 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeByoung Chul Ko
Semantic Scene Graph Generation Based on an Edge Dual Scene Graph and Message Passing Neural Network
Nov 02, 2023
Along with generative AI, interest in scene graph generation (SGG), which comprehensively captures the relationships and interactions between objects in an image and creates a structured graph-based representation, has significantly increased in recent years. However, relying on object-centric and dichotomous relationships, existing SGG methods have a limited ability to accurately predict detailed relationships. To solve these problems, a new approach to the modeling multiobject relationships, called edge dual scene graph generation (EdgeSGG), is proposed herein. EdgeSGG is based on a edge dual scene graph and Dual Message Passing Neural Network (DualMPNN), which can capture rich contextual interactions between unconstrained objects. To facilitate the learning of edge dual scene graphs with a symmetric graph structure, the proposed DualMPNN learns both object- and relation-centric features for more accurately predicting relation-aware contexts and allows fine-grained relational updates between objects. A comparative experiment with state-of-the-art (SoTA) methods was conducted using two public datasets for SGG operations and six metrics for three subtasks. Compared with SoTA approaches, the proposed model exhibited substantial performance improvements across all SGG subtasks. Furthermore, experiment on long-tail distributions revealed that incorporating the relationships between objects effectively mitigates existing long-tail problems.
Cross-Modal Learning with 3D Deformable Attention for Action Recognition
Dec 12, 2022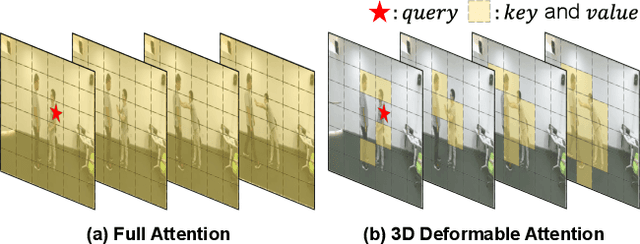
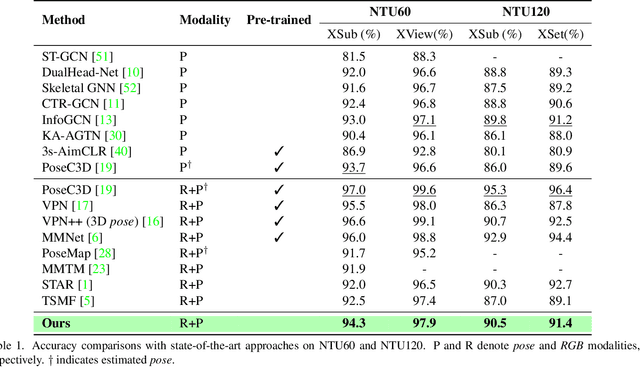
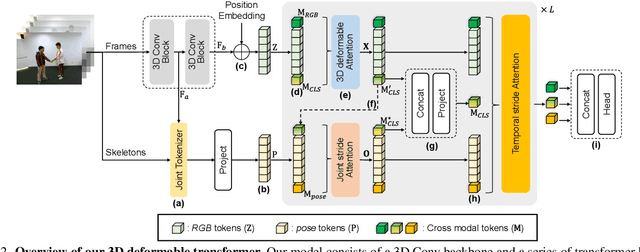

An important challenge in vision-based action recognition is the embedding of spatiotemporal features with two or more heterogeneous modalities into a single feature. In this study, we propose a new 3D deformable transformer for action recognition with adaptive spatiotemporal receptive fields and a cross-modal learning scheme. The 3D deformable transformer consists of three attention modules: 3D deformability, local joint stride, and temporal stride attention. The two cross-modal tokens are input into the 3D deformable attention module to create a cross-attention token with a reflected spatiotemporal correlation. Local joint stride attention is applied to spatially combine attention and pose tokens. Temporal stride attention temporally reduces the number of input tokens in the attention module and supports temporal expression learning without the simultaneous use of all tokens. The deformable transformer iterates L times and combines the last cross-modal token for classification. The proposed 3D deformable transformer was tested on the NTU60, NTU120, FineGYM, and Penn Action datasets, and showed results better than or similar to pre-trained state-of-the-art methods even without a pre-training process. In addition, by visualizing important joints and correlations during action recognition through spatial joint and temporal stride attention, the possibility of achieving an explainable potential for action recognition is presented.
