 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBrian Lucena
Nonparametric Probabilistic Regression with Coarse Learners
Oct 28, 2022
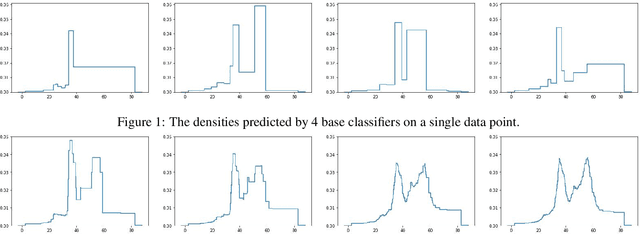
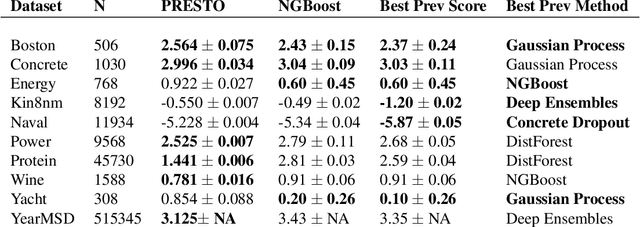
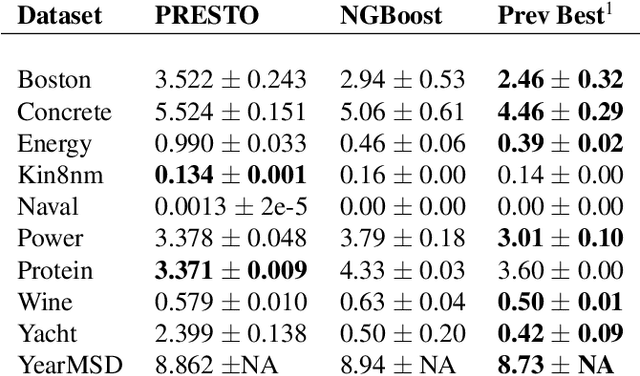
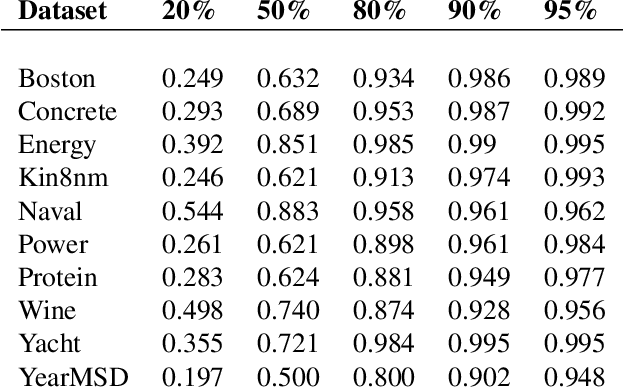
Probabilistic Regression refers to predicting a full probability density function for the target conditional on the features. We present a nonparametric approach to this problem which combines base classifiers (typically gradient boosted forests) trained on different coarsenings of the target value. By combining such classifiers and averaging the resulting densities, we are able to compute precise conditional densities with minimal assumptions on the shape or form of the density. We combine this approach with a structured cross-entropy loss function which serves to regularize and smooth the resulting densities. Prediction intervals computed from these densities are shown to have high fidelity in practice. Furthermore, examining the properties of these densities on particular observations can provide valuable insight. We demonstrate this approach on a variety of datasets and show competitive performance, particularly on larger datasets.
