 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBryan Chan
ACPO: AI-Enabled Compiler-Driven Program Optimization
Dec 15, 2023
The key to performance optimization of a program is to decide correctly when a certain transformation should be applied by a compiler. Traditionally, such profitability decisions are made by hand-coded algorithms tuned for a very small number of benchmarks, usually requiring a great deal of effort to be retuned when the benchmark suite changes. This is an ideal opportunity to apply machine-learning models to speed up the tuning process; while this realization has been around since the late 90s, only recent advancements in ML enabled a practical application of ML to compilers as an end-to-end framework. Even so, seamless integration of ML into the compiler would require constant rebuilding of the compiler when models are updated. This paper presents ACPO: \textbf{\underline{A}}I-Enabled \textbf{\underline{C}}ompiler-driven \textbf{\underline{P}}rogram \textbf{\underline{O}}ptimization; a novel framework to provide LLVM with simple and comprehensive tools to benefit from employing ML models for different optimization passes. We first showcase the high-level view, class hierarchy, and functionalities of ACPO and subsequently, demonstrate \taco{a couple of use cases of ACPO by ML-enabling the Loop Unroll and Function Inlining passes and describe how ACPO can be leveraged to optimize other passes. Experimental results reveal that ACPO model for Loop Unroll is able to gain on average 4\% and 3\%, 5.4\%, 0.2\% compared to LLVM's O3 optimization when deployed on Polybench, Coral-2, CoreMark, and Graph-500, respectively. Furthermore, by adding the Inliner model as well, ACPO is able to provide up to 4.5\% and 2.4\% on Polybench and Cbench compared with LLVM's O3 optimization, respectively.
A Statistical Guarantee for Representation Transfer in Multitask Imitation Learning
Nov 02, 2023Transferring representation for multitask imitation learning has the potential to provide improved sample efficiency on learning new tasks, when compared to learning from scratch. In this work, we provide a statistical guarantee indicating that we can indeed achieve improved sample efficiency on the target task when a representation is trained using sufficiently diverse source tasks. Our theoretical results can be readily extended to account for commonly used neural network architectures with realistic assumptions. We conduct empirical analyses that align with our theoretical findings on four simulated environments$\unicode{x2014}$in particular leveraging more data from source tasks can improve sample efficiency on learning in the new task.
Learning from Guided Play: Improving Exploration for Adversarial Imitation Learning with Simple Auxiliary Tasks
Dec 30, 2022

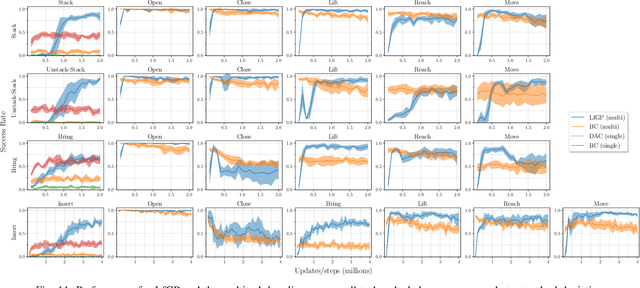
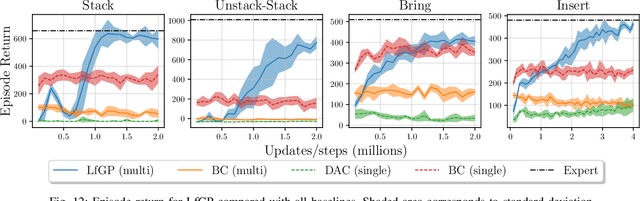
Adversarial imitation learning (AIL) has become a popular alternative to supervised imitation learning that reduces the distribution shift suffered by the latter. However, AIL requires effective exploration during an online reinforcement learning phase. In this work, we show that the standard, naive approach to exploration can manifest as a suboptimal local maximum if a policy learned with AIL sufficiently matches the expert distribution without fully learning the desired task. This can be particularly catastrophic for manipulation tasks, where the difference between an expert and a non-expert state-action pair is often subtle. We present Learning from Guided Play (LfGP), a framework in which we leverage expert demonstrations of multiple exploratory, auxiliary tasks in addition to a main task. The addition of these auxiliary tasks forces the agent to explore states and actions that standard AIL may learn to ignore. Additionally, this particular formulation allows for the reusability of expert data between main tasks. Our experimental results in a challenging multitask robotic manipulation domain indicate that LfGP significantly outperforms both AIL and behaviour cloning, while also being more expert sample efficient than these baselines. To explain this performance gap, we provide further analysis of a toy problem that highlights the coupling between a local maximum and poor exploration, and also visualize the differences between the learned models from AIL and LfGP.