STAR-Transformer: A Spatio-temporal Cross Attention Transformer for Human Action Recognition
Oct 14, 2022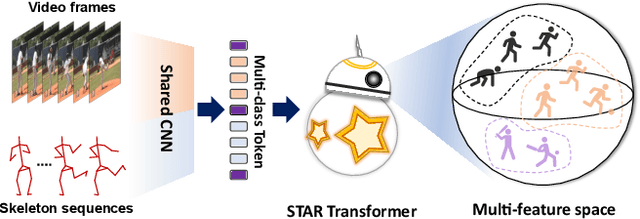



In action recognition, although the combination of spatio-temporal videos and skeleton features can improve the recognition performance, a separate model and balancing feature representation for cross-modal data are required. To solve these problems, we propose Spatio-TemporAl cRoss (STAR)-transformer, which can effectively represent two cross-modal features as a recognizable vector. First, from the input video and skeleton sequence, video frames are output as global grid tokens and skeletons are output as joint map tokens, respectively. These tokens are then aggregated into multi-class tokens and input into STAR-transformer. The STAR-transformer encoder layer consists of a full self-attention (FAttn) module and a proposed zigzag spatio-temporal attention (ZAttn) module. Similarly, the continuous decoder consists of a FAttn module and a proposed binary spatio-temporal attention (BAttn) module. STAR-transformer learns an efficient multi-feature representation of the spatio-temporal features by properly arranging pairings of the FAttn, ZAttn, and BAttn modules. Experimental results on the Penn-Action, NTU RGB+D 60, and 120 datasets show that the proposed method achieves a promising improvement in performance in comparison to previous state-of-the-art methods.
Interpretation and Simplification of Deep Forest
Feb 18, 2020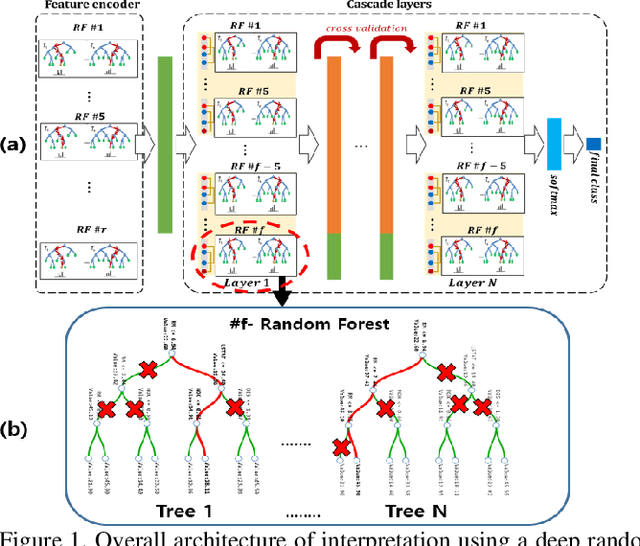
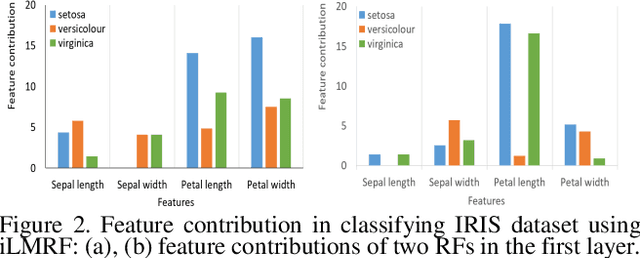
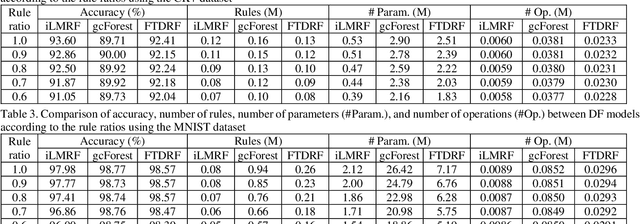
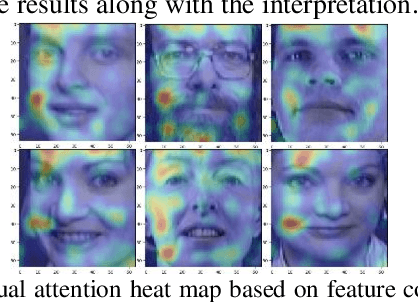
This paper proposes a new method for interpreting and simplifying a black box model of a deep random forest (RF) using a proposed rule elimination. In deep RF, a large number of decision trees are connected to multiple layers, thereby making an analysis difficult. It has a high performance similar to that of a deep neural network (DNN), but achieves a better generalizability. Therefore, in this study, we consider quantifying the feature contributions and frequency of the fully trained deep RF in the form of a decision rule set. The feature contributions provide a basis for determining how features affect the decision process in a rule set. Model simplification is achieved by eliminating unnecessary rules by measuring the feature contributions. Consequently, the simplified model has fewer parameters and rules than before. Experiment results have shown that a feature contribution analysis allows a black box model to be decomposed for quantitatively interpreting a rule set. The proposed method was successfully applied to various deep RF models and benchmark datasets while maintaining a robust performance despite the elimination of a large number of rules.