Loss Functions for Classification using Structured Entropy
Jun 14, 2022
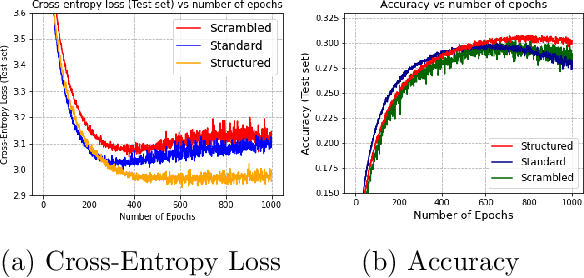
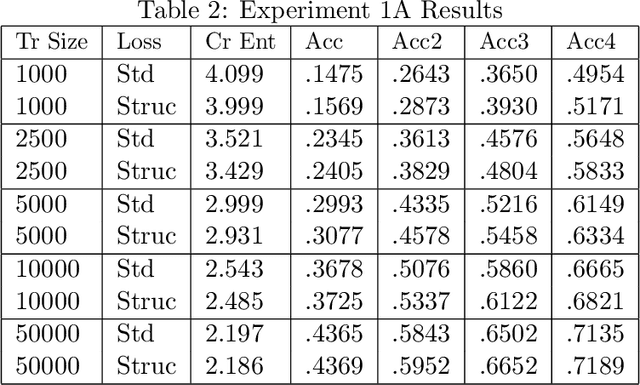
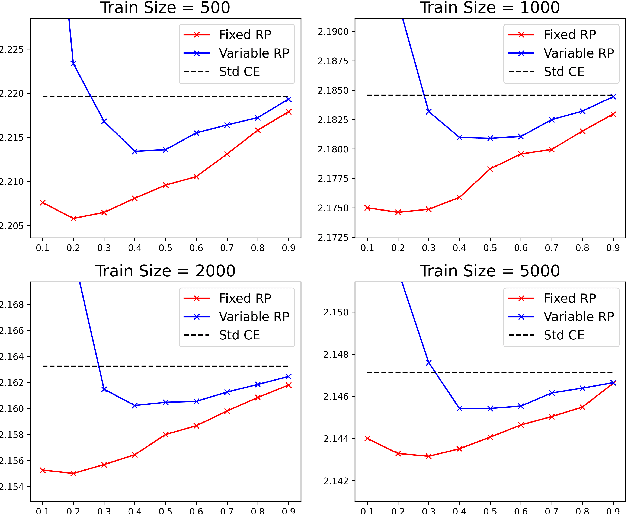
Cross-entropy loss is the standard metric used to train classification models in deep learning and gradient boosting. It is well-known that this loss function fails to account for similarities between the different values of the target. We propose a generalization of entropy called {\em structured entropy} which uses a random partition to incorporate the structure of the target variable in a manner which retains many theoretical properties of standard entropy. We show that a structured cross-entropy loss yields better results on several classification problems where the target variable has an a priori known structure. The approach is simple, flexible, easily computable, and does not rely on a hierarchically defined notion of structure.
StructureBoost: Efficient Gradient Boosting for Structured Categorical Variables
Jul 08, 2020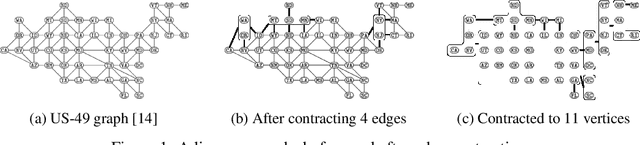
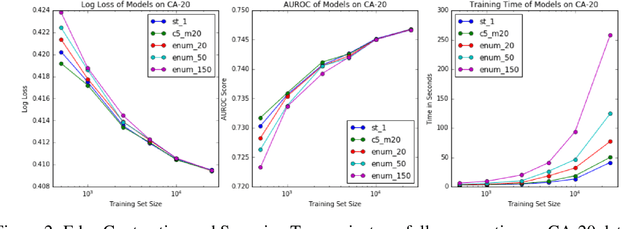
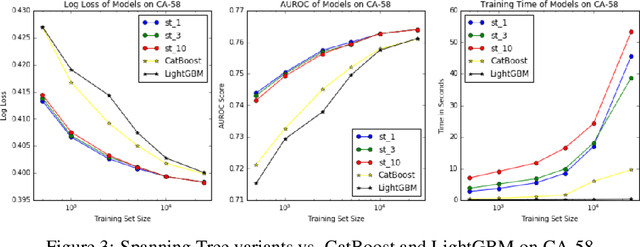
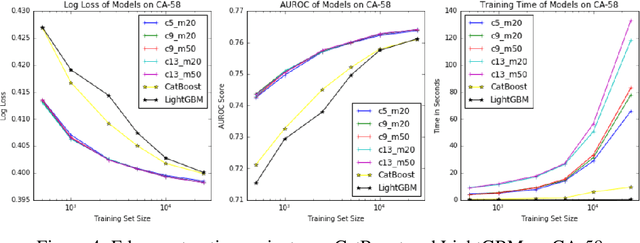
Gradient boosting methods based on Structured Categorical Decision Trees (SCDT) have been demonstrated to outperform numerical and one-hot-encodings on problems where the categorical variable has a known underlying structure. However, the enumeration procedure in the SCDT is infeasible except for categorical variables with low or moderate cardinality. We propose and implement two methods to overcome the computational obstacles and efficiently perform Gradient Boosting on complex structured categorical variables. The resulting package, called StructureBoost, is shown to outperform established packages such as CatBoost and LightGBM on problems with categorical predictors that contain sophisticated structure. Moreover, we demonstrate that StructureBoost can make accurate predictions on unseen categorical values due to its knowledge of the underlying structure.
