 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBruce D. Lee
Active Learning for Control-Oriented Identification of Nonlinear Systems
Apr 13, 2024
Model-based reinforcement learning is an effective approach for controlling an unknown system. It is based on a longstanding pipeline familiar to the control community in which one performs experiments on the environment to collect a dataset, uses the resulting dataset to identify a model of the system, and finally performs control synthesis using the identified model. As interacting with the system may be costly and time consuming, targeted exploration is crucial for developing an effective control-oriented model with minimal experimentation. Motivated by this challenge, recent work has begun to study finite sample data requirements and sample efficient algorithms for the problem of optimal exploration in model-based reinforcement learning. However, existing theory and algorithms are limited to model classes which are linear in the parameters. Our work instead focuses on models with nonlinear parameter dependencies, and presents the first finite sample analysis of an active learning algorithm suitable for a general class of nonlinear dynamics. In certain settings, the excess control cost of our algorithm achieves the optimal rate, up to logarithmic factors. We validate our approach in simulation, showcasing the advantage of active, control-oriented exploration for controlling nonlinear systems.
Uncertainty-Aware Deployment of Pre-trained Language-Conditioned Imitation Learning Policies
Mar 27, 2024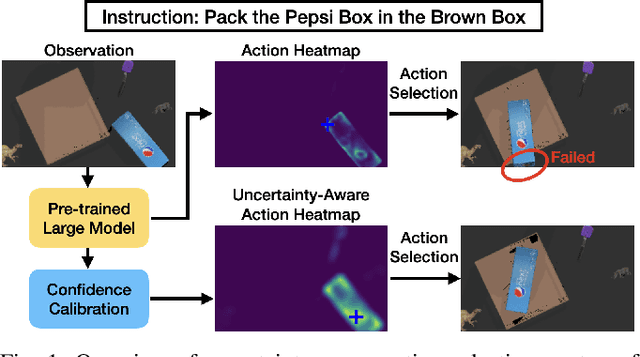

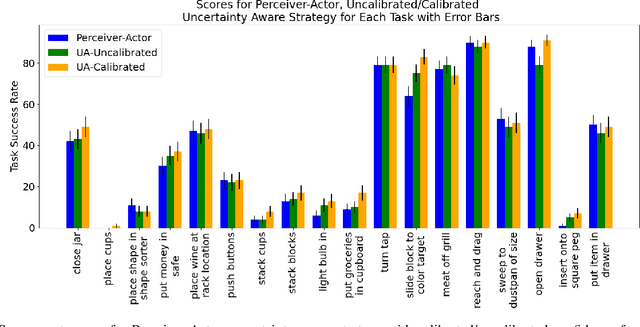

Large-scale robotic policies trained on data from diverse tasks and robotic platforms hold great promise for enabling general-purpose robots; however, reliable generalization to new environment conditions remains a major challenge. Toward addressing this challenge, we propose a novel approach for uncertainty-aware deployment of pre-trained language-conditioned imitation learning agents. Specifically, we use temperature scaling to calibrate these models and exploit the calibrated model to make uncertainty-aware decisions by aggregating the local information of candidate actions. We implement our approach in simulation using three such pre-trained models, and showcase its potential to significantly enhance task completion rates. The accompanying code is accessible at the link: https://github.com/BobWu1998/uncertainty_quant_all.git
Nonasymptotic Regret Analysis of Adaptive Linear Quadratic Control with Model Misspecification
Dec 29, 2023The strategy of pre-training a large model on a diverse dataset, then fine-tuning for a particular application has yielded impressive results in computer vision, natural language processing, and robotic control. This strategy has vast potential in adaptive control, where it is necessary to rapidly adapt to changing conditions with limited data. Toward concretely understanding the benefit of pre-training for adaptive control, we study the adaptive linear quadratic control problem in the setting where the learner has prior knowledge of a collection of basis matrices for the dynamics. This basis is misspecified in the sense that it cannot perfectly represent the dynamics of the underlying data generating process. We propose an algorithm that uses this prior knowledge, and prove upper bounds on the expected regret after $T$ interactions with the system. In the regime where $T$ is small, the upper bounds are dominated by a term scales with either $\texttt{poly}(\log T)$ or $\sqrt{T}$, depending on the prior knowledge available to the learner. When $T$ is large, the regret is dominated by a term that grows with $\delta T$, where $\delta$ quantifies the level of misspecification. This linear term arises due to the inability to perfectly estimate the underlying dynamics using the misspecified basis, and is therefore unavoidable unless the basis matrices are also adapted online. However, it only dominates for large $T$, after the sublinear terms arising due to the error in estimating the weights for the basis matrices become negligible. We provide simulations that validate our analysis. Our simulations also show that offline data from a collection of related systems can be used as part of a pre-training stage to estimate a misspecified dynamics basis, which is in turn used by our adaptive controller.
Multi-Task Imitation Learning for Linear Dynamical Systems
Dec 01, 2022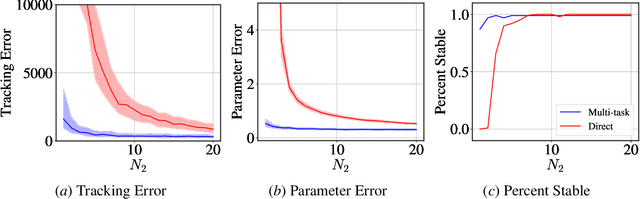
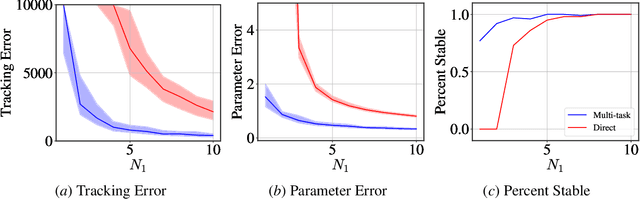
We study representation learning for efficient imitation learning over linear systems. In particular, we consider a setting where learning is split into two phases: (a) a pre-training step where a shared $k$-dimensional representation is learned from $H$ source policies, and (b) a target policy fine-tuning step where the learned representation is used to parameterize the policy class. We find that the imitation gap over trajectories generated by the learned target policy is bounded by $\tilde{O}\left( \frac{k n_x}{HN_{\mathrm{shared}}} + \frac{k n_u}{N_{\mathrm{target}}}\right)$, where $n_x > k$ is the state dimension, $n_u$ is the input dimension, $N_{\mathrm{shared}}$ denotes the total amount of data collected for each policy during representation learning, and $N_{\mathrm{target}}$ is the amount of target task data. This result formalizes the intuition that aggregating data across related tasks to learn a representation can significantly improve the sample efficiency of learning a target task. The trends suggested by this bound are corroborated in simulation.