 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBrent Logan
Fully Nonparametric Bayesian Additive Regression Trees
Jul 09, 2018
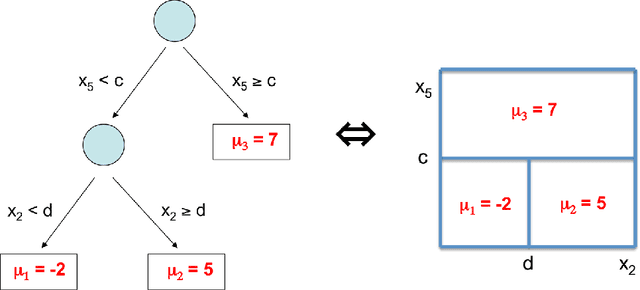
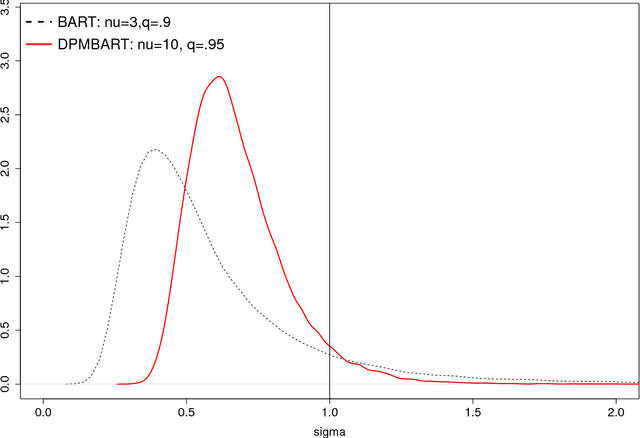
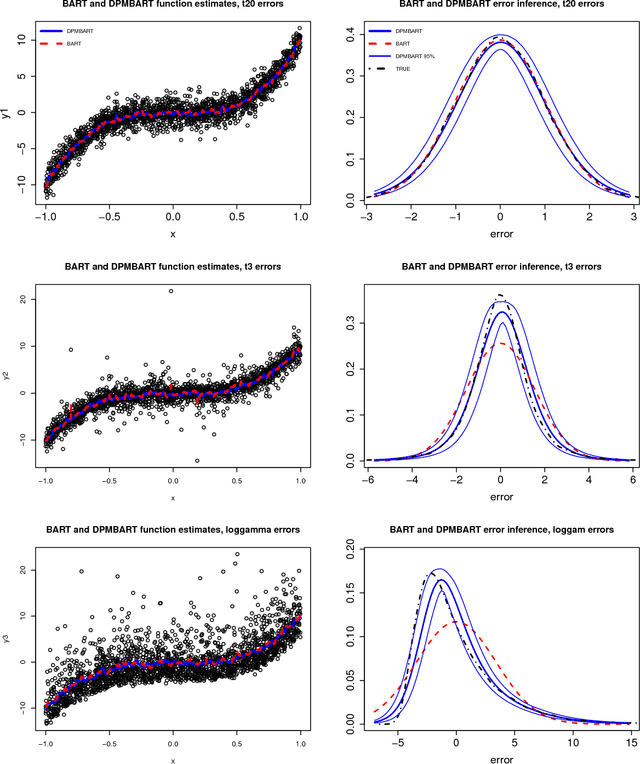
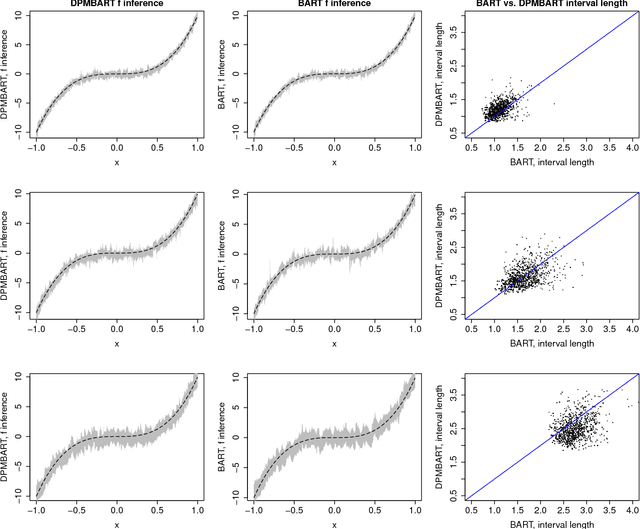
Bayesian Additive Regression Trees (BART) is a fully Bayesian approach to modeling with ensembles of trees. BART can uncover complex regression functions with high dimensional regressors in a fairly automatic way and provide Bayesian quantification of the uncertainty through the posterior. However, BART assumes IID normal errors. This strong parametric assumption can lead to misleading inference and uncertainty quantification. In this paper, we use the classic Dirichlet process mixture (DPM) mechanism to nonparametrically model the error distribution. A key strength of BART is that default prior settings work reasonably well in a variety of problems. The challenge in extending BART is to choose the parameters of the DPM so that the strengths of the standard BART approach is not lost when the errors are close to normal, but the DPM has the ability to adapt to non-normal errors.
Deep Reinforcement Learning for Dynamic Treatment Regimes on Medical Registry Data
Jan 28, 2018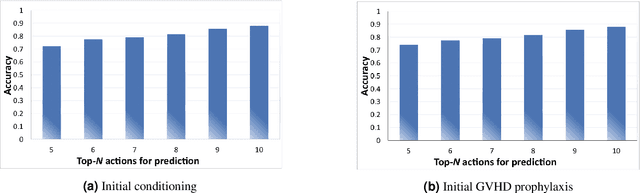

