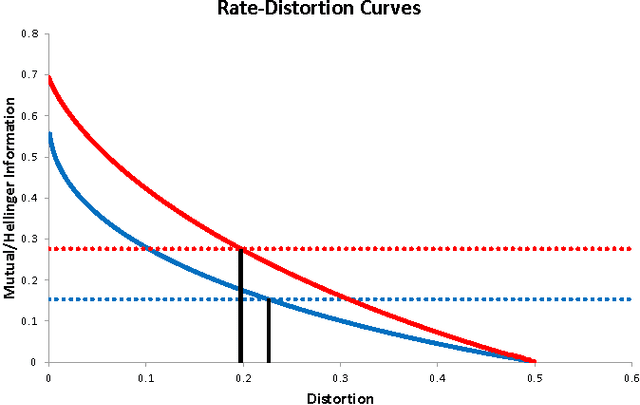
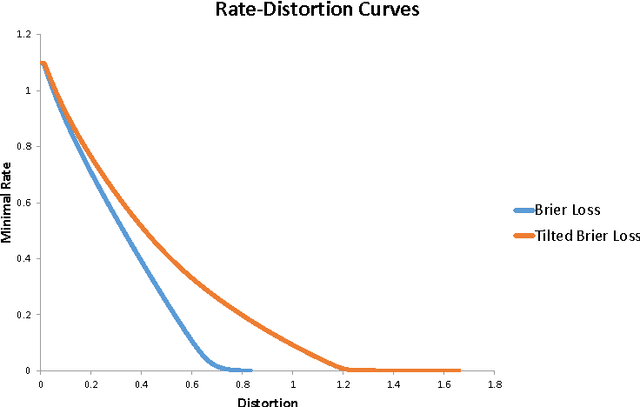
Feature Learning aims to extract relevant information contained in data sets in an automated fashion. It is driving force behind the current deep learning trend, a set of methods that have had widespread empirical success. What is lacking is a theoretical understanding of different feature learning schemes. This work provides a theoretical framework for feature learning and then characterizes when features can be learnt in an unsupervised fashion. We also provide means to judge the quality of features via rate-distortion theory and its generalizations.
Le Cam meets LeCun: Deficiency and Generic Feature Learning
Feb 21, 2014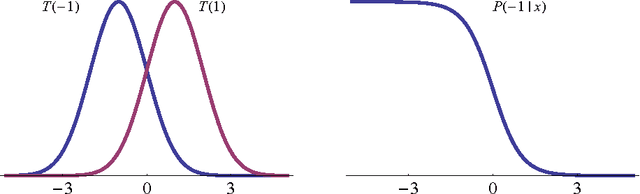
"Deep Learning" methods attempt to learn generic features in an unsupervised fashion from a large unlabelled data set. These generic features should perform as well as the best hand crafted features for any learning problem that makes use of this data. We provide a definition of generic features, characterize when it is possible to learn them and provide methods closely related to the autoencoder and deep belief network of deep learning. In order to do so we use the notion of deficiency and illustrate its value in studying certain general learning problems.