MLGOPerf: An ML Guided Inliner to Optimize Performance
Jul 19, 2022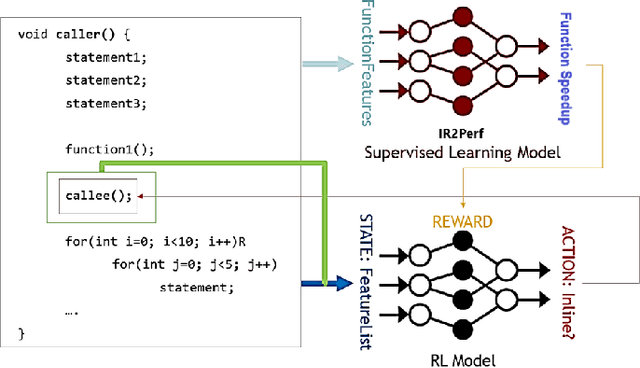
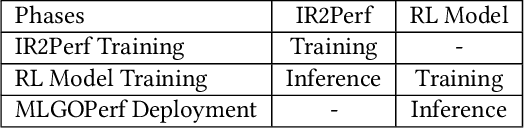

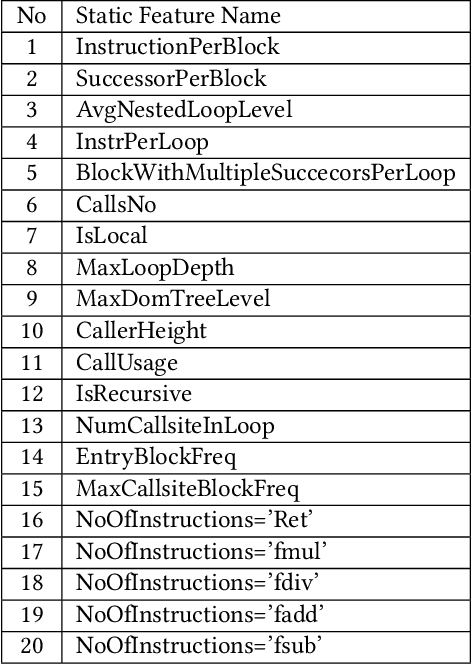
For the past 25 years, we have witnessed an extensive application of Machine Learning to the Compiler space; the selection and the phase-ordering problem. However, limited works have been upstreamed into the state-of-the-art compilers, i.e., LLVM, to seamlessly integrate the former into the optimization pipeline of a compiler to be readily deployed by the user. MLGO was among the first of such projects and it only strives to reduce the code size of a binary with an ML-based Inliner using Reinforcement Learning. This paper presents MLGOPerf; the first end-to-end framework capable of optimizing performance using LLVM's ML-Inliner. It employs a secondary ML model to generate rewards used for training a retargeted Reinforcement learning agent, previously used as the primary model by MLGO. It does so by predicting the post-inlining speedup of a function under analysis and it enables a fast training framework for the primary model which otherwise wouldn't be practical. The experimental results show MLGOPerf is able to gain up to 1.8% and 2.2% with respect to LLVM's optimization at O3 when trained for performance on SPEC CPU2006 and Cbench benchmarks, respectively. Furthermore, the proposed approach provides up to 26% increased opportunities to autotune code regions for our benchmarks which can be translated into an additional 3.7% speedup value.
Learning from Guided Play: A Scheduled Hierarchical Approach for Improving Exploration in Adversarial Imitation Learning
Dec 16, 2021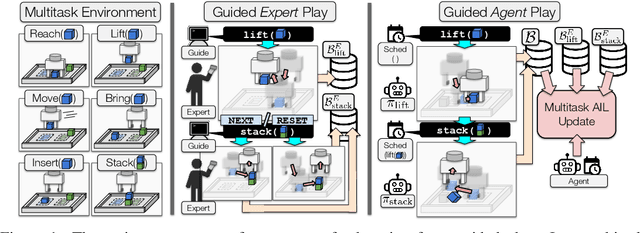


Effective exploration continues to be a significant challenge that prevents the deployment of reinforcement learning for many physical systems. This is particularly true for systems with continuous and high-dimensional state and action spaces, such as robotic manipulators. The challenge is accentuated in the sparse rewards setting, where the low-level state information required for the design of dense rewards is unavailable. Adversarial imitation learning (AIL) can partially overcome this barrier by leveraging expert-generated demonstrations of optimal behaviour and providing, essentially, a replacement for dense reward information. Unfortunately, the availability of expert demonstrations does not necessarily improve an agent's capability to explore effectively and, as we empirically show, can lead to inefficient or stagnated learning. We present Learning from Guided Play (LfGP), a framework in which we leverage expert demonstrations of, in addition to a main task, multiple auxiliary tasks. Subsequently, a hierarchical model is used to learn each task reward and policy through a modified AIL procedure, in which exploration of all tasks is enforced via a scheduler composing different tasks together. This affords many benefits: learning efficiency is improved for main tasks with challenging bottleneck transitions, expert data becomes reusable between tasks, and transfer learning through the reuse of learned auxiliary task models becomes possible. Our experimental results in a challenging multitask robotic manipulation domain indicate that our method compares favourably to supervised imitation learning and to a state-of-the-art AIL method. Code is available at https://github.com/utiasSTARS/lfgp.
Heteroscedastic Uncertainty for Robust Generative Latent Dynamics
Aug 18, 2020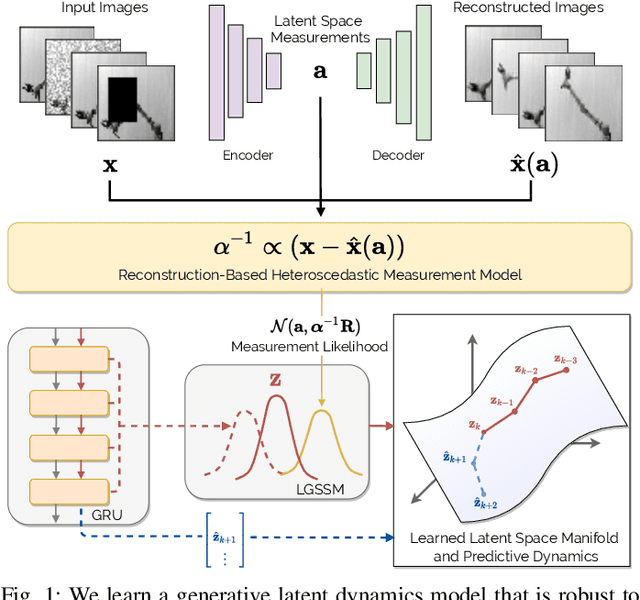
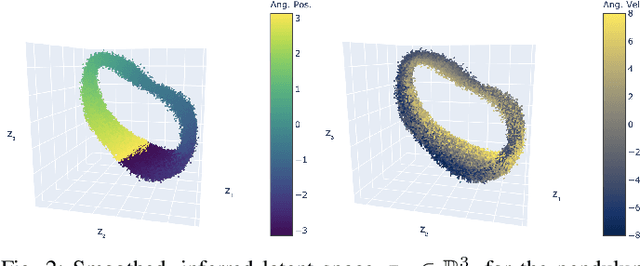
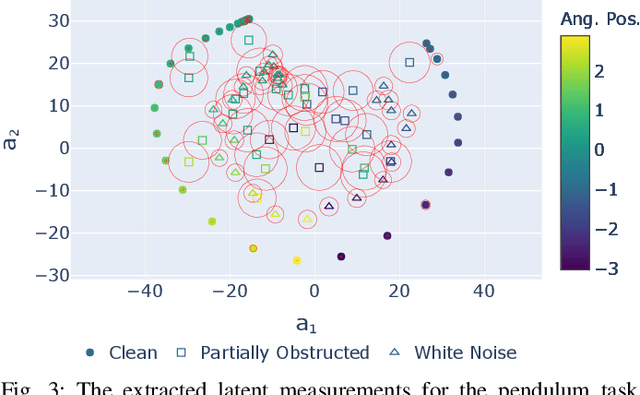
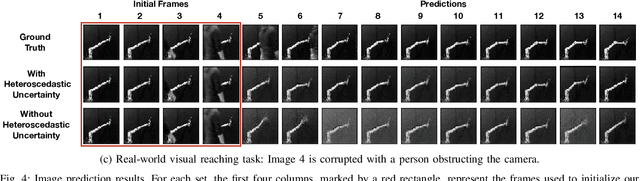
Learning or identifying dynamics from a sequence of high-dimensional observations is a difficult challenge in many domains, including reinforcement learning and control. The problem has recently been studied from a generative perspective through latent dynamics: high-dimensional observations are embedded into a lower-dimensional space in which the dynamics can be learned. Despite some successes, latent