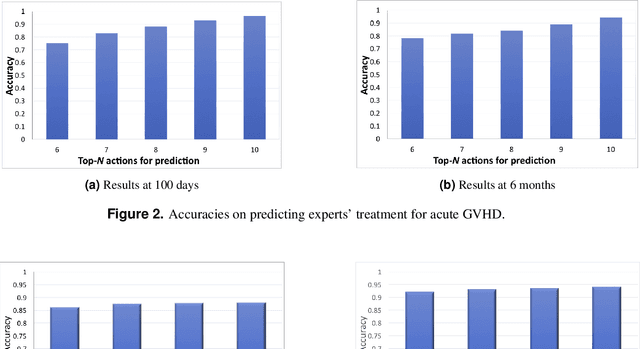
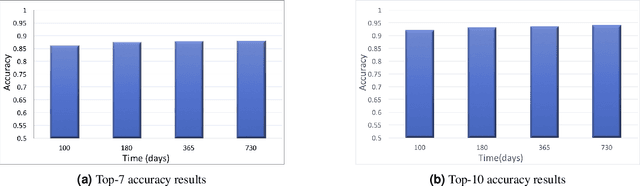
This paper presents the first deep reinforcement learning (DRL) framework to estimate the optimal Dynamic Treatment Regimes from observational medical data. This framework is more flexible and adaptive for high dimensional action and state spaces than existing reinforcement learning methods to model real-life complexity in heterogeneous disease progression and treatment choices, with the goal of providing doctor and patients the data-driven personalized decision recommendations. The proposed DRL framework comprises (i) a supervised learning step to predict the most possible expert actions, and (ii) a deep reinforcement learning step to estimate the long-term value function of Dynamic Treatment Regimes. Both steps depend on deep neural networks. As a key motivational example, we have implemented the proposed framework on a data set from the Center for International Bone Marrow Transplant Research (CIBMTR) registry database, focusing on the sequence of prevention and treatments for acute and chronic graft versus host disease after transplantation. In the experimental results, we have demonstrated promising accuracy in predicting human experts' decisions, as well as the high expected reward function in the DRL-based dynamic treatment regimes.