Exploiting Categorical Structure Using Tree-Based Methods
Apr 15, 2020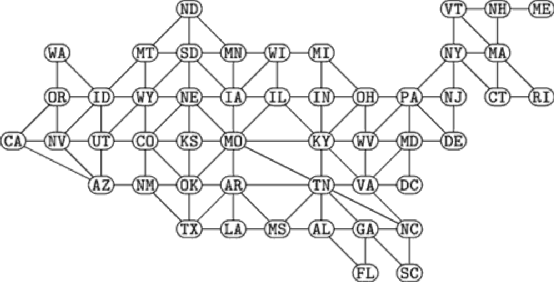
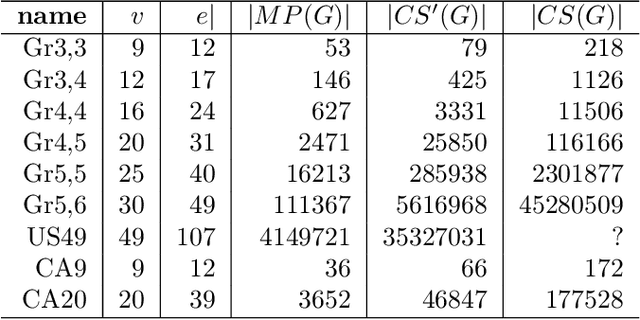
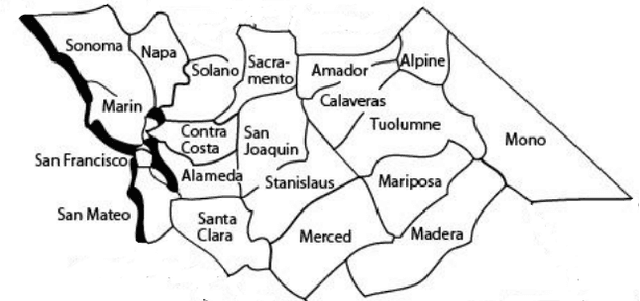
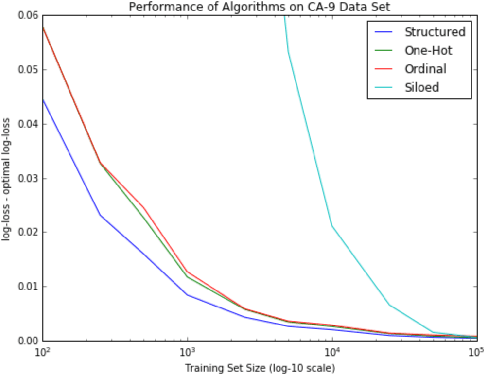
Standard methods of using categorical variables as predictors either endow them with an ordinal structure or assume they have no structure at all. However, categorical variables often possess structure that is more complicated than a linear ordering can capture. We develop a mathematical framework for representing the structure of categorical variables and show how to generalize decision trees to make use of this structure. This approach is applicable to methods such as Gradient Boosted Trees which use a decision tree as the underlying learner. We show results on weather data to demonstrate the improvement yielded by this approach.
Spline-Based Probability Calibration
Sep 20, 2018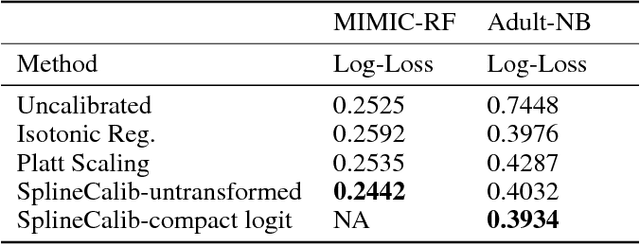
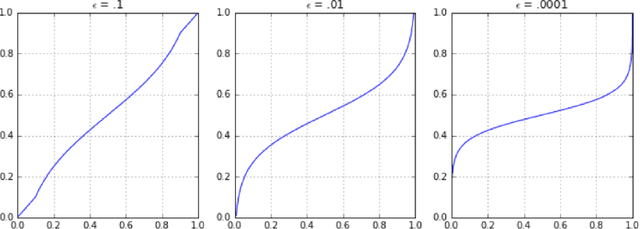
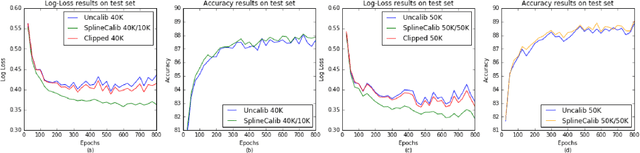
In many classification problems it is desirable to output well-calibrated probabilities on the different classes. We propose a robust, non-parametric method of calibrating probabilities called SplineCalib that utilizes smoothing splines to determine a calibration function. We demonstrate how applying certain transformations as part of the calibration process can improve performance on problems in deep learning and other domains where the scores tend to be "overconfident". We adapt the approach to multi-class problems and find that better calibration can improve accuracy as well as log-loss by better resolving uncertain cases. Finally, we present a cross-validated approach to calibration which conserves data. Significant improvements to log-loss and accuracy are shown on several different problems. We also introduce the ml-insights python package which contains an implementation of the SplineCalib algorithm.