dynamics models have not yet been applied to real-world robotic systems where learned representations must be robust to a variety of perceptual confounds and noise sources not seen during training. In this paper, we present a method to jointly learn a latent state representation and the associated dynamics that is amenable for long-term planning and closed-loop control under perceptually difficult conditions. As our main contribution, we describe how our representation is able to capture a notion of heteroscedastic or input-specific uncertainty at test time by detecting novel or out-of-distribution (OOD) inputs. We present results from prediction and control experiments on two image-based tasks: a simulated pendulum balancing task and a real-world robotic manipulator reaching task. We demonstrate that our model produces significantly more accurate predictions and exhibits improved control performance, compared to a model that assumes homoscedastic uncertainty only, in the presence of varying degrees of input degradation.
Satellite Navigation for the Age of Autonomy
May 19, 2020


Global Navigation Satellite Systems (GNSS) brought navigation to the masses. Coupled with smartphones, the blue dot in the palm of our hands has forever changed the way we interact with the world. Looking forward, cyber-physical systems such as self-driving cars and aerial mobility are pushing the limits of what localization technologies including GNSS can provide. This autonomous revolution requires a solution that supports safety-critical operation, centimeter positioning, and cyber-security for millions of users. To meet these demands, we propose a navigation service from Low Earth Orbiting (LEO) satellites which deliver precision in-part through faster motion, higher power signals for added robustness to interference, constellation autonomous integrity monitoring for integrity, and encryption / authentication for resistance to spoofing attacks. This paradigm is enabled by the 'New Space' movement, where highly capable satellites and components are now built on assembly lines and launch costs have decreased by more than tenfold. Such a ubiquitous positioning service enables a consistent and secure standard where trustworthy information can be validated and shared, extending the electronic horizon from sensor line of sight to an entire city. This enables the situational awareness needed for true safe operation to support autonomy at scale.
* 11 pages, 8 figures, 2020 IEEE/ION Position, Location and Navigation Symposium (